数据挖掘复习
概念
-
模型评测
-
混淆矩阵
预测:1 预测:0 真实:1 True Positive (TP) False Negative (FN) 真实:0 False Poisitive (FP) True Negative (TN) -
准确率:预测正确的占所有的
-
精确率:预测为1的中真实也为1的
-
召回率:真实为1的中预测也为1的
-
F1:综合精确率与召回率
-
-
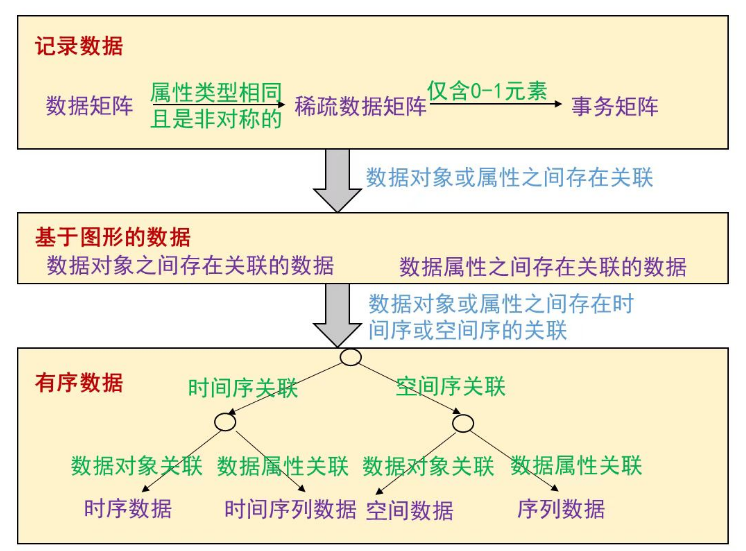
数据的属性
-
基本概念
-
数据集的类型
-
-
-
-
数据质量问题
-
遗漏值:一个对象遗漏一个或多个属性值
-
离群点/异常值
-
不一致的值
- 产生矛盾的数据:出生日期与年龄不符
- 属性不一致:同名异义;异名同义
- 属性值不一致:计量方式或表达方式不一致
- 分辨率不一致
-
测量误差
-
噪声:测量误差的随机部分
-
伪像:确定性现象的结果,如镜头破裂导致照片中出现相同裂纹
-
精度:重复测量值之间的接近程度
- 值集合的标准差
-
偏倚:测量值与被测量之间的系统的变差
- 值集合的均值与真实值的差
-
-
-
数据归约
-
聚集:合并数据对象
-
抽样
-
简单随机抽烟
- 无放回
- 有放回
-
分层抽样
-
整群抽样
-
-
特征子集选择
-
嵌入方法
- 基于线性模型的特征选择
- 基于最近邻的方法
-
过滤方法
-
基于统计值的方法
- 方差大的特征区分能力更强,方差小的特征被过滤
-
基于泊松相关性的方法
- 计算每个特征与分类结果的相关性
-
-
理想方法
- 对所有特征子集进行测试
-
贪婪算法
- 前向:依次添加
- 后向:依次减少
-
-
维规约
-
将一些旧属性合并在一起创建新属性
-
主成分分析PCA
-
将数据映射到数据损失最小的方向
-
所有数据对象到映射方向的距离之和最小
-
所有数据对象映射后散度最大的方向
-
工作过程
- 第一维:方差最大的属性
- 第二维:与第一维正交的平面中方差最大的方向
- 第三维:与第一、第二维正交的平面中方差最大的方向
- ……
- 第n维
- k维之后的方差几乎为0,选择前k维作为新特征
-
-
线性判别分析
- 找到一个投影方向,使不同类别的实例在该方向上的投影能最大程度分开
-
-
-
数据转换
-
特征创建
-
数据离散化
-
离散化
-
将连续属性变换成分类属性
-
非监督离散化
- 等宽离散
- 等频离散
-
监督离散化
-
基于熵的方法
- 排序找断点
- 计算每个断点带来的信息增益
- 选择信息增益最高的断点进行分裂
-
-
-
-
二元化
- 将连续或离散属性变换成一个或多个二元属性
-
-
变量变换
- 简单函数
- 标准化
-
-
相似度和相异度
-
可用单调减函数相互转换
-
统称为临近度
-
相异度
-
欧几里得距离
-
闵可夫斯基距离
-
度量
- 非负性
- 对称性
- 三角对称性
-
-
相似度
-
相似系数:针对仅包含二元属性的对象之间的相似性度量
-
简单匹配系数
-
Jaccard系数
-
-
非二元数据
-
余弦相似度
-
广义Jaccard系数(Tanimoto系数)
-
-
相关性
-
泊松相关系数
-
马氏距离
- 适用于属性相关、值域不同、数据分布近似高斯分布的情况
-
-
异种对象的相似度
-
-
临近度计算方法的选择
-
稠密、连续数据
- 欧几里得距离
-
稀疏、非对称数据
- 余弦相似度或广义Jaccard系数
-
时间序列数据
- 量度重要:欧几里得距离
- 形状重要:相关性
-
类似的趋势或周期模式
- 数据变换或规范化
-
-
-
多元汇总统计
-
位置度量
- 均值:各属性分别取均值
-
散布度量
- 各属性的散布度量
- 采用协方差矩阵
-
-
可视化
-
盒状图
- 标注出了以下百分位点:10、25、50、75、90
-
分类算法
文本分类
-
文本特征表示
-
One-hot表示
-
TFIDF表示
-
基于语义的表示
-
同义词集合表示
- “电脑”出现时,认为“计算机”也出现
-
嵌入表示
- 义素是语义基本单元,一个词由不同的义素按不同比例配比而成
-
-
词嵌入表示
-
词向量:50~100维的浮点向量
- 利用训练好的词向量
- word2vec训练自己的词向量
-
-
句子的嵌入表示
- 词向量的连接或累加
-
基于话题的表示
- 话题是一个文档集的基本元素
-
模型泛化性能
-
泛化性能:模型对未知类标数据上的分类性能
-
导致泛化性能降低的原因
- 过度训练
- 训练数据量少
- 有噪音数据
-
泛化性能的评估
-
乐观估计:用训练误差(模型在训练集上的错分样本比率)估计
-
悲观估计
-
估计误差率的置信区间
-
最小描述长度
-
-
提升模型泛化性能
-
剪枝
-
前向剪枝:建立树的过程中决定何时停止建立子树
-
后向剪枝:在决策树建立之后决定如何剪枝
- 子树置换
- 子树提升
-
-
不均衡分类、多分类、分类的效率
不均衡分类
-
概念:不同类别的数据实例数目差别较大的分类
-
代价敏感学习:根据代价矩阵计算模型代价,作为评价模型好坏的依据
- 对应位置相乘再累加
-
抽样的方法
-
使多数类与少数类的样例比例接近1:1
- 多数类中随机选择一部分样例
- 复制少数类中的样本
-
问题
- 欠采样:丢失数据
- 过采样:引入冗余数据
-
解决
- 只采样分类边缘的数据用于计算
- 在少数类中选取两个临近的实例,在其之间的区域内随机生成新样例
-
多分类问题
-
一对多
- 针对每个类别的二分类器,置信度最高的就是分类结果
- 对置信度的计算结果更为敏感,需要仔细调整参数
-
成对分类
- 类别之间两两组合,共
- 类别之间两两组合,共
-
集成分类
- 多个二分类器的输出作为01串,与类别对应的编码进行比较,相近的是分类结果
-
衡量两个输出是否相近
- 汉明距离:不同字符的个数
- 编码之间的汉明距离越大越好
- 类别编码不同维度之间关联越小越好
算法的效率
-
基于实例的方法
- 对未知类标的实例,从已知类标的实例中找距离最近或最相似的实例,将其类标作为自己的类标
-
如何高效寻找最近邻
-
KD-tree
-
二叉树
-
-
提升效率
-
平衡的KD-tree
- 选择方差最大的维度做下一步区域划分
- 将样例尽量等分到两个区域
-
区域尽量是正方形
-
-
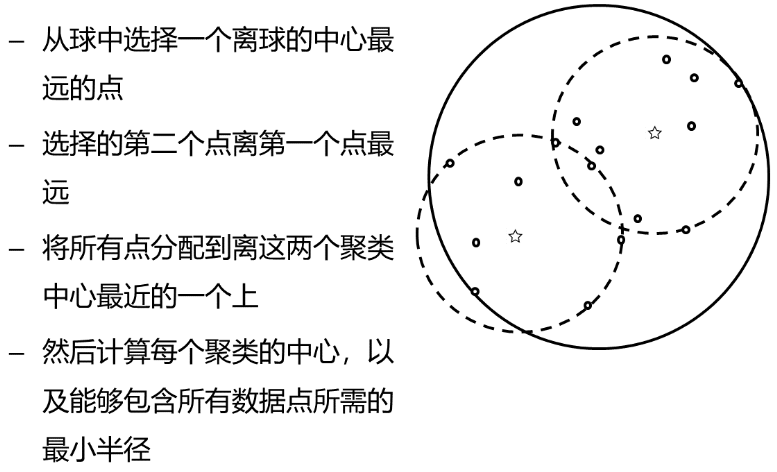
球树
-
将KD-tree中超矩形体换为超球体
-
建立平衡的球树
-
-
关联分析
-
基本概念
- 事务:事务数据集中的一条数据,由项组成
- 项:如
- 项集:项的集合,如{
-
关联规则挖掘
-
-
-
-
表示当项集
-
关联规则的置信度
- 衡量发生
- 衡量发生
-
最小置信度
- 由用户或专家给定
-
-
样本数足够多,才能消除偶然性,置信度才可靠
-
关联规则的支持度
- 衡量
- 衡量
-
最小支持度
-
-
支持度大于等于最小支持度,则称
-
- 强规则可用于指导实际
- 关联分析的目标:挖掘强规则
-
强规则挖掘方法
-
找出所有频繁项集
- 找出所有候选项集(使用Apriori算法)
- 求各项集的支持度
- 挑选频繁项集
-
找出所有强规则
- 从频繁项集找出所有关联规则
- 求各关联规则置信度
- 挑选强规则
-
-
频繁项集挖掘:Apriori算法
-
基本定理
- 频繁项集的子集也是频繁项集
- 非频繁项集的超集不是频繁项集
-
工作过程
- 生成候选1项集
- 挑选频繁1项集
- 利用频繁1项集生成候选2项集
- 挑选频繁2项集
- 利用频繁2项集生成候选3项集
- ……
-
算法实现(9-38)
-
自连接:生成可能的(k+1)项集
-
剪枝:删除非频繁(k+1)项集
-
计算每个候选项集的支持数
-
遍历事务数据库,对每个候选项集的支持数逐一统计(9-42)
-
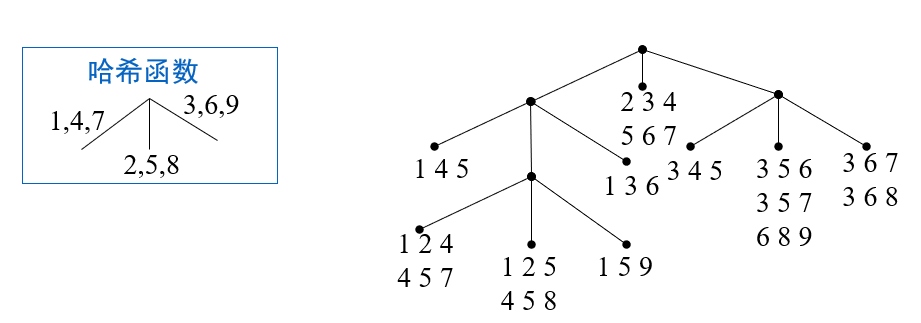
构建两颗树
-
候选n项集的hash树
-
事务的n项子集树
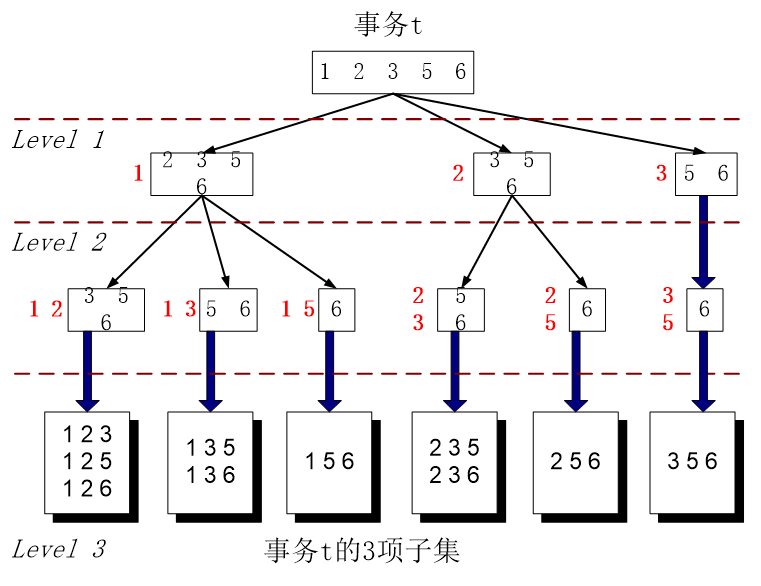
-
-
将这两棵树对齐

-
-
-
-
产生强规则
-
对频繁项集
-
候选关联规则
-
利用定理剪枝
- 如果
- 如果
-
-
频繁项集挖掘:FP增长算法
-
解决的问题
- 避免多次硬盘IO的代价
- 减少每次遍历考虑的事务数量
-
FP树:事务数据库的压缩表示
-
根节点为null,其它节点包含一个项和一个计数
-
每个事务对应FP树上的一条路径
-
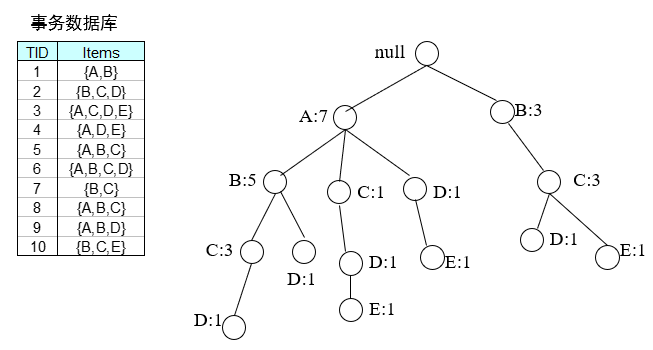
-
提高FP树的压缩度
- 事务中的项按支持度递减序排序
- 删除每条事务中的非频繁项
-
-
条件FP树
- 参考
- 使用项头表记录指针,用于辅助频繁项集的生成
-
-
-
序列模式挖掘
-
与关联规则挖掘的区别:
-
基本概念
-
序列:由元素组成
- 序列的长度
- k-序列
-
元素:由项组成
-
项(事件)
-
子序列
-
-
序列模式挖掘即挖掘频繁子序列
-
基本定理
- 非频繁序列
- 非频繁序列
-
-
-
子图模式挖掘
-
基本概念
-
GraphApriori算法
-
聚类分析
-
基本概念
-
聚类分析:找到数据对象的簇,使得簇内数据间的距离最小化,不同簇数据间的距离最大化
-
聚类任务的类型
- 划分聚类、层次聚类
- 互斥聚类、重叠聚类、模糊聚类
- 完全聚类、部分聚类
-
簇的不同类型
-
明显分离的:每个对象到同簇中每个对象的距离比到不同簇中任意对象的距离都近
-
基于原型的:每个对象到定义该簇的原型(质心/代表性个体)的距离比到其他簇的原型的距离更近
-
基于图的:结点是数据对象,边是对象之间的联系,簇定义为连通分支
- 其中两个对象是相连的,仅当它们的距离在指定的范围之内
-
基于密度的:簇是对象的稠密区域
-
概念簇:簇定义为有某种共同性质的对象的集合
-
-
基于原型的聚类
-
K均值聚类
-
流程
-
选择
-
repeat
- 将每个点指派到最近(欧氏距离、余弦相似度、相关系数、Jaccard系数等)的质心,形成
- 重新计算每个簇的质心
- 将每个点指派到最近(欧氏距离、余弦相似度、相关系数、Jaccard系数等)的质心,形成
-
until 质心不发生变化(少量点所属簇发生改变)
-
-
评估指标
- SSE:误差平方和,体现簇内个体的集中程度,越小越好
-
一定收敛
-
增大
- 处理具有不同尺寸的簇
- 处理不同密度的簇
- 处理非球型的簇
-
-
模糊C均值聚类
-
流程
-
选择一个初始模糊伪划分,即对所有的
-
repeat
- 使用模糊伪划分,计算每个簇的质心
- 重新计算模糊伪划分,即
-
until 质心不发生变化
-
-
p值
- 越大,所有簇的质心越趋向全局质心
- 越接近1,越接近K均值
-
-
使用混合模型的聚类
-
优点
- 能识别不同大小的簇
- 能识别不同密度的簇
- 比K均值、模糊C均值更一般的聚类方法
-
缺点
- 速度慢
- 只包含少量数据点时不适用
-
-
自组织映射
-
优点
- 有利于聚类结果可视化
-
缺点
- 用户必须选择参数、领域函数、网格类型和质心个数
- 一个SOM簇通常并不对应于单个自然簇
- SOM缺乏具体的目标函数
- SOM不保证收敛
-
基于密度的聚类
寻找被低密度区域分离的高密度区域
-
DBSCAN
-
优点
- 可以发现任意形状的簇
-
缺点
- 高维数据密度定义困难
- 不能处理密度变化太大的簇
- 需要计算所有点对的邻近度,计算开销可能很大
-
-
基于网格的聚类
-
优点
- 快速有效
-
缺点
- 依旧无法处理密度差距较大的情况
- 依旧无法处理高维的问题
- 边缘缺失
-
-
子空间聚类
-
优点
- 提供了搜索子空间发现簇的有效技术
- 用一组不等式概括构成一个簇的单元列表的能力
-
缺点
- 维度的指数复杂度
-
-
DENCLUE
-
优点
- 发现不同形状、不同大小的簇
- 擅长处理噪声和离群点
-
缺点
- 依旧无法处理密度不相同的数据
-
层次聚类算法
-
凝聚层次聚类
-
流程
-
计算相似度矩阵
-
每个数据形成一个簇
-
repeat
- 合并最近的两个簇
- 更新邻接矩阵
-
until 只剩下一个簇
-
-
实际上是距离矩阵的不断合并、更新过程
-
两个簇的相似度的计算方法
发现非椭球形簇 对噪音数据或异常点不敏感 最小距离 √ × 最大距离 × √ 平均距离 × √ 沃德法 × √ - 最小距离
- 最大距离
- 平均距离
- 簇中心距离
- 沃德法:两个簇的相似度基于两个簇合并后方差的增加
-
-
分裂层次聚类
- 基于最小生成树
-
可伸缩的层次聚类:CURE
- 无法识别不同密度的簇
基于图的聚类
-
边的权重等于两个点之间的近似性
-
变色龙算法:Chamelon
-
簇间相对接近度和簇内相对连接度两个主要属性
-
基本思想:上述两个主要属性合并前后变化不大,这两个簇才应该合并
-
典型应用场景:空间数据
- 任意形状、方向、非一致的大小
- 簇间密度不一致,簇内密度多变
- 存在特殊条纹
-
异常检测
-
基本概念
- 异常检测:发现与大部分其他对象不同的对象
-
挑战
- 漏判(异常点成群结队出现)
- 误判(多个接近的正常点全被判为异常点)
-
基于统计的方法
-
在数据的概率分布模型中以低概率出现的点
-
混合模型方法
- 正常数据概率分布+离群点概率分布(通常取均匀分布)
-
优缺点
- 可提供置信度
- 识别数据集的具体分布
-
-
基于邻近度的方法
-
计算每对数据点之间的距离
-
定义异常点
- 第k个最近邻距离最大的n个点
- 到k近邻的平均距离最大的n个点
- 距离D内相邻点数目小于p的点
- 定义离群点得分为该对象周围密度的逆
-
-
基于密度的方法
-
绝对密度
- 给定半径内的点计数
-
相对密度
- 点x的密度与它的k最近邻的平均密度之比作为相对密度
-
-
基于聚类的方法
- 离群点不强属于任何簇
本文作者:lentikr
本文链接:https://www.cnblogs.com/lentikr/p/review-1jnoum.html
版权声明:本作品采用CC-BY-NC-SA 4.0许可协议进行许可。



【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步