
爬虫综合大作业
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/3159
1.对网易云歌词的爬取并做成词云
经常使用网易云音乐听歌,特别喜欢网易云的年度听歌报告。所以生活终于对这小猫咪下手了。
(1) 分析歌手首页HTML,找出入口api
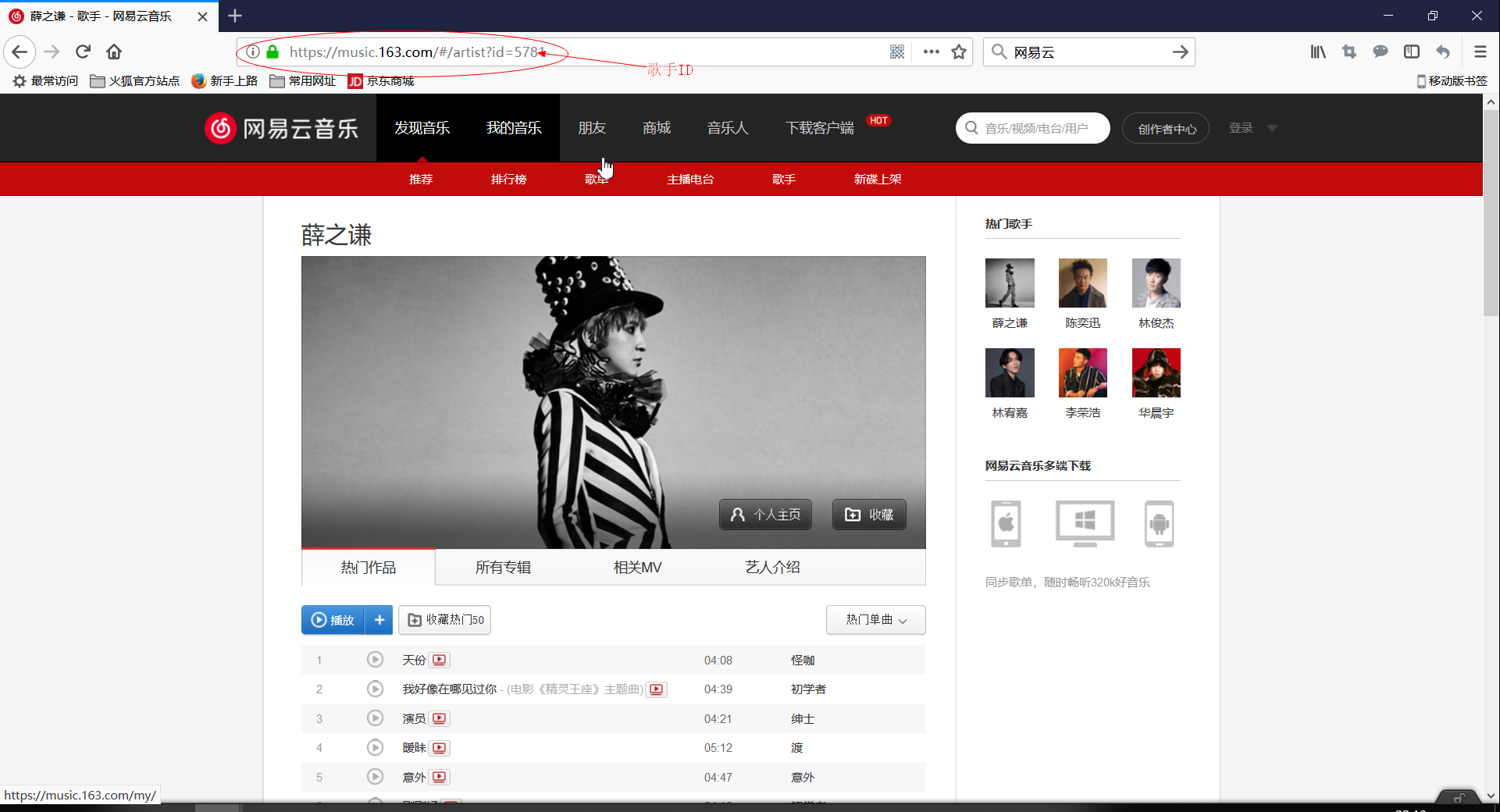
观察URL可以发现每一个歌手都有一个特定的id,测试后发现中间的“#”是没用的,所以说'http://music.163.com/artist?id=歌手ID'这才是正确的URL,接着通过开发者工具发现每一首歌都有对应的ID。我们理一下思路,首先要有歌手ID,接着就可以通过爬下来的text取出每一首歌的ID
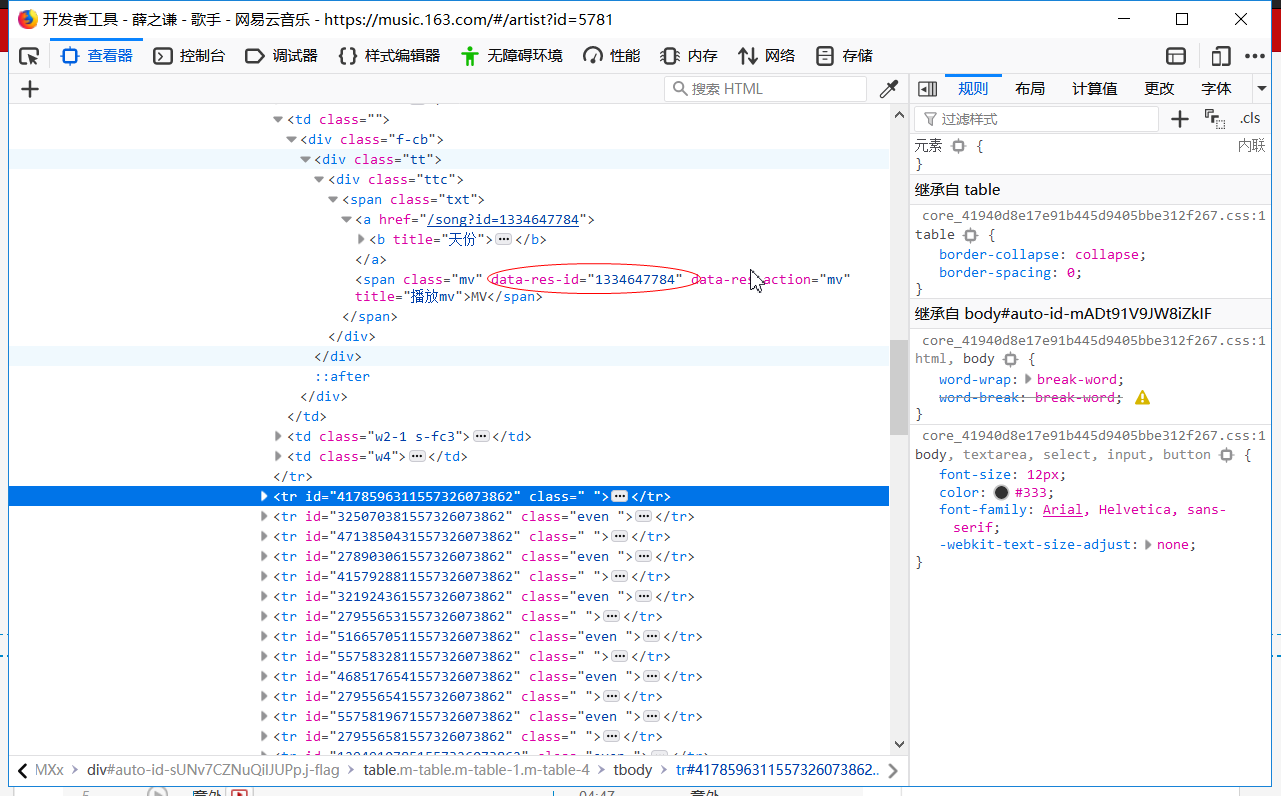
(2) 分析歌曲HTML,找出api
歌词,肯定是动态的,所以说我们F12抓包,在异步XHR发现其中一个就是歌词的api,但是他需要两个参数(params,encSecKey),看到一大串的字符就知道是加密了,哎!这大概就是网易云开发者大牛们茶余饭后想到的加密吧。经过几番波折,找到这样一个'http://music.163.com/api/song/lyric?' + 'id=' + str(music_id)+ '&lv=1&kv=1&tv=-1'就可以解决加密问题,其原理我就不懂了,毕竟还是个菜鸟!


(3) 爬下歌词做成词云
用wordcloud 把歌词做成词云#from wordcloud import WordCloud
注:最好使用代理ip,我的ip已经给网易云禁了,哭晕o(╥﹏╥)o
部分代码如下:
def get_song_id(singer_id): singer_url = 'http://music.163.com/artist?id=' + str(singer_id) r = requests.get(singer_url, headers=HEADERS).text soup = BeautifulSoup(r, 'lxml') song_ids = soup.find('textarea').text song_josn = json.loads(song_ids) for item in song_josn: lrc = get_all_lyrics(item['id']) write_to_file(lrc, item['name'], item['id']) def get_all_lyrics(music_id): url = 'http://music.163.com/api/song/lyric?' + 'id=' + str(music_id)+ '&lv=1&kv=1&tv=-1' r = requests.get(url, headers=HEADERS) json_obj = r.text try: j = json.loads(json_obj) lrc = j['lrc']['lyric'] pat = re.compile(r'\[.*\]') lrc = re.sub(pat, "", lrc) lrc = lrc.strip() except Exception: print('未获取歌词,music_id' + str(music_id)) lrc = '' finally: return lrc
def generate_word_cloud(word_freq_dict): print('开始生成词云...') background_image = imread(BG_IMAGE_PATH) # 设置背景图片 wc = WordCloud(font_path=FONT_PATH, # 设置字体 background_color="white", # 背景颜色 max_words=2000, # 词云显示的最大词数 mask=background_image, # 设置背景图片 max_font_size=100, # 字体最大值 random_state=42, width=1000, height=860, margin=2, # 设置图片默认的大小,但是如果使用背景图片的话,那么保存的图片大小将会按照其大小保存,margin为词语边缘距离 ) wc.generate_from_frequencies(word_freq_dict)
以薛之谦的top50歌为例,词云展示:

3.爬取网易云歌曲的评论
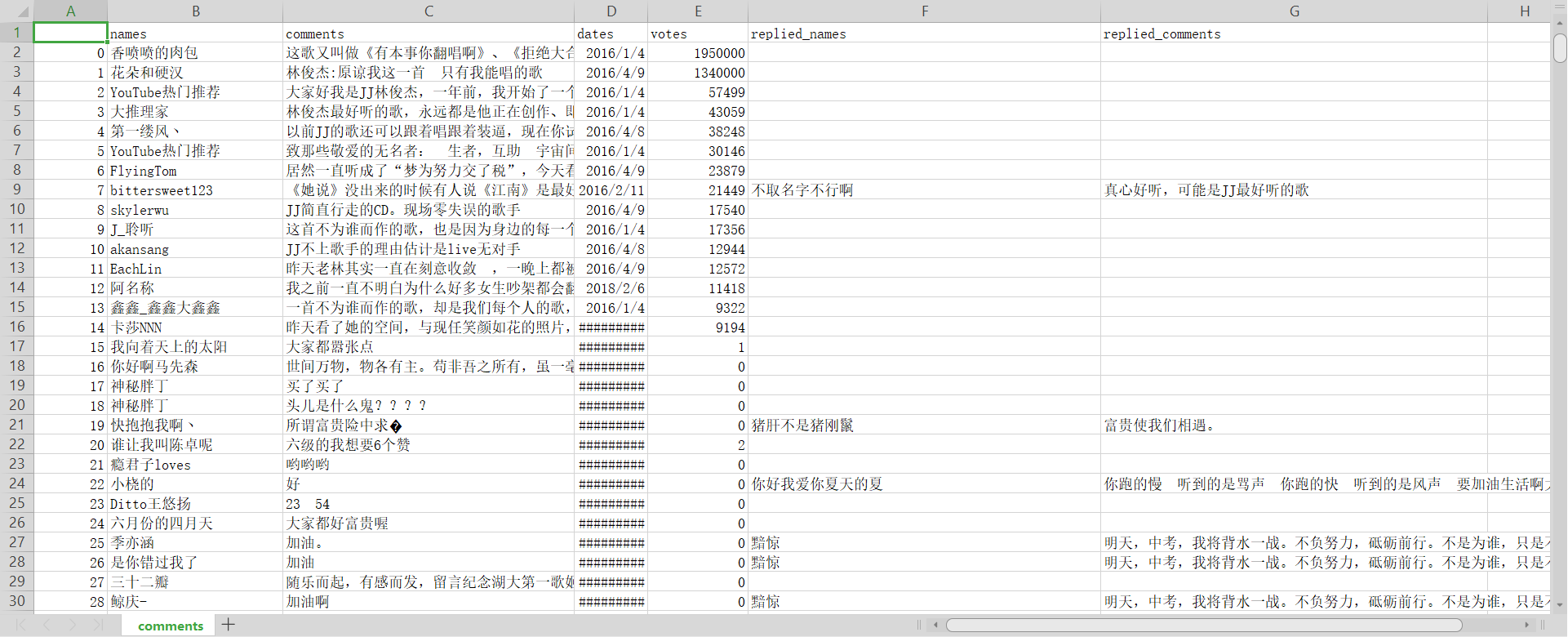
同样是通过歌曲的id,我爬取的是林俊杰的《不为谁而作的歌》,其中评论有2400多页,总数接近5w条,我只爬取了200页,4000多条评论如下:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号