Kafka
一、Kafka简介
定义:Kafka是一个分布式的基于发布/订阅模式的消息队列,主要应用于大数据实时处理领域。
开 源 的 分 布 式 事 件 流 平 台 。是一种高吞吐量的分布式发布/订阅消息系统
发布/订阅:消息的发布者不会将消息直接发送给特定的订阅者,而是将发布的消息分成不同的类别,订阅者只接收感兴趣的消息。它可以处理消费者在网站中的所有动作流数据。
优缺点:
解耦,冗余,扩展性,灵活性&峰值处理,可恢复性,顺序保证,缓冲,异步通信
传统的消息队列的主要应用场景包括:缓存/消峰、解耦和异步通信。
缓冲/消峰:有助于控制和优化数据流经过系统的速度,解决生产消息和消费消息的处理速度不一致的情况。
解耦:允许你独立的扩展或修改两边的处理过程,只要确保它们遵守同样的接口约束。
异步通信:允许用户把一个消息放入队列,但并不立即处理它,然后在需要的时候再去处理它们。
面试题:Kafka 本质上是一个 MQ(Message Queue),使用消息队列的好处?
- 解耦:允许我们独立的扩展或者修改队列两边的处理过程
- 可恢复性
- 缓冲:有助于解决生产消息和消费消息的处理速度不一致的情况
- 灵活性&峰值处理能力
- 异步通信:消息队列允许用户把消息放入队列但不立即处理它

消息队列的两种模式
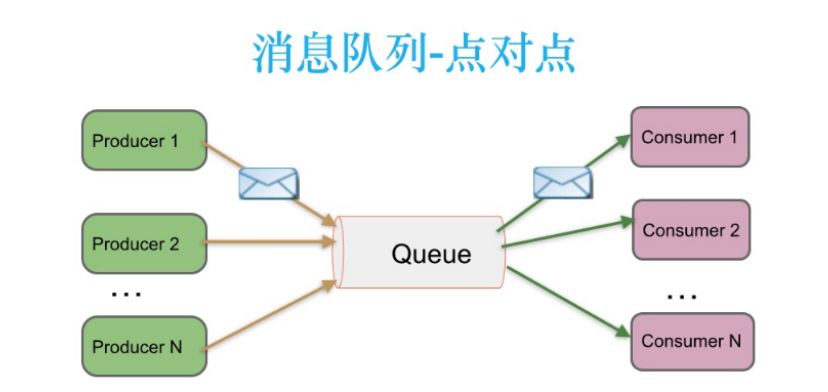
1)点对点模式
消费者主动拉取数据,消息收到后清除消息
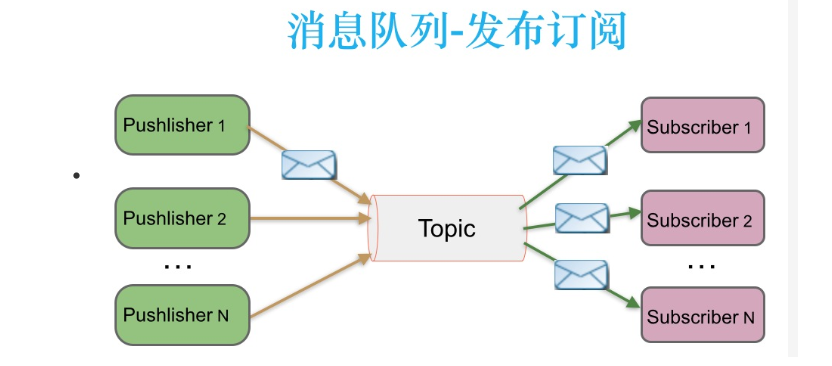
2)发布/订阅模式
可以有多个topic主题(浏览、点赞、收藏、评论等)
消费者消费数据之后,不删除数据
每个消费者相互独立,都可以消费到数据
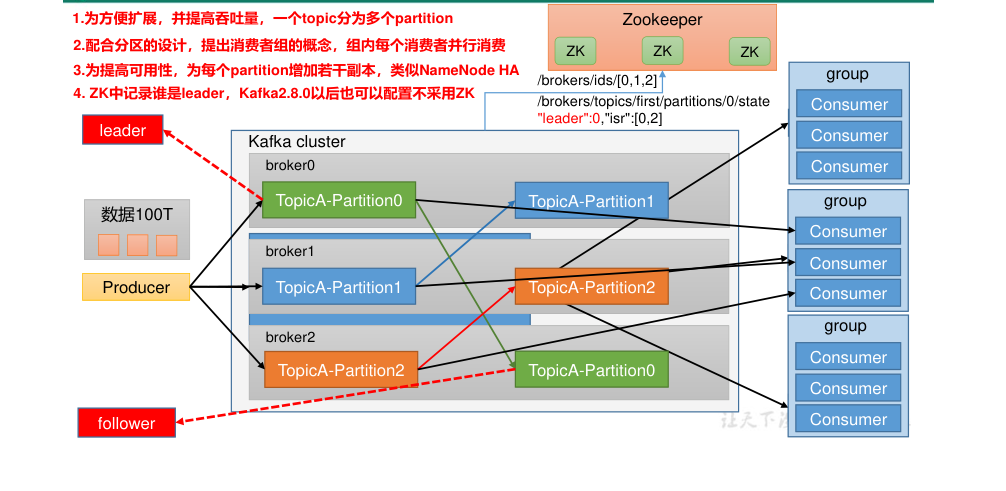
二、系统架构

三、环境搭建
官方下载地址:http://kafka.apache.org/downloads.html
基于Zookeeper搭建并开启
启动kafka命令
kafka-server-start.sh /opt/yjx/kafka_2.12-0.11.0.3/config/server.properties
常见命令
创建主题
kafka-topics.sh --zookeeper node01:2181 --create --replication-factor 2 --partitions 3 --topic userlog
查看所有主题
kafka-topics.sh --zookeeper node01:2181 --list
查看主题
kafka-topics.sh --zookeeper node01:2181,node02:2181,node03:2181 --describe --topic userlog
创建生产者
kafka-console-producer.sh --broker-list node01:9092,node02:9092,node03:9092 --topic userlog

创建消费者
kafka-console-consumer.sh --zookeeper node01:2181,node02:2181,node03:2181 --from-beginning --topic userlog


集群命令 kf.sh strat status stop
四、数据存储
topic --> partition --> Segment=>(log.segment.bytes log.segment.ms)
Topic 在物理层面上以partition为分组,一个topic可以分成若干个partition
Partition可以细分为Segment,一个partition物理上可以由多个Segment组成
Segment的两个参数:
- log.segment.bytes:单个segment可容纳的最大数据量,默认为1GB
- log.segment.ms:Kafka在commit一个未写满的segment前所等待的时间(默认为7天)
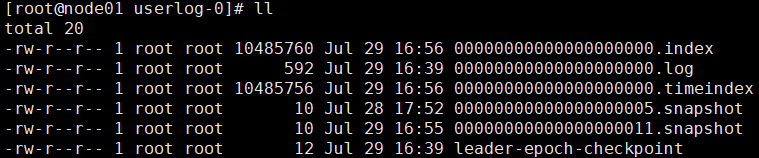
Logment文件由两部分组成,分别为“.index”文件和“.log”文件,分别表示为 Segment 索引文件和数据文件。
消息都具有固定的物理结构,包括:offset(8 Bytes)、消息体的大小(4 Bytes)、crc32(4 Bytes)、magic(1 Byte)、attributes(1 Byte)、key length(4 Bytes)、key(K Bytes)、payload(N Bytes)等等字段,可以确定一条消息的大小,即读取到哪里截止。
“.index” 文件存储大量的索引信息,“.log” 文件存储大量的数据,索引文件中的元数据指向对应数
据文件中 Message 的物理偏移量。
其他文件
.index 位移索引
.timeindex 时间戳索引
.snapshot文件,记录了producer的事务信息。(todo)
五、生产者数据安全
5.1 数据分区
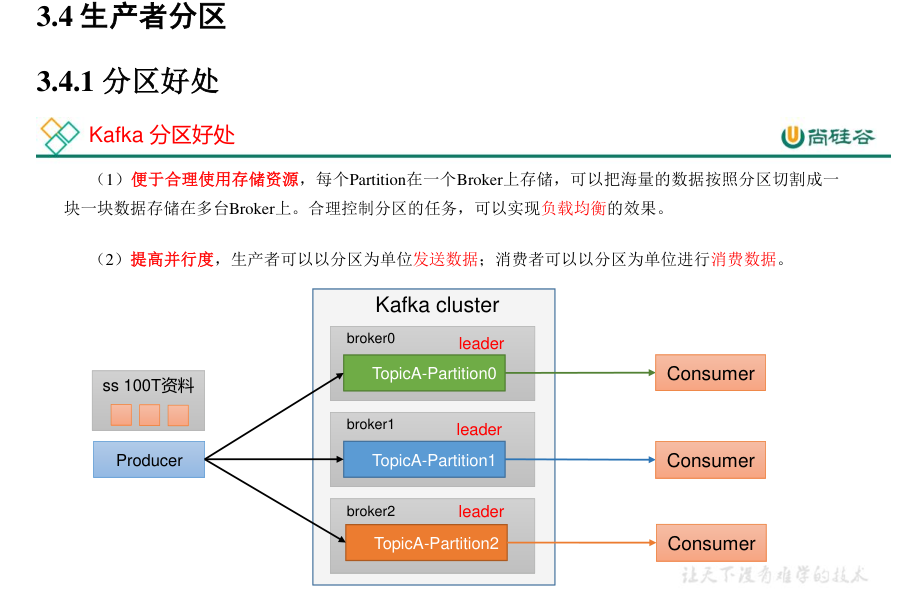
分区原因
- 方便在集群中扩展,每个 Partition 可以通过调整以适应它所在的机器
- 一个 Topic 又可以有多个 Partition 组成,因此可以以 Partition 为单位读写了。
- 可以提高并发,因此可以以 Partition 为单位读写了。
分区原则
-
将 Producer 发送的数据封装成一个 ProducerRecord 对象。对象包含:
topic:string 类型,NotNull。
partition:int 类型,可选。
timestamp:long 类型,可选。
key:string 类型,可选。
value:string 类型,可选。
headers:array 类型,Nullable。
5.2 数据可靠性保证
5.2.1 ACK机制
- 为保证 Producer 发送的数据,能可靠地发送到指定的 Topic
- Topic 的每个 Partition 收到 Producer 发送的数据后,都需要向 Producer 发送ACK(ACKnowledge 确认收到)。
- 如果 Producer 收到 ACK,就会进行下一轮的发送,否则重新发送数据。
5.2.2 ACK时机
部分 Follower 与 Leader 同步完成,Leader 发送 ACK
全部 Follower 与 Leader 同步完成,Leader 发送 ACK。
5.2.3 ACK应答机制
Kafka 为用户提供了三种可靠性级别,用户根据可靠性和延迟的要求进行权衡


5.2.4 故障处理
LEO:每个副本最大的 Offset。
HW:消费者能见到的最大的 Offset,ISR 队列中最小的 LEO。
Follower 故障:
Follower 发生故障后会被临时踢出 ISR 集合,待该 Follower 恢复后,Follower 会 读取本地磁盘记录的上次的 HW,并将 log 文件高于 HW 的部分截取掉,从 HW 开始向 Leader 进行同步数据操作。等该 Follower 的 LEO 大于等于该 Partition 的 HW,即 Follower 追上 Leader 后,就可以重新加入 ISR 了。
Leader 故障:
Leader 发生故障后,会从 ISR 中选出一个新的 Leader,之后,为保证多个副本之间的数据一致性,其余的 Follower 会先将各自的 log 文件高于 HW 的部分截掉,然后从新的 Leader 同步数据。注意:这只能保证副本之间的数据一致性,并不能保证数据不丢失或者不重复。
5.2.5 Exactly Once 语义
1.将服务器的 ACK 级别设置为 -1,可以保证 Producer 到 Server 之间不会丢失数据,即 At LeastOnce 语义。
2.将服务器 ACK 级别设置为 0,可以保证生产者每条消息只会被发送一次,即 At Most Once 语义。
3.Exactly Once
重要数据既不重复也不丢失
0.11 版本的 Kafka,引入了幂等性:Producer 不论向 Server 发送多少重复数据,Server 端都只会持久化一条。
At Least Once + 幂等性 = Exactly Once
要启用幂等性,只需要将 Producer 的参数中 enable.idompotence 设置为 true 即可。
开启幂等性的 Producer 在初始化时会被分配一个 PID,发往同一 Partition 的消息会附带Sequence Number。
而 Borker 端会对 <PID,Partition,SeqNumber> 做缓存,当具有相同主键的消息提交时,Broker 只会持久化一条。
但是 PID 重启后就会变化,同时不同的 Partition 也具有不同主键,所以幂等性无法保证跨分区会话的 Exactly Once。
六、消费者数据安全
6.1 消费方式
Consumer 采用 Pull(拉取)模式从 Broker 中读取数据。
读数据采用稀疏索引,可以快速定位要消费的数据
6.2 分区分配策略
将分区的所有权从一个消费者移到另一个消费者称为重新平衡(rebalance)
分区分配的时机
- 同一个 Consumer Group 内新增消费者
- 消费者离开当前所属的Consumer Group,包括shuts down 或 crashes
- 订阅的主题新增分区
Kafka 有三种分配策略:
- 一个是RangeAssignor(默认)
- 一个是 RoundRobinAssignor
- 一个是StickyAssignor(0.11.x版本开始引入)
6.3 OffSet
七、Kafka的事务性

幂等和事务是Kafka 0.11.0.0版本引入的两个特性,以此来实现EOS(exactly once semantics,精确一次处理语义)。
7.1 Kafka幂等性
幂等性就是指Producer不论向Broker发送多少次重复数据,Broker端都只会持久化一条,保证了不重复。
精确一次(Exactly Once) = 幂等性 + 至少一次( ack=-1 + 分区副本数>=2 + ISR最小副本数量>=2) 。

7.2 Kafka事务
Kafka事务性主要是为了解决幂等性无法跨Partition运作的问题,事务性提供了多个Partition写入的原子性
即写入多个Partition要么全部成功,要么全部失败,不会出现部分成功部分失败这种情况。

八、Kafka优化
Partition 数目

Replication factor

批量写入

九、面试题

Kafka的生产命令和消费命令
Kafka的存储结构
ACK机制
ISR机制
HW、LEO
__consumer_offsets
消费重平衡触发条件和策略
Flume调优,Kafka调优
十、Kafka-Eagle 安装
官网:https://www.kafka-eagle.org/
注意:启动之前需要先启动 ZK 以及 KAFKA。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号