
转:深入HBase架构解析(二)
HBase读的实现
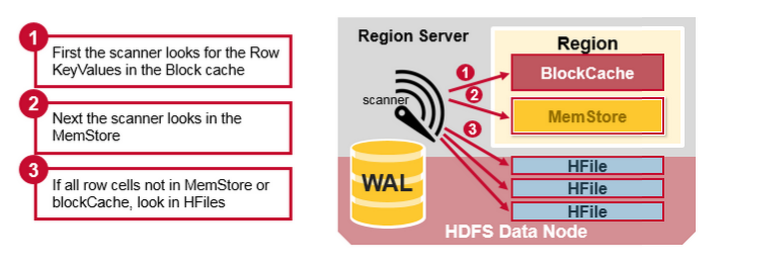
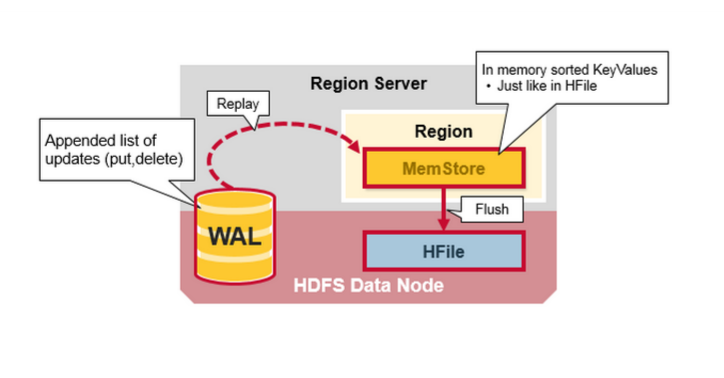
通过前文的描述,我们知道在HBase写时,相同Cell(RowKey/ColumnFamily/Column相同)并不保证在一起,甚至删除一个Cell也只是写入一个新的Cell,它含有Delete标记,而不一定将一个Cell真正删除了,因而这就引起了一个问题,如何实现读的问题?要解决这个问题,我们先来分析一下相同的Cell可能存在的位置:首先对新写入的Cell,它会存在于MemStore中;然后对之前已经Flush到HDFS中的Cell,它会存在于某个或某些StoreFile(HFile)中;最后,对刚读取过的Cell,它可能存在于BlockCache中。既然相同的Cell可能存储在三个地方,在读取的时候只需要扫瞄这三个地方,然后将结果合并即可(Merge Read),在HBase中扫瞄的顺序依次是:BlockCache、MemStore、StoreFile(HFile)。其中StoreFile的扫瞄先会使用Bloom Filter过滤那些不可能符合条件的HFile,然后使用Block Index快速定位Cell,并将其加载到BlockCache中,然后从BlockCache中读取。我们知道一个HStore可能存在多个StoreFile(HFile),此时需要扫瞄多个HFile,如果HFile过多又是会引起性能问题。
Compaction
MemStore每次Flush会创建新的HFile,而过多的HFile会引起读的性能问题,那么如何解决这个问题呢?HBase采用Compaction机制来解决这个问题,有点类似Java中的GC机制,起初Java不停的申请内存而不释放,增加性能,然而天下没有免费的午餐,最终我们还是要在某个条件下去收集垃圾,很多时候需要Stop-The-World,这种Stop-The-World有些时候也会引起很大的问题,比如参考本人写的这篇文章,因而设计是一种权衡,没有完美的。还是类似Java中的GC,在HBase中Compaction分为两种:Minor Compaction和Major Compaction。
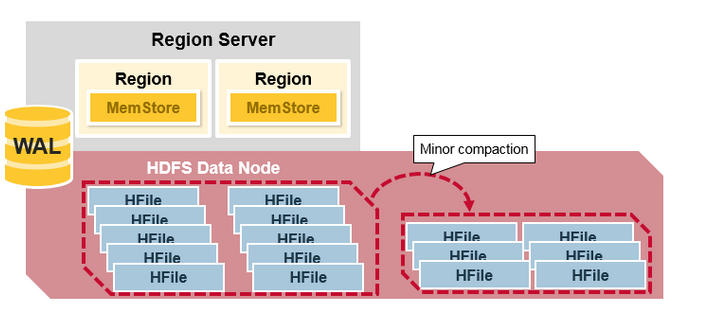
- Minor Compaction是指选取一些小的、相邻的StoreFile将他们合并成一个更大的StoreFile,在这个过程中不会处理已经Deleted或Expired的Cell。一次Minor Compaction的结果是更少并且更大的StoreFile。(这个是对的吗?BigTable中是这样描述Minor Compaction的:As write operations execute, the size of the memtable in- creases. When the memtable size reaches a threshold, the memtable is frozen, a new memtable is created, and the frozen memtable is converted to an SSTable and written to GFS. This minor compaction process has two goals: it shrinks the memory usage of the tablet server, and it reduces the amount of data that has to be read from the commit log during recovery if this server dies. Incom- ing read and write operations can continue while com- pactions occur. 也就是说它将memtable的数据flush的一个HFile/SSTable称为一次Minor Compaction)
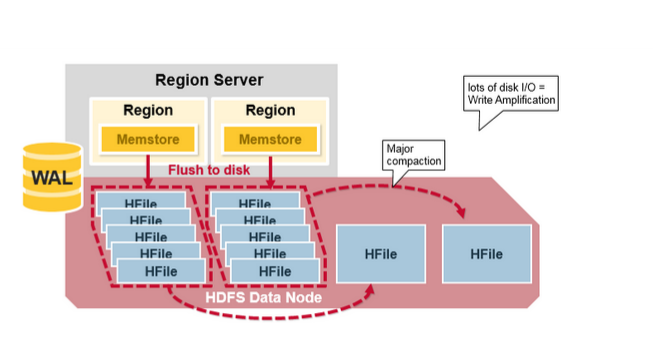
- Major Compaction是指将所有的StoreFile合并成一个StoreFile,在这个过程中,标记为Deleted的Cell会被删除,而那些已经Expired的Cell会被丢弃,那些已经超过最多版本数的Cell会被丢弃。一次Major Compaction的结果是一个HStore只有一个StoreFile存在。Major Compaction可以手动或自动触发,然而由于它会引起很多的IO操作而引起性能问题,因而它一般会被安排在周末、凌晨等集群比较闲的时间。
更形象一点,如下面两张图分别表示Minor Compaction和Major Compaction。
HRegion Split
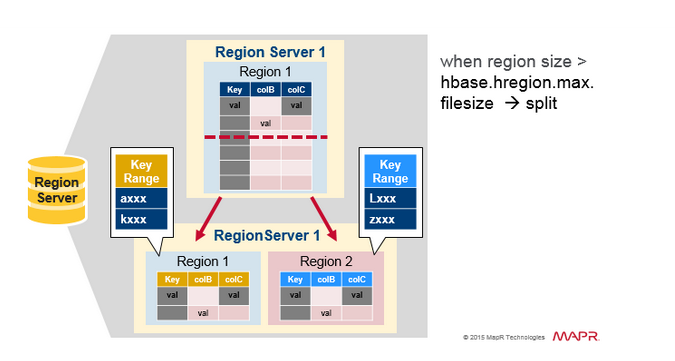
最初,一个Table只有一个HRegion,随着数据写入增加,如果一个HRegion到达一定的大小,就需要Split成两个HRegion,这个大小由hbase.hregion.max.filesize指定,默认为10GB。当split时,两个新的HRegion会在同一个HRegionServer中创建,它们各自包含父HRegion一半的数据,当Split完成后,父HRegion会下线,而新的两个子HRegion会向HMaster注册上线,处于负载均衡的考虑,这两个新的HRegion可能会被HMaster分配到其他的HRegionServer中。关于Split的详细信息,可以参考这篇文章:《Apache HBase Region Splitting and Merging》。
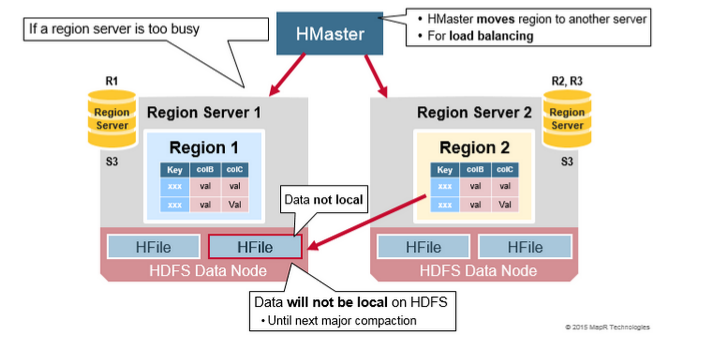
HRegion负载均衡
在HRegion Split后,两个新的HRegion最初会和之前的父HRegion在相同的HRegionServer上,出于负载均衡的考虑,HMaster可能会将其中的一个甚至两个重新分配的其他的HRegionServer中,此时会引起有些HRegionServer处理的数据在其他节点上,直到下一次Major Compaction将数据从远端的节点移动到本地节点。
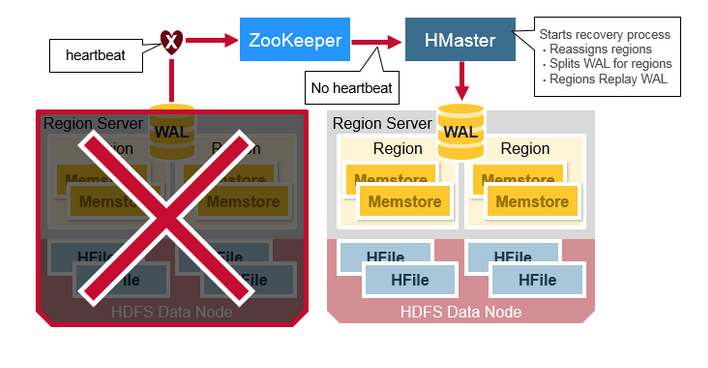
HRegionServer Recovery
当一台HRegionServer宕机时,由于它不再发送Heartbeat给ZooKeeper而被监测到,此时ZooKeeper会通知HMaster,HMaster会检测到哪台HRegionServer宕机,它将宕机的HRegionServer中的HRegion重新分配给其他的HRegionServer,同时HMaster会把宕机的HRegionServer相关的WAL拆分分配给相应的HRegionServer(将拆分出的WAL文件写入对应的目的HRegionServer的WAL目录中,并并写入对应的DataNode中),从而这些HRegionServer可以Replay分到的WAL来重建MemStore。
HBase架构简单总结
在NoSQL中,存在著名的CAP理论,即Consistency、Availability、Partition Tolerance不可全得,目前市场上基本上的NoSQL都采用Partition Tolerance以实现数据得水平扩展,来处理Relational DataBase遇到的无法处理数据量太大的问题,或引起的性能问题。因而只有剩下C和A可以选择。HBase在两者之间选择了Consistency,然后使用多个HMaster以及支持HRegionServer的failure监控、ZooKeeper引入作为协调者等各种手段来解决Availability问题,然而当网络的Split-Brain(Network Partition)发生时,它还是无法完全解决Availability的问题。从这个角度上,Cassandra选择了A,即它在网络Split-Brain时还是能正常写,而使用其他技术来解决Consistency的问题,如读的时候触发Consistency判断和处理。这是设计上的限制。
从实现上的优点:
- HBase采用强一致性模型,在一个写返回后,保证所有的读都读到相同的数据。
- 通过HRegion动态Split和Merge实现自动扩展,并使用HDFS提供的多个数据备份功能,实现高可用性。
- 采用HRegionServer和DataNode运行在相同的服务器上实现数据的本地化,提升读写性能,并减少网络压力。
- 内建HRegionServer的宕机自动恢复。采用WAL来Replay还未持久化到HDFS的数据。
- 可以无缝的和Hadoop/MapReduce集成。
实现上的缺点:
- WAL的Replay过程可能会很慢。
- 灾难恢复比较复杂,也会比较慢。
- Major Compaction会引起IO Storm。
- 。。。。
转:http://www.blogjava.net/DLevin/archive/2015/08/22/426950.html
参考:
https://www.mapr.com/blog/in-depth-look-hbase-architecture#.VdNSN6Yp3qx
http://jimbojw.com/wiki/index.php?title=Understanding_Hbase_and_BigTable
http://hbase.apache.org/book.html
http://www.searchtb.com/2011/01/understanding-hbase.html
http://research.google.com/archive/bigtable-osdi06.pdf

 浙公网安备 33010602011771号
浙公网安备 33010602011771号