理解爬虫原理
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2881
1. 简单说明爬虫原理
(1)发起请求:通过HTTP库向目标站点发起请求,即发送一个Request,请求可以包含额外的headers等信息,等待服务器响应。
(2)获取响应内容:如果服务器能正常响应,会得到一个Response,Response的内容便是所要获取的页面内容,类型可能有HTML,Json字符串,二进制数据(如图片视频)等类型。
(3)解析内容:得到的内容可能是HTML,可以用正则表达式、网页解析库进行解析。可能是Json,可以直接转为Json对象解析,可能是二进制数据,可以做保存或者进一步的处理。
(4)保存数据:保存形式多样,可以存为文本,也可以保存至数据库,或者保存特定格式的文件
2. 理解爬虫开发过程
1).简要说明浏览器工作原理;
URL解析/DNS解析查找域名IP地址,网络连接发起HTTP请求,HTTP报文传输过程,服务器接收数据,服务器响应请求/MVC,服务器返回数据,客户端接收数据,浏览器加载/渲染页面,打印绘制输出所看到的网页。
2).使用 requests 库抓取网站数据;
requests.get(url) 获取校园新闻首页html代码
import requests Newsurl='http://news.gzcc.cn/html/xiaoyuanxinwen/' News= requests.get(Newsurl) News.encoding='utf-8' print(News.text)

3).了解网页
写一个简单的html文件,包含多个标签,类,id
4).使用 Beautiful Soup 解析网页;
通过BeautifulSoup(html_sample,'html.parser')把上述html文件解析成DOM Tree
select(选择器)定位数据
找出含有特定标签的html元素
找出含有特定类名的html元素
找出含有特定id名的html元素
import bs4 from bs4 import BeautifulSoup html = '<html><body><h1 id="title">Hello</h1><a href="#" class="link"> This is link1</a><a href="# link2" class="link" qao=123> This is link2</a></body></html>' soup=BeautifulSoup(html,'html.parser') print(soup.select('a')) #特定标签的html元素 print(soup.select('.link')) #特定类名的html元素 print(soup.select('#title')) #特定id名的html元素

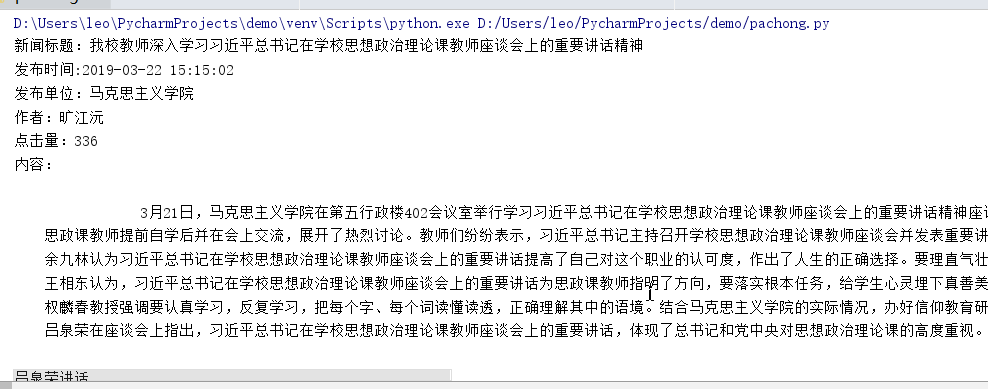
3.提取一篇校园新闻的标题、发布时间、发布单位、作者、点击次数、内容等信息
如url = 'http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html'
要求发布时间为datetime类型,点击次数为数值型,其它是字符串类型。
代码如下:
import requests
import bs4
from bs4 import BeautifulSoup
from datetime import datetime
NewsUrl="http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0322/11047.html"
NewGzcc = requests.get(NewsUrl)
NewGzcc.encoding='utf-8'
BSoup = BeautifulSoup(NewGzcc.text,'html.parser')
title = BSoup.select('.show-title')[0].text #标题
date = BSoup.select('.show-info')[0].text.split()[0].split(':')[1] #发布时间
date = date+' '+BSoup.select('.show-info')[0].text.split()[1]
#datetime类型
datetimes=datetime.strptime(date,"%Y-%m-%d %H:%M:%S")
unit = BSoup.select('.show-info')[0].text.split()[4].split(':')[1] #发布单位
author = BSoup.select('.show-info')[0].text.split()[2].split(':')[1] #发布作者
clickUrl= 'http://oa.gzcc.cn/api.php?op=count&id=11047&modelid=80'
clickRes = requests.get(clickUrl)
clickTimes = int(clickRes.text.split('.html')[-1].split("'")[1]) #点击量
content = BSoup.select('.show-content')[0].text #内容
print('新闻标题:'+title)
print("发布时间:",end='')
print(datetimes)
print('发布单位:'+unit)
print('作者:'+author)
print('点击量:'+format(clickTimes))
print('内容:'+content)
运行结果: