网络攻防技术——哈希碰撞
实验3:MD5碰撞试验
本次实验主要是加深大家对MD5碰撞及其原理的理解,使用SEED实验环境中的工具及编程语言,完成以下任务:
-
使用md5collgen生成两个MD5值相同的文件,并利用bless十六进制编辑器查看输出的两个文件,描述你观察到的情况;
-
参考Lab3_task2.c的代码,生成两个MD5值相同但输出不同的两个可执行文件。
-
参考Lab3_task3.c的代码,生成两个MD5值相同但代码行为不相同的可执行文件。
-
回答问题:通过上面的实验,请解释为什么可以做到不同行为的两个可执行文件具有相同的MD5值?
-
lab1
该实验的基础是:根据相同的前缀,可以生成两个文件,这两个文件的前缀相同,但后面却不同,同时具有相同的哈希值,即产生了哈希碰撞

下面进行演示,新建并写入文字到prifix.txt

使用md5collgen工具创建出两个产生碰撞的文件
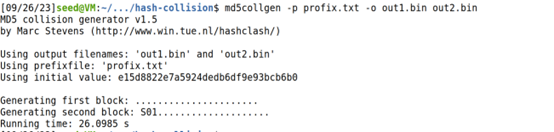
使用diff命令发现两个文件不同,但却产生了相同的哈希值,成功产生碰撞

-
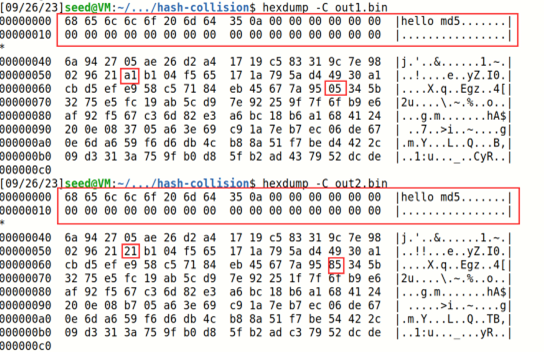
Q1:观察发现如果给出的前缀不足64,即在md5计算中无法构成一个完整的运算块,md5会进行补0填充
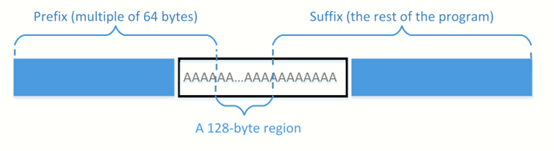
注:hexdump命令可以将二进制文件以十六进制的形式显示出来,同时这个工具生成的内容的长度是128字节
`hexdump -C <fileName>`
-
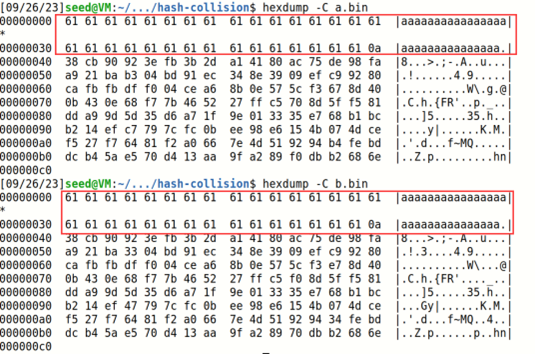
Q2:我们给一个正好等于64字节大小的前缀文件,再进行哈希碰撞,发现没有补0,正好构成了一个运算块
-
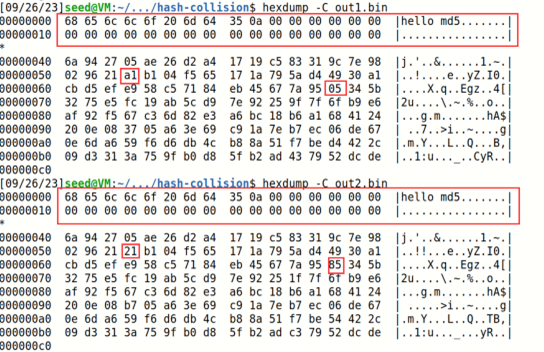
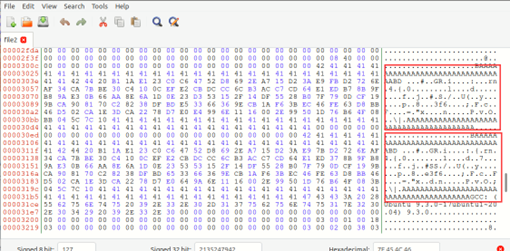
Q3:通过观察我们发现只有很少的一部分字节发生了改变,这样才使得算出的哈希值有可能相同,不同的字节在下图用红框框出
-
-
lab2
MD5算法原理:
MD5将输入数据划分为64字节的块,然后在这些块上迭代计算哈希。MD5算法的核心是一个压缩函数,它接受两个输入,一个64字节的数据块和上一次迭代的结果。压缩函数产生一个128位的IHV,代表"中间散列V值";然后将该输出发送到下一次迭代中。如果当前迭代是最后一次迭代,则IHV将是最终的哈希值

于是可以推出,给定两个输入M和N,如果MD5(M)=MD5(N),,则对于任何输入T,MD5(M||T)=MD5(N||T),因为M和N产生的IHV一样,这是前面的数据唯一影响最终哈希值的部分,是一样的
向上面生成的两个产生哈希碰撞的文件分别追加相同的字符串"task2",然后再计算哈希值,发现哈希值相同,验证了相同哈希的字符加上相同一段字符后,两者的哈希值依然相同

-
lab3
目前验证软件是否正版或者是否被篡改的方法就是校验两个文件的哈希是否相同,如果可以纂改一个软件后哈希值不变,就可以逃过检验
可以将程序分成下面三个部分,prefix生成128字节后,哈希值相同,再加上相同的后缀后依然相同
编写好要用到的程序,程序内容为定义一个长度为200的字符数组,然后通过for循环将该字符数组打印出来

查看文件的二进制形式,发现数组位于0x3020+1处,于是将之前的内容取出作为产生哈希碰撞的前缀


观察产生的前缀文件profix,发现截取正确,于是使用md5collgen产生两个碰撞的文件
因为0x3020不是64的倍数,所以在计算碰撞时会补32个0,计算后缀时要记得减去

文件原长度减去产生碰撞的前缀的长度,再减去产生的128字节,得到需要截取的后缀的长度(0x4258-0x3020-128-32=4504),因为我们要保证改动前后文件的总长度不变,还要保证改动部分不会超过数组空间,防止破坏程序结构和功能,尽量数组空间选大一些,所以这里选的是200
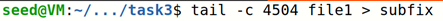
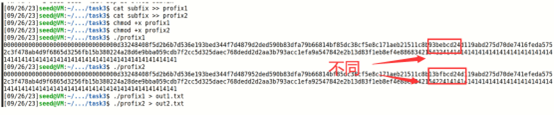
将前后缀拼接在一起,得到两个二进制文件,分别执行两个二进制文件,发现输出结果不同,但有相同的哈希

-
lab4
上面构造的程序只是将数组输出的内容变了,我们需要更加恶意的行为,我们当然可以直接将良性代码改成恶意代码,但这样构造哈希碰撞比较困难,所以依然采用上面的思想,定义两个字符数组,并比较两个数组,如果相等则执行恶意代码部分,如果不相等则执行良好代码部分(虽然这种恶意代码过不了恶意代码检测系统的审核,但毕竟只是个实验)
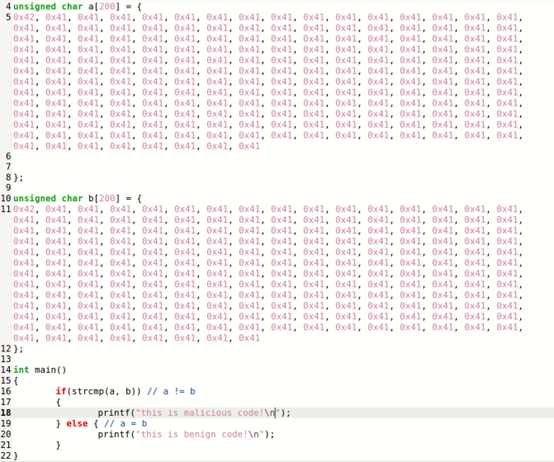
编译该文件得到二进制文件,复制两份(file1和file2),分别作为良好程序和恶意程序以对比

通过观察发现第一个数组在0x3020(十进制的12320)处开始,上面的任务我们默认使用了碰撞的补零机制,但是strcmp函数遇到00会停止比较(00截断,00是C语言中的字符串终止符),所以选择0x3040作为开始,取一个能被64整除的前缀

生成两个前缀文件
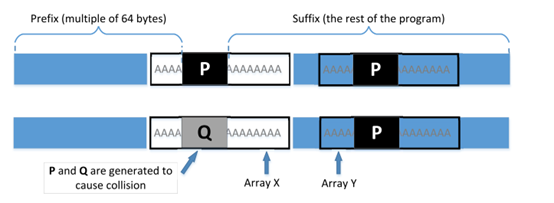
profix1生成的128位字节是P部分, profix2生成的128位字节是Q部分。将P部分替换file1的第二个数组和file2的两个数组对应128字节的位置;将Q部分替换file1的第一个数组对应的部分,达到的效果如下图所示:
为方便,这里我们就选择在图形化界面直接覆盖:
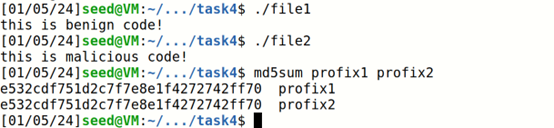
分别运行file1和file2,结果如下:
-
结果分析
由于哈希函数的特性,产生碰撞是不可避免的,通过一些已有的工具可以快速算出能发生碰撞的两个值,并且如果将两个值加上相同的一部分,再进行哈希计算,得到的哈希值依然相同,这就给了我们可以去构造恶意程序的空间,现在我们有两个程序,而我们只修改一小部分就会有完全不同的效果,我们就可以将这两个可执行文件的相同前缀取出,然后把生成的碰撞哈希加到后面,这两个碰撞哈希只有微小的不同,我们将其放在变量的位置,这样不会影响程序的结构,那么我们可以通过修改程序的的变量值,达到相同哈希但结果不同的程序,也可以构造出巧妙的函数结构(如task4中),当然也可以选择构造其他的结构,以达到相同哈希但程序行为不同的效果,通过这种方法我们可以绕过哈希检查,这说明md5哈希算法存在着很大的漏洞,用md5哈希值去证明程序的抗抵赖性和恶意程序检测是有风险的
本文来自博客园,作者:Leo1017,转载请注明原文链接:https://www.cnblogs.com/leo1017/p/17947665



