

(四)Spark之Local运行环境搭建
环境准备:
-
OS环境:CentOS 7(本示例运行环境)
-
JVM运行环境:JKD1.8
安装参考文章:https://blog.csdn.net/qq_32786873/article/details/78749384?utm_medium=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-3.control&depth_1-utm_source=distribute.pc_relevant.none-task-blog-BlogCommendFromBaidu-3.control -
spark安装包:spark-2.1.1-bin-hadoop2.7.tgz
链接:https://pan.baidu.com/s/1oqzdONO_iaiaN8DaEnFK2A
提取码:6d8a
-
安装包放置目录:/opt/software/
-
Spark工作目录:/opt/module/
安装步骤
- 解压 Spark 安装包,把安装包上传到/opt/software/下, 并解压到/opt/module/目录下
tar -zxvf spark-2.1.1-bin-hadoop2.7.tgz -C /opt/module - 然后复制刚刚解压得到的目录, 并命名为spark-local:
- cp -r spark-2.1.1-bin-hadoop2.7 spark-local
语法解析
./bin/spark-submit \
--class <main-class> \
--master <master-url> \
--deploy-mode <deploy-mode> \
--conf <key>=<value> \
... # other options
<application-jar> \
[application-arguments]
--master 指定 master 的地址,默认为local. 表示在本机运行.
--class 你的应用的启动类 (如 org.apache.spark.examples.SparkPi)
--deploy-mode 是否发布你的驱动到 worker节点(cluster 模式) 或者作为一个本地客户端 (client 模式) (default: client)
--conf: 任意的 Spark 配置属性, 格式key=value. 如果值包含空格,可以加引号"key=value"
application-jar: 打包好的应用 jar,包含依赖. 这个 URL 在集群中全局可见。 比如hdfs:// 共享存储系统, 如果是 file:// path, 那么所有的节点的path都包含同样的jar
application-arguments: 传给main()方法的参数
--executor-memory 1G 指定每个executor可用内存为1G
--total-executor-cores 6 指定所有executor使用的cpu核数为6个
--executor-cores 表示每个executor使用的 cpu 的核数
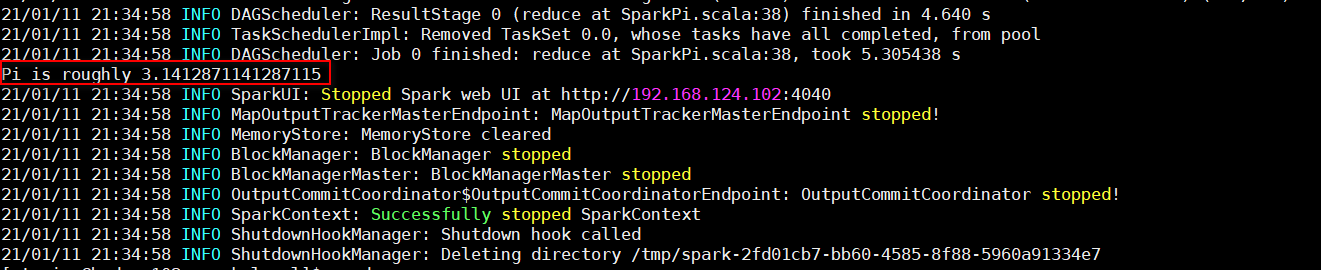
运行官方求PI的案例
/opt/module/spark-local/bin/spark-submit \
--class org.apache.spark.examples.SparkPi \
--master local[2] \
./examples/jars/spark-examples_2.11-2.1.1.jar 100
运行结果:

程序改变世界
