
Hive 架构
一、Hive 架构
下面是Hive的架构图

Hive的体系结构可以分为以下几部分:
1、用户接口主要有三个:CLI,Client 和 WUI。其中最常用的是CLI,Cli启动的时候,会同时启动一个Hive副本。Client是Hive的客户端,用户连接至Hive Server。
在启动 Client模式的时候,需要指出Hive Server所在节点,并且在该节点启动Hive Server。 WUI是通过浏览器访问Hive。
2、Hive将元数据存储在数据库中,如mysql、derby。Hive中的元数据包括表的名字,表的列和分区及其属性,表的属性(是否为外部表等),表的数据所在目录等。
3、解释器、编译器、优化器完成HQL查询语句从词法分析、语法分析、编译、优化以及查询计划的生成。生成的查询计划存储在HDFS中,并在随后有MapReduce调用执行。
4、Hive的数据存储在HDFS中,大部分的查询、计算由MapReduce完成(包含*的查询,比如select * from tbl不会生成MapRedcue任务)。
二、元数据存储
Hive将元数据存储在RDBMS中,有三种模式可以连接到数据库:
1、元数据库内嵌模式:此模式连接到一个In-memory 的数据库Derby,一般用于Unit Test。
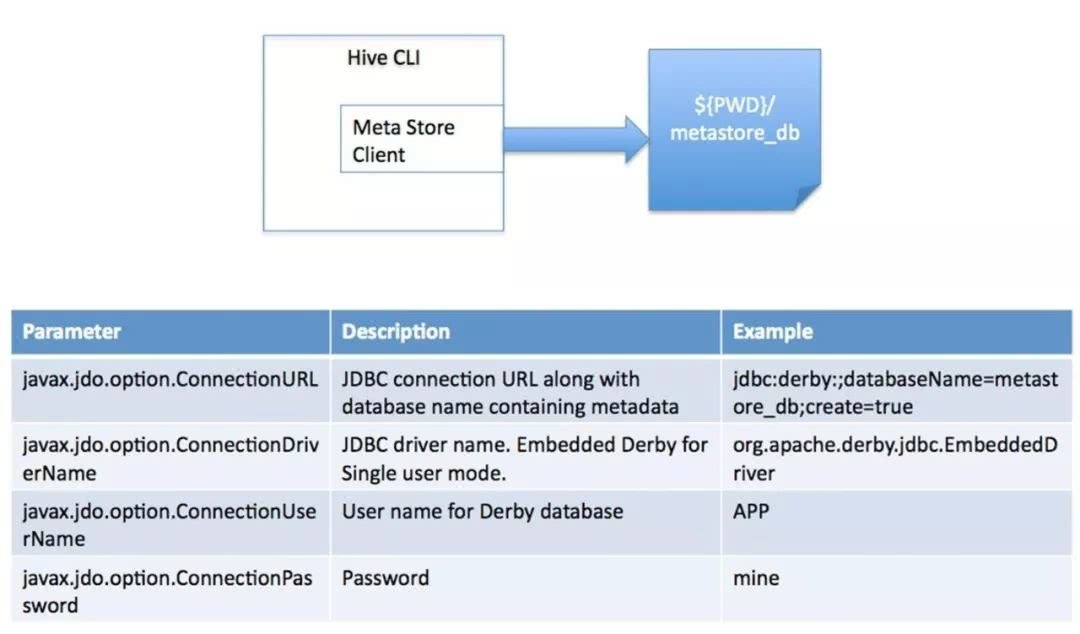
2、元数据库mysql模式:通过网络连接到一个数据库中,是最经常使用到的模式。
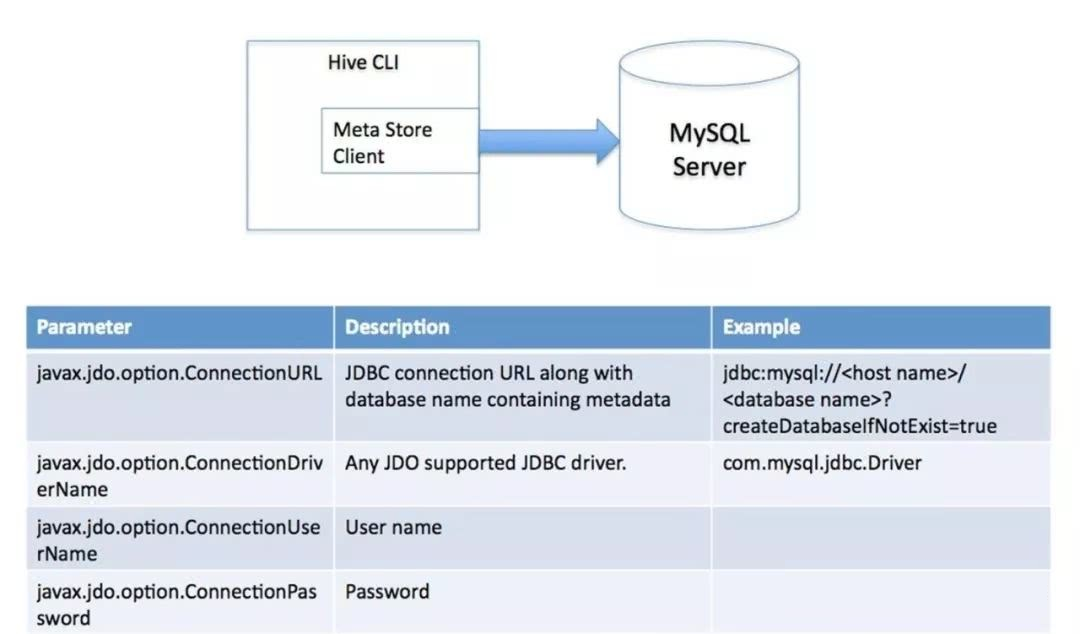
3、MetaStoreServe访问元数据库模式:用于非Java客户端访问元数据库,在服务器端启动MetaStoreServer,客户端利用Thrift协议通过MetaStoreServer访问元数据库。

对于数据存储,Hive没有专门的数据存储格式,也没有为数据建立索引,用户可以非常自由的组织Hive中的表,只需要在创建表的时候告诉Hive数据中的列分隔符和行分隔符,Hive就可以解析数据。
Hive中所有的数据都存储在HDFS中,存储结构主要包括数据库、文件、表和视图。Hive中包含以下数据模型:Table内部表,External Table外部表,Partition分区,Bucket桶。
Hive默认可以直接加载文本文件,还支持sequence file 、RCFile。
4、三种模式汇总:
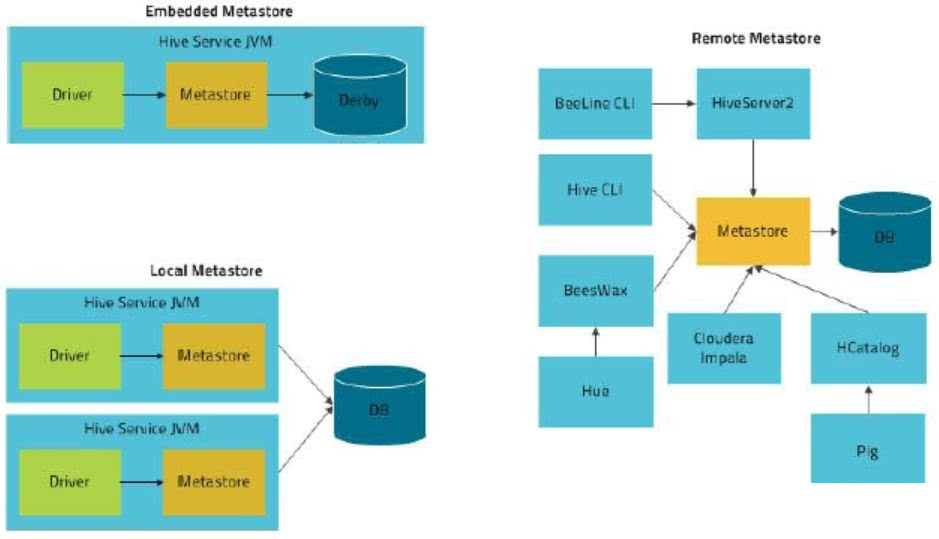
ref: https://cloud.tencent.com/developer/news/362488

 浙公网安备 33010602011771号
浙公网安备 33010602011771号