
中文词频统计与词云生成
作业来源:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE1/homework/2822
中文词频统计
1. 下载一长篇中文小说。
2. 从文件读取待分析文本。
3. 安装并使用jieba进行中文分词。
pip install jieba
import jieba
jieba.lcut(text)
4. 更新词库,加入所分析对象的专业词汇。
jieba.add_word('天罡北斗阵') #逐个添加
jieba.load_userdict(word_dict) #词库文本文件
参考词库下载地址:https://pinyin.sogou.com/dict/
转换代码:scel_to_text
5. 生成词频统计
6. 排序
7. 排除语法型词汇,代词、冠词、连词等停用词。
stops
tokens=[token for token in wordsls if token not in stops]
8. 输出词频最大TOP20,把结果存放到文件里
9. 生成词云。
代码如下:
1 import jieba 2 def read_file(): 3 f = open('C:\\Users\\leo\\Desktop\\我当阴阳先生的那几年.txt', 'r', encoding='utf-8') 4 content = f.read() #通过文件读取字符串 str 5 f.close() 6 return content 7 def read_stops(): 8 f = open('C:\\Users\\leo\\Desktop\\stops_chinese.txt', 'r', encoding='utf-8') 9 content = f.read() #通过文件读取字符串 str 10 f.close() 11 return content 12 text = read_file() 13 stops = read_stops().split() 14 #添加不切割的词 15 jieba.add_word('三清书') 16 jieba.add_word('崔作非') 17 jieba.add_word('福泽堂') 18 #分割 19 words = jieba.lcut(text) 20 #除掉stops 21 tokens = [token for token in words if token not in stops] 22 wcdict = {} 23 """统计次数并排序""" 24 for word in tokens: 25 if len(word)==1: 26 continue 27 else: 28 wcdict[word] = wcdict.get(word,0)+1 29 wcls = list(wcdict.items()) 30 wcls.sort(key=lambda x:x[1],reverse=True) 31 for i in range(20): 32 print(wcls[i]) 33 cut_text = " ".join(tokens) 34 """生成词云""" 35 from wordcloud import WordCloud 36 ciyun = WordCloud().generate(cut_text) 37 import matplotlib.pyplot as plt 38 plt.imshow(ciyun) 39 plt.axis("off") 40 plt.show() 41 ciyun.to_file(r'D:\搜狗高速下载\wordCloud.jpg')
词频统计截图:

词云展示:

主要问题:pycharm安装第三方库不成功,目测是pip的版本太低,大概就是版本问题,第三方的库都安装不了
解决方法:1.通过命令行安装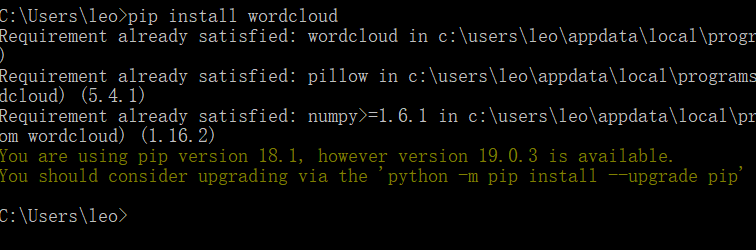
2.下载压缩包并解压到放置package的路径


 浙公网安备 33010602011771号
浙公网安备 33010602011771号