

转:OLAP数仓从百万到百亿级数据量实时分析
一、有哪些类型的OLAP数仓?
1.按数据量划分
对一件事物或一个东西基于不同角度,可以进行多种分类方式。对数仓产品也一样。比如我们可以基于数据量来选择不同类型的数量,如下图所示:
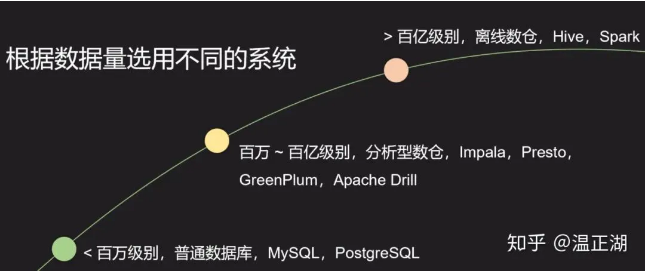
本系列文章主要关注的是数据量处于百万到百亿级别的偏实时的分析型数仓,Cloudera的Impala、Facebook的Presto和Pivotal的GreenPlum均属于这类系统;如果超过百亿级别数据量,那么一般选择离线数仓,如使用Hive或Spark等(SparkSQL3.0看起来性能提升很明显);对于数据量很小的情况,虽然是分析类应用,也可以直接选择普通的关系型数据库,比如MySQL等,“杀鸡焉用牛刀”。
2.按建模类型划分
下面我们主要关注数据量中等的分析型数仓,聚焦OLAP系统。根据维基百科对OLAP的介绍,一般来说OLAP根据建模方式可分为MOLAP、ROLAP和HOLAP 3种类型,下面分别进行介绍并分析优缺点。
(1)MOLAP
这应该算是最传统的数仓了,1993年Edgar F. Codd提出OLAP概念时,指的就是MOLAP数仓,M即表示多维(Multidimensional)。大多数MOLAP产品均对原始数据进行预计算得到用户可能需要的所有结果,将其存储到优化过的多维数组存储中,可以认为这就是上一篇所提到的“数据立方体”。
由于所有可能结果均已计算出来并持久化存储,查询时无需进行复杂计算,且以数组形式可以进行高效的免索引数据访问,因此用户发起的查询均能够稳定地快速响应。这些结果集是高度结构化的,可以进行压缩/编码来减少存储占用空间。
但高性能并不是没有代价的。首先,MOLAP需要进行预计算,这会花去很多时间。如果每次写入增量数据后均要进行全量预计算,显然是低效率的,因此支持仅对增量数据进行迭代计算非常重要。其次,如果业务发生需求变更,需要进行预定模型之外新的查询操作,现有的MOLAP实例就无能为力了,只能重新进行建模和预计算。
因此,MOLAP适合业务需求比较固定,数据量较大的场景。在开源软件中,由eBay开发并贡献给Apache基金会的Kylin即属于这类OLAP引擎,支持在百亿规模的数据集上进行亚秒级查询。

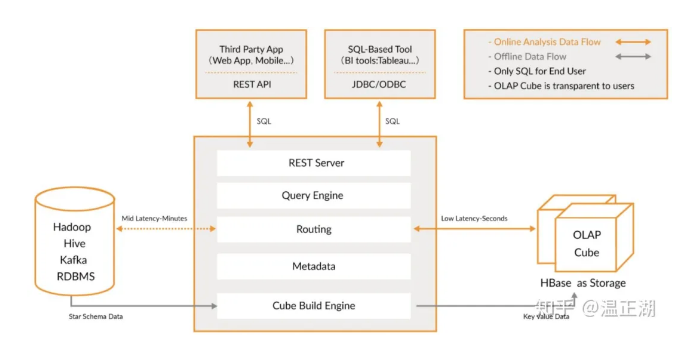
其架构图较直观得反映了基于cube的预计算模型(build),如下所示:
(2)ROLAP
与MOLAP相反,ROLAP无需预计算,直接在构成多维数据模型的事实表和维度表上进行计算。R即表示关系型(Relational)。显然,这种方式相比MOLAP更具可扩展性,增量数据导入后,无需进行重新计算,用户有新的查询需求时只需写好正确的SQL语句既能完成获取所需的结果。
但ROLAP的不足也很明显,尤其是在数据体量巨大的场景下,用户提交SQL后,获取查询结果所需的时间无法准确预知,可能秒回,也可能需要花费数十分钟甚至数小时。本质上,ROLAP是把MOLAP预计算所需的时间分摊到了用户的每次查询上,肯定会影响用户的查询体验。
当然ROLAP的性能是否能够接受,取决于用户查询的SQL类型,数据规模以及用户对性能的预期。对于相对简单的SQL,比如TPCH中的Query响应时间较快。但如果是复杂SQL,比如TPC-DS中的数据分析和挖掘类的Query,可能需要数分钟。
相比MOLAP,ROLAP的使用门槛更低,在完成星型或雪花型模型的构建,创建对应schema的事实表和维度表并导入数据后,用户只需会写出符合需求的SQL,就可以得到想要的结果。相比创建“数据立方体”,显然更加方便。
有分析表明,虽然ROLAP的性能比如MOLAP,但由于其灵活性、扩展性,ROLAP的使用者是MOLAP的数倍。
(3)HOLAP
MOLAP和ROLAP各有优缺点,而且是互斥的。如果能够将两者的优点进行互补,那么是个更好的选择。而HOLAP的出现就是这个目的,H表示混合型(Hybrid),这个想法很朴素直接。对于查询频繁而稳定但又耗时的那些SQL,通过预计算来提速;对于较快的查询、发生次数较少或新的查询需求,像ROLAP一样直接通过SQL操作事实表和维度表。
目前似乎没有开源的OLAP系统属于这个类型,一些大数据服务公司或互联网厂商,比如HULU有类似的产品。相信未来HOLAP可能会得到进一步发展,并获得更大规模的使用。
(4)HTAP
从另一个维度看,HTAP也算是一种OLAP类型的系统,是ROLAP的一个扩展,具备了OLAP的能力。最新发展显示,有云厂商在HTAP的基础上做了某种妥协,将T(transaction)弱化为S(Serving),朝HSAP方向演进。关于HTAP/HSAP,本文不做进一步展开,可自主查询其他资料。
可以发现,传统的商业厂商和闭源的云服务厂商占据了绝大部分市场。大部分系统笔者只听过而没有研究过。作为屁股在互联网公司的数据库/数据仓库开发者,本文后续主要聚焦在基于Hadoop生态发展的开源OLAP系统(SQL on Hadoop)。
二、有哪些常用的开源ROLAP产品?
目前生产环境使用较多的开源ROLAP主要可以分为两大类,一个是宽表模型,另一个是多表组合模型(就是前述的星型或雪花型)。
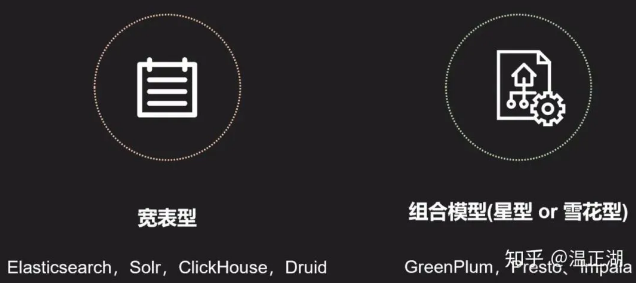
1.宽表模型
宽表模型能够提供比多表组合模型更好的查询性能,不足的是支持的SQL操作类型比较有限,比如对Join等复杂操作支持较弱或不支持。
目前该类OLAP系统包括Druid和ClickHouse等,两者各有优势,Druid支持更大的数据规模,具备一定的预聚合能力,通过倒排索引和位图索引进一步优化查询性能,在广告分析场景、监控报警等时序类应用均有广泛使用;ClickHouse部署架构简单,易用,保存明细数据,依托其向量化查询、减枝等优化能力,具备强劲的查询性能。两者均具备较高的数据实时性,在互联网企业均有广泛使用。
除了上面介绍的Druid和ClickHouse外,ElasticSearch和Solar也可以归为宽表模型。但其系统设计架构有较大不同,这两个一般称为搜索引擎,通过倒排索引,应用Scatter-Gather计算模型提高查询性能。对于搜索类的查询效果较好,但当数据量较大或进行扫描聚合类查询时,查询性能会有较大影响。
2.多表组合模型
采用星型或雪花型建模是最通用的一种ROLAP系统,常见的包括GreenPlum、Presto和Impala等,他们均基于MPP架构,采用该模型和架构的系统具有支持的数据量大、扩展性较好、灵活易用和支持的SQL类型多样等优点。
相比其他类型ROLAP和MOLAP,该类系统性能不具有优势,实时性较一般。通用系统往往比专用系统更难实现和进行优化,这是因为通用系统需要考虑的场景更多,支持的查询类型更丰富。而专用系统只需要针对所服务的某个特定场景进行优化即可,相对复杂度会有所降低。
对于ROLAP系统,尤其是星型或雪花型的系统,如果能够尽可能得缩短响应时间非常重要,这将是该系统的核心竞争力。这块内容,我们放在下一节着重进行介绍。
三、有哪些黑科技可优化ROLAP系统性能
目前生产环境使用的ROLAP系统,均实现了大部分的该领域性能优化技术,包括采用MPP架构、支持基于代价的查询优化(CBO)、向量化执行引擎、动态代码生成机制、存储空间和访问效率优化、其他cpu和内存相关的计算层优化等。下面逐一进行介绍。
什么是MPP架构?
首先来聊聊系统架构,这是设计OLAP系统的第一次分野,目前生产环境中系统采用的架构包括基于传统的MapReduce架构加上SQL层组装的系统;主流的基于MPP的系统;其他非MPP系统等。
1.MR架构及其局限
在Hadoop生态下,最早在Hive上提供了基于MapReduce框架的SQL查询服务。
但基于MR框架局限性明显,比如:
-
每个MapReduce 操作都是相互独立的,Hadoop不知道接下来会有哪些MapReduce。
-
每一步的输出结果,都会持久化到硬盘或者HDFS 上。
第一个问题导致无法进行跨MR操作间的优化,第二个问题导致MR间数据交互需要大量的IO操作。两个问题均对执行效率产生很大影响,性能较差。
2.MPP优缺点分析
MPP是massively parallel processing的简称,即大规模并行计算框架。相比MR等架构,MPP查询速度快,通常在秒计甚至毫秒级以内就可以返回查询结果,这也是为何很多强调低延迟的系统,比如OLAP系统大多采用MPP架构的原因。
下面以Impala为例,简单介绍下MPP系统架构。
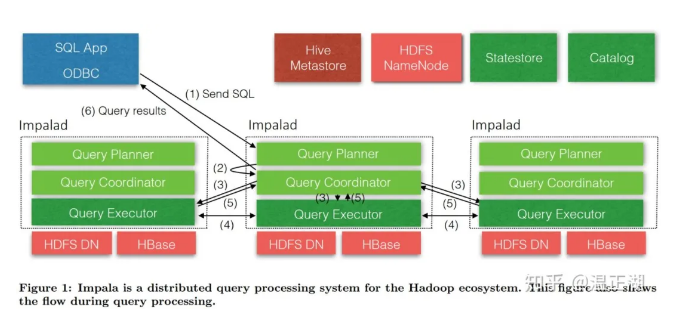
上图即为Impala架构图,展示了Impala各个组件及一个查询的执行流程。
-
用户通过Impala提供的impala-shell或beeline等客户端/UI工具向Impala节点下发查询SQL;接收该SQL的Impala节点即为Coordinator节点,该节点负责进行SQL解析;
-
首先产生基于单节点的执行计划;再对执行计划进行分布式处理,比如将Join、聚合(aggregation)等并行化到各Impala Executor节点上。执行计划被切分为多个Plan Fragment(PF),每个PF又由一到多个Operator组成;
-
接着,下发经过优化后的执行计划的PF到对应的Executor节点,多个执行节点并行处理任务,缩短整个任务所需时间;
-
执行节点扫描HDFS/Hbase等存储上的数据,并逐层进行处理,比如进行跨节点的数据shuffe,Join等操作;
-
执行节点完成任务并将输出结果统一发送到Coordinator节点;
-
Coordinator节点汇总各个执行节点数据,做最后处理,最终返回给用户想要的结果集。
3、MPP架构之所以性能比MR好
原因包括:
-
PF之间的数据交互(即中间处理结果)驻留在内存Buffer中不落盘(假设内存够大);
-
Operator和PF间基于流水线处理,不需要等上一个Operator/PF都完成后才进行下一个处理。上下游之间的关系和数据交互式预先明确的。
这样可以充分利用CPU资源,减少IO资源消耗。但事情往往是两面的,MPP并不完美,主要问题包括:
-
中间结果不落盘,在正常情况下是利好,但在异常情况下就是利空,这意味着出现节点宕机等场景下,需要重新计算产生中间结果,拖慢任务完成时间;
-
扩展性没有MR等架构好,或者说随着MPP系统节点增多到一定规模,性能无法线性提升。有个原因是“木桶效应”,系统性能瓶颈取决于性能最差的那个节点。另一个原因是规模越大,出现节点宕机、坏盘等异常情况就会越频繁,故障率提高会导致SQL重试概率提升;
基于上述分析,MPP比较适合执行时间不会太久的业务场景,比如数小时。因为时间越久,故障概率越大。
4、其他非MPP架构
基于MR系统局限性考虑,除了采用MPP架构外,Hive和Spark均使用不同方式进行了优化,包括Hive的Tez,SparkSQL基于DAG(Directed Acyclic Graph)等。
不同架构有不同优缺点,重要的是找到其适用的场景,并进行靠谱地优化,充分发挥其优势。
四、什么是基于代价的查询优化?
有了适合的系统架构并不一定能够带来正向收益,“好马配好鞍”,执行计划的好坏对最终系统的性能也有着决定性作用。执行计划及其优化,就笔者的理解来说,其来源于关系型数据库领域。这又是一门大学问,这里仅简单介绍。分布式架构使得执行计划能够进行跨节点的并行优化,通过任务粒度拆分、串行变并行等方式大大缩短执行时间。除此之外,还有2个更重要的优化方式,就是传统的基于规则优化以及更高级的基于代价优化。
1.基于规则优化
通俗来说,基于规则的优化(rule based optimization,RBO)指的是不需要额外的信息,通过用户下发的SQL语句进行的优化,主要通过改下SQL,比如SQL子句的前后执行顺序等。比较常见的优化包括谓语下推、字段过滤下推、常量折叠、索引选择、Join优化等等。
谓语下推,即PredicatePushDown,最常见的就是where条件等,举MySQL为例,MySQL Server层在获取InnoDB表数据时,将Where条件下推到InnoDB存储引擎,InnoDB过滤where条件,仅返回符合条件的数据。在有数据分区场景下,谓语下推更有效;
字段过滤下推,即ProjectionPushDown,比如某个SQL仅需返回表记录中某个列的值,那么在列存模式下,只需读取对应列的数据,在行存模式下,可以选择某个索引进行索引覆盖查询,这也是索引选择优化的一种场景;
常量或函数折叠也是一种常见的优化方式,将SQL语句中的某些常量计算(加减乘除、取整等)在执行计划优化阶段就做掉;
Join优化有很多方法,这里说的基于规则优化,主要指的是Join的实现方式,比如最傻瓜式的Join实现就是老老实实得读取参与Join的2张表的每条记录进行Join条件比对。而最普遍的优化方式就是Hash Join,显然效率很高。不要认为这是想当然应该有的功能,其实MySQL直到8.0版本才具备。另外Join的顺序及合并,有部分也可以直接通过SQL来进行判断和选择。
2.基于代价优化
基于规则的优化器简单,易于实现,通过内置的一组规则来决定如何执行查询计划。与之相对的是基于代价优化(cost based optimization,CBO)。
CBO的实现依赖于详细可靠的统计信息,比如每个列的最大值、最小值、平均值、区分度、记录数、列总和,表大小分区信息,以及列的直方图等元数据信息。
CBO的一大用途是在Join场景,决定Join的执行方式和Join的顺序。这里所说的Join我们主要是讨论Hash Join。
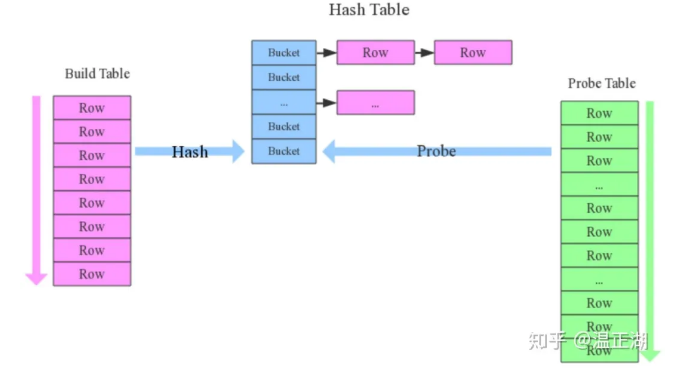
(1)Join执行方式
根据参与Join的驱动表(Build Table)和被驱动表(Probe Table)的大小,Hash Join一般可分为broadcast和partition两种。
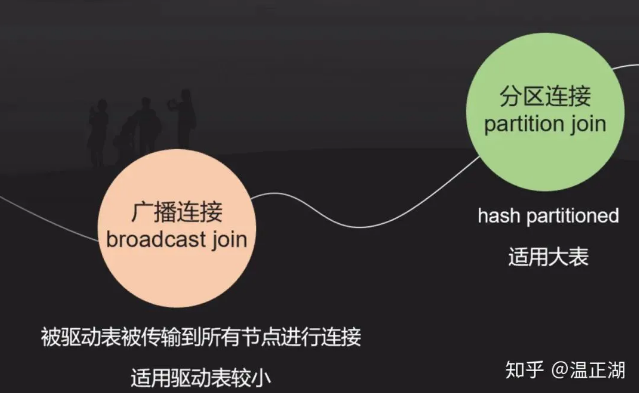
广播方式适用于大表与小表进行Join,在并行Join时,将小表广播到大表分区数据所在的各个执行节点,分别与大表分区数据进行Join,最后返回Join结果并汇总。
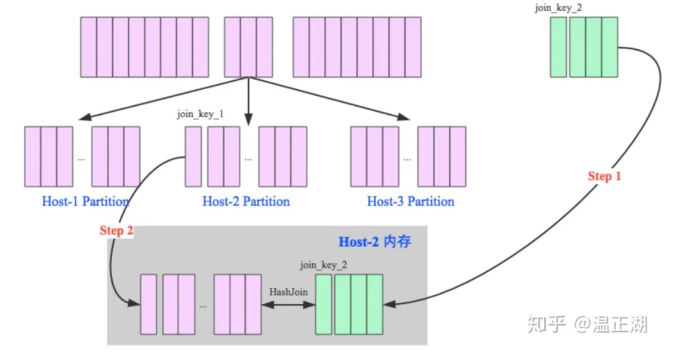
而分区方式是最为一般的模式,适用于大表间Join或表大小未知场景。分别将两表进行分区,每个分区分别进行Join。
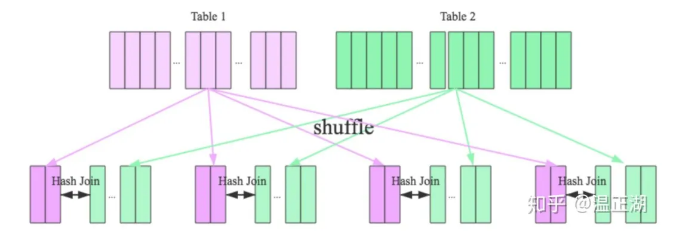
显然,判断大小表的关键就看是否能够通过某种方式获取表的记录数,如果存储层保存了记录数,那么可从元数据中直接获取。
如果Join的两表都是大表,但至少有个表是带Where过滤条件的,那么在决定走分区方式前还可进一步看满足条件的记录数,这时候,物理上进行分区的表存储方式可发挥作用,可以看每个分区的最大值和最小值及其记录数来估算过滤后的总记录数。当然,还有种更精确的方式是列直方图,能够直接而直观得获取总记录数。
如果上述的统计信息都没有,要使用CBO还有另一种方式就是进行记录的动态采样来决定走那种Join方式。
(2)Join顺序
如果一个查询的SQL中存在多层Join操作,如何决定Join的顺序对性能有很大影响。这块也已是被数据库大佬们充分研究过的技术。
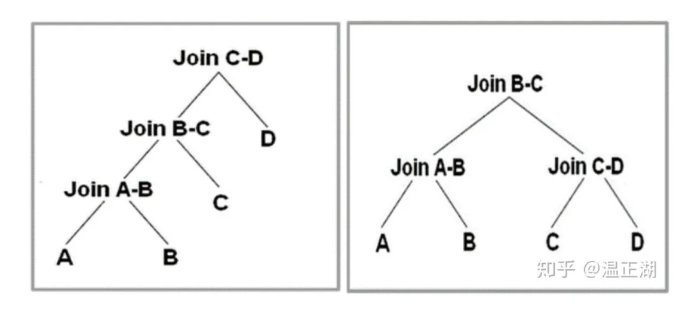
一个好的CBO应该能够根据SQL 语句的特点,来自动选择使用Left-deep tree(LDT,左图)还是 bushy tree(BYT,右图)执行join。
两种Join顺序没有好坏之分,关键看进行Join的表数据即Join的字段特点
对于LDT,如果每次Join均能够过滤掉大量数据,那么从资源消耗来看,显然是更优的。对于给每个列都构建了索引的某些系统,使用LDT相比BYT更好。
一般来说,选择BYT是效率更高的模式,通过串行多层Join改为并行的更少层次Join,可以发挥MPP架构的优势,尽快得到结果,在多表模式ROLAP场景常采用。
为什么需要向量化执行引擎?其与动态代码生成有何关系?
查询执行引擎 (query execution engine) 是数据库中的一个核心组件,用于将查询计划转换为物理计划,并对其求值返回结果。查询执行引擎对系统性能影响很大,在一项针对Impala和Hive的对比时发现,Hive在某些简单查询上(TPC-H Query 1)也比Impala慢主要是因为Hive运行时完全处于CPU bound的状态中,磁盘IO只有20%,而Impala的IO至少在85%。
什么原因导致这么大的差别呢?首先得简单说下火山模型的执行引擎。
(3)火山模型及其缺点
火山模型(Volcano-style execution)是最早的查询执行引擎,也叫做迭代模型 (iterator model),或 one-tuple-at-a-time。在这种模型中,查询计划是一个由operator组成的DAG,其中每一个operator 包含三个函数:open,next,close。Open 用于申请资源,比如分配内存,打开文件,close 用于释放资源,next方法递归的调用子operator的 next方法生成一个元组(tuple,即行row在物理上的表示)。
下图描述了“select sum(C1) from T1 where C2 > 15”的查询计划,该查询计划包含Project,HashAgg,Scan等operator,每个 operator的next方法递归调用子节点的 next,一直递归调用到叶子节点Scan operator,Scan operator的next 从文件中返回一个元组。
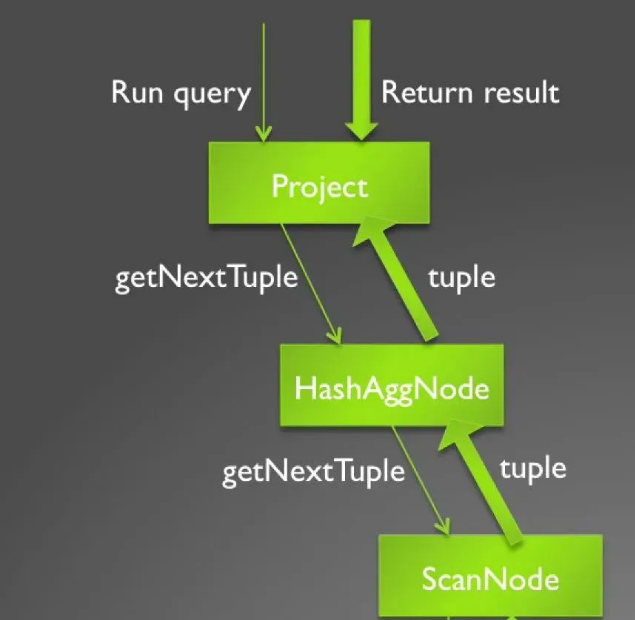
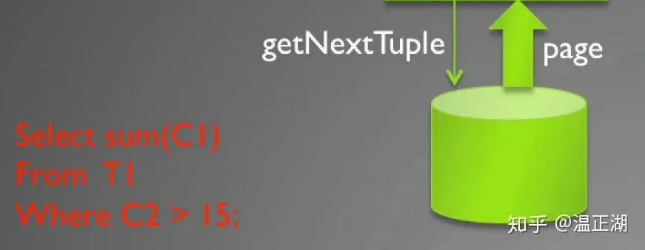
其缺点主要在于:
-
大量虚函数调用:火山模型的next方法通常实现为一个虚函数,在编译器中,虚函数调用需要查找虚函数表, 并且虚函数调用是一个非直接跳转 (indirect jump), 会导致一次错误的CPU分支预测 (brance misprediction), 一次错误的分支预测需要十几个周期的开销。火山模型为了返回一个元组,需要调用多次next 方法,导致昂贵的函数调用开销
-
类型装箱:对于a + 2 * b之类表达式,由于需要对不同数据类型的变量做解释,所以在Java中需要把这些本来是primitive(如int等类型)的变量包装成Object,但执行时又需要调用具体类型的实现函数,这本质上也是虚函数调用的效率问题;
-
CPU Cache利用效率低:next方法一次只返回一个元组,元组通常采用行存储,如果仅需访问第一列而每次均将一整行填入CPU Cache,将导致Cache Miss;
-
条件分支预测失败:现在的CPU都是有并行流水线的,但是如果出现条件判断会导致无法并行。比如判断数据的类型(是string还是int),或判断某一列是否因为其他字段的过滤条件导致本行不需要被读取等场景;
-
CPU与IO性能不匹配:每次从磁盘读取一个行数据,经过多次调用交给CPU进行处理,显然,大部分时间都是CPU等待数据就绪,导致CPU空转。
通过上述描述,可以得出解决问题的基本方法。可以将问题分为2大类,分别用下述的向量化引擎和动态代码生成技术来解决。
(4)向量化执行引擎
向量化执行以列存为前提,主要思想是每次从磁盘上读取一批列,这些列以数组形式组织。每次next都通过for循环处理列数组。这么做可以大幅减少next的调用次数。相应的CPU的利用率得到了提高,另外数据被组织在一起。可以进一步利用CPU硬件的特性,如SIMD,将所有数据加载到CPU的缓存当中去,提高缓存命中率,提升效率。在列存储与向量化执行引擎的双重优化下,查询执行的速度会有一个非常巨大的飞跃。
动态代码生成
向量化执行减少CPU等待时间,提高CPU Cache命中率,通过减少next调用次数来缓解虚函数调用效率问题。而动态代码生成,则是进一步解决了虚函数调用问题。
动态代码生成技术不使用解释性的统一代码,而是直接生成对应的执行语言的代码并直接用primitive type。对于判断数据类型造成的分支判断,动态代码的效果可以消除这些类型判断,使用硬件指令来进一步提高循环处理效率。
具体实现来说,JVM系如Spark SQL,Presto可以用反射,C++系的Impala则使用了llvm生成中间码。相对来说,C++的效率更高。
向量化和动态代码生成技术往往是一起工作达到更好的效果。
都有哪些存储空间和访问效率优化方法?
存储和IO模块的优化方法很多,这里我们还是在Hadoop生态下来考虑,当然,很多优化方法不是Hadoop特有的,而是通用的。OLAP场景下,数据存储最基础而有效的优化是该行存储为列存储,下面讨论的优化措施均基于列存。
(5)数据压缩和编码
数据压缩是存储领域常用的优化手段,以可控的CPU开销来大幅缩小数据在磁盘上的存储空间,一来可以节省成本,二来可以减小IO和数据在内存中跨线程和跨节点网络传输的开销。目前在用的主流压缩算法包括zlib、snappy和lz4等。压缩算法并不是压缩比越高越好,压缩率越高的算法压缩和解压缩速度往往就越慢,需要根据硬件配置和使用场景在cpu 和io之间进行权衡。
数据编码可以理解为轻量级压缩,包括RLE和数据字典编码等。
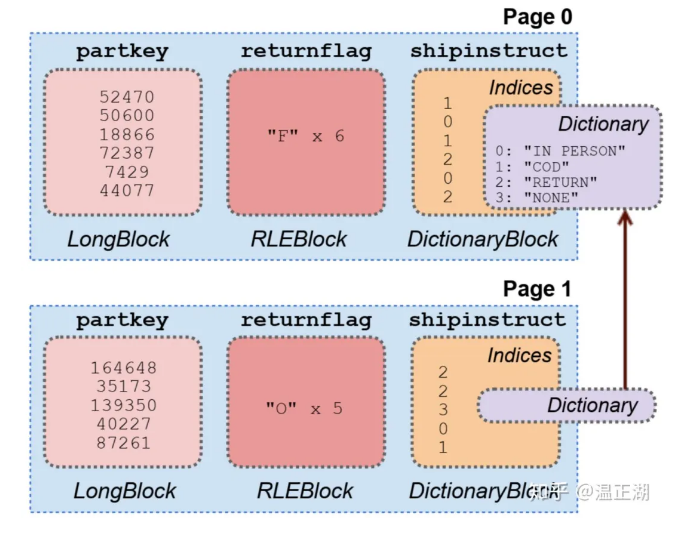
上图截至Presto论文,展示了RLE编码和数据字典编码的使用方式。RLE用在各列都是重复字符的情况,比如page0中6行记录的returnflag都是"F"。数据字典可高效使用在区分度较低的列上,比如列中只有几种字符串的场景。考虑到同个表的列的值相关性,数据字典可以跨page使用。
与数据压缩相比,数据编码方式在某些聚合类查询场景下,无需对数据进行解码,直接返回所需结果。比如假设T1表的C1列为某个字符,RLE算法将16个C1列的值“aaaaaabbccccaaaa”编码为6a2b4c4a,其中6a表示有连续6个字符a。当执行 select count(*) from T1 where C1=’a’时,不需要解压6a2b4c4a,就能够知道这16行记录对应列值为a有10行。
在列存模式下,数据压缩和编码的效率均远高于行存。
(6)数据精细化存储
所谓数据精细化存储,是通过尽可能多得提供元数据信息来减少不必要的数据扫描和计算,常用的方法包括但不限于如下几种:
-
数据分区:数据分区可用于将表中数据基于hash或range打散到多个存储节点上,配合多副本存储。可以提高数据容灾和迁移效率。除此之外,在查询时可以快速过滤掉不符合where条件要求的数据分区,无需逐列读取数据进行判断。
-
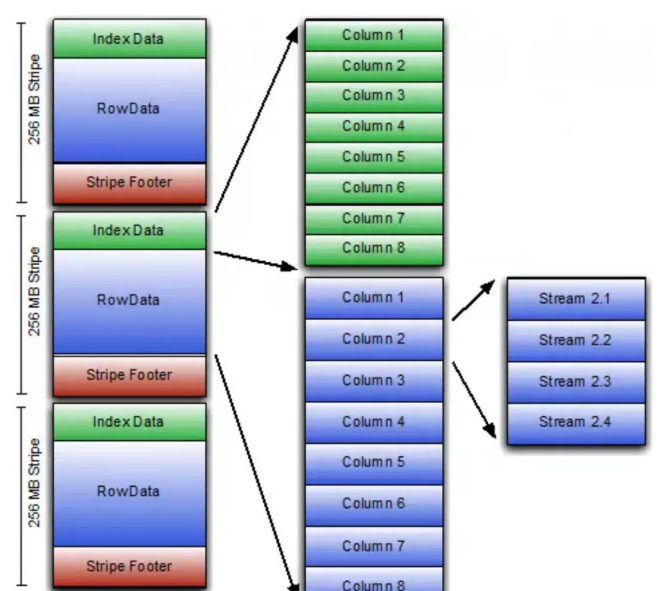
行组:与数据分区类似,Hadoop中常用的parquet和orcfile还将表数据分为多个行组(row group),每个行组内的记录按列存储。这样即达到列存提高OLAP查询效率,同时能够兼顾查询多行的需求;
-
局部索引:在数据分区或行组上创建索引,可以提高查询效率。如下图所示,orcfile在每个行组的头部维护了Index Data来,保存最大值和最小值等元数据,基于这些信息可以快速决定是否需扫描该行组。某些OLAP系统进一步丰富了元数据信息,比如建立该行组记录的倒排索引或B+树索引,进一步提高扫描和查询效率。
-
富元数据:除了提供最大值和最小值信息外,还可进一步提供平均值、区分度、记录数、列总和,表大小分区信息,以及列的直方图等元数据信息。
(7)数据本地化访问
数据本地化读写是常见的优化方法,在Hadoop下也提供了相应的方式。
一般来说,读HDFS上的数据首先需要经过NameNode获取数据存放的DataNode信息,在去DataNode节点读取所需数据。
对于Impala等OLAP系统,可以通过HDFS本地访问模式进行优化,直接读取磁盘上的HDFS文件数据。HDFS这个特性称为"Short Circuit Local Reads",其相关的配置项(在hdfs-site.xml中)如下:
<property> <name>dfs.client.read.shortcircuit</name> <value>true</value> </property> <property> <name>dfs.domain.socket.path</name> <value>/var/lib/hadoop-hdfs/dn_socket</value> </property> br
其中:dfs.client.read.shortcircuit是打开这个功能的开关,dfs.domain.socket.path是Datanode和DFSClient之间沟通的Socket的本地路径。
(8)运行时数据过滤
这是少部分OLAP系统才具有的高级功能,比如Impala的RunTime Filter(RF)运行时过滤,和SparkSQL 3.0的 Dynamic Partition Pruning动态分区裁剪,可以将驱动表的bloomfilter(BF)或过滤条件作用在被驱动表的数据扫描阶段,从而极大减少需扫描/返回的数据量。下面分别用一个图进行简述,在后续分析具体OLAP系统时再详述。
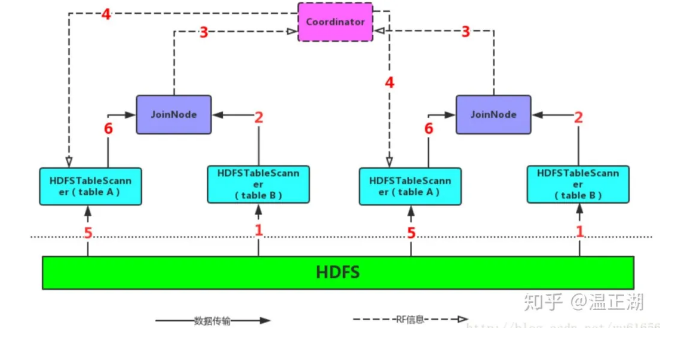
上图直观得展示了Impala runtime filter的实现。流程如下:
-
同时下发两个表的SCAN操作。左边是大表,右边是小表(相对而言,也有可能是同等级别的),但是左表会等待一段时间(默认是1s),因此右表的SCAN会先执行;
-
右表的扫描的结果根据join键哈希传递扫不同的Join节点,由Join节点执行哈希表的构建和RF的构建;
-
Join节点读取完全部的右表输入之后也完成了RF的构建,它会将RF交给Coordinator节点(如果是Broadcast Join则会直接交给左表的Scan节点);
-
Coordinator节点将不同的RF进行merge,也就是把Bloom Filter进行merge,merge之后的Bloom Filter就是一个GLOBAL RF,它将这个RF分发给每一个左表Scan;
-
左表会等待一段时间(默认1s)再开启数据扫描,为了是尽可能的等待RF的到达,但是无论RF什么时候到达,RF都会在到达那一刻之后被应用;
-
左表使用RF完成扫描之后同样以Hash方式交给Join节点,由Join节点进行apply操作,以完成整个Join过程。
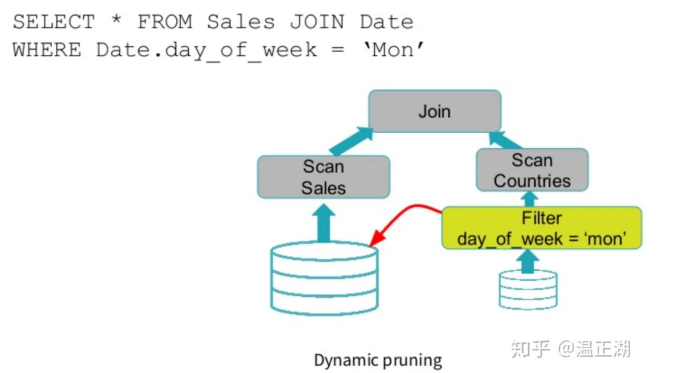
sparksql图1(官方这个图有误,右边应该是Scan Date)

sparksql图2上面2幅图是SparkSQL 3.0的动态分区裁剪示意图。将右表的扫描结果(hashtable of table Date after filter)广播给左表的Join节点,在进行左表扫描时即使用右表的hashtable进行条件数据过滤。
除了上面这些,还有其他优化方法吗?
还有个极为重要的技术是集群资源管理和调度。Hadoop使用YARN进行资源调度,虽然带来了很大遍历,但对性能要求较高的OLAP系统却有些不适合。
如启动AppMaster和申请container会占用不少时间,尤其是前者,而且container的供应如果时断时续,会极大的影响时效性。
目前的优化方法主要包括让AppMaster启动后长期驻守,container复用等方式。让资源在需要用时已经就位,查询无需等待即可马上开始。
五、最后做个总结
本文主要是想阐述下自己对数仓和OLAP系统的理解,之所以采用问答形式,是因为笔者就是带着这些问题去google网上或公司内部的资料,或者直接请教在这个领域的大佬。由于水平有限,难免有所错误,非常欢迎大家看后能够指出。
专业的数据分析软件旨在帮助企业提供从内外部数据源整合、数据治理到探索式分析,以及最终实现智能化决策的大数据分析能力,助力企业构建数据生态系统,帮助企业降本增收和实现数据资产的变现。
ref : https://mp.weixin.qq.com/s/XmtCCuzH4Z8DdxZQMtGecw

 浙公网安备 33010602011771号
浙公网安备 33010602011771号