

Kafka Broker
Broker
处理请求流程

在Kafka的架构中,会有很多客户端向Broker端发送请求,Kafka 的 Broker 端有个 SocketServer 组件,用来和客户端建立连接,然后通过Acceptor线程来进行请求的分发,
由于Acceptor不涉及具体的逻辑处理,非常得轻量级,因此有很高的吞吐量。
接着Acceptor 线程采用轮询的方式将入站请求公平地发到所有网络线程中,网络线程池默认大小是 3个,表示每台 Broker 启动时会创建 3 个网络线程,
专门处理客户端发送的请求,可以通过Broker 端参数 num.network.threads来进行修改。
那么接下来处理网络线程处理流程如下:
当网络线程拿到请求后,会将请求放入到一个共享请求队列中。Broker 端还有个 IO 线程池,负责从该队列中取出请求,执行真正的处理。
如果是 PRODUCE 生产请求,则将消息写入到底层的磁盘日志中;如果是 FETCH 请求,则从磁盘或页缓存中读取消息。
IO 线程池处中的线程是执行请求逻辑的线程,默认是8,表示每台 Broker 启动后自动创建 8 个 IO 线程处理请求,可以通过Broker 端参数 num.io.threads调整。
Purgatory组件是用来缓存延时请求(Delayed Request)的。比如设置了 acks=all 的 PRODUCE 请求,一旦设置了 acks=all,那么该请求就必须等待 ISR 中所有副本都接收了消息后才能返回,此时处理该请求的 IO 线程就必须等待其他 Broker 的写入结果。
控制器
在 Kafka 集群中会有一个或多个 broker,其中有一个 broker 会被选举为控制器(Kafka Controller),它负责管理整个集群中所有分区和副本的状态。
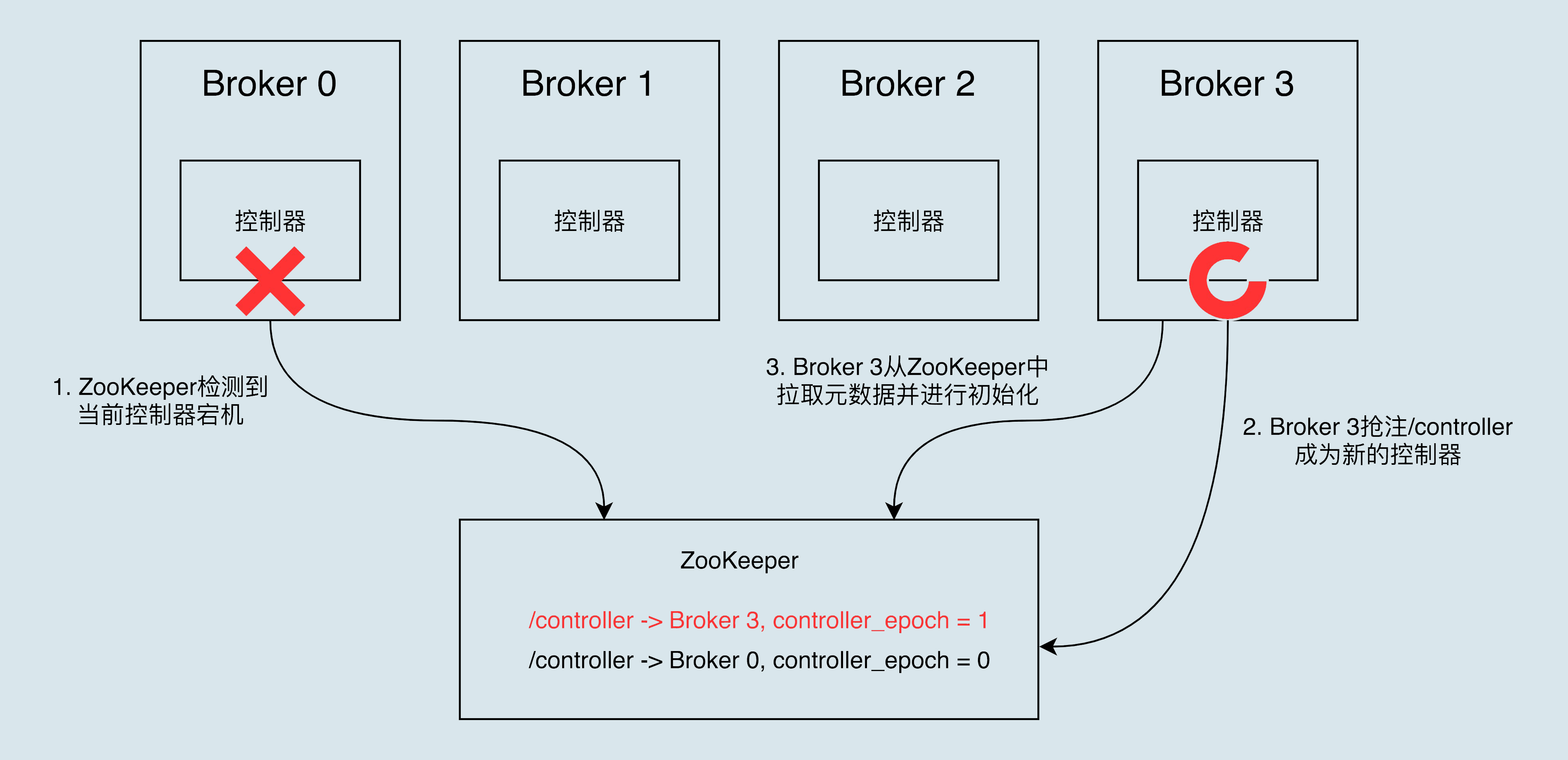
Broker 在启动时,会尝试去 ZooKeeper 中创建 /controller 节点。Kafka 当前选举控制器的规则是:第一个成功创建 /controller 节点的 Broker 会被指定为控制器。
controller_epoch
在ZooKeeper中的 /controller_epoch 节点中存放的是一个整型的 controller_epoch 值。
controller_epoch 用于记录控制器发生变更的次数,即记录当前的控制器是第几代控制器,我们也可以称之为“控制器的纪元”。
controller_epoch 的初始值为1,即集群中第一个控制器的纪元为1,当控制器发生变更时,每选出一个新的控制器就将该字段值加1。
Kafka 通过 controller_epoch 来保证控制器的唯一性,进而保证相关操作的一致性。
每个和控制器交互的请求都会携带 controller_epoch 这个字段,如果请求的 controller_epoch 值小于内存中的 controller_epoch 值,则认为这个请求是向已经过期的控制器所发送的请求,
那么这个请求会被认定为无效的请求。
如果请求的 controller_epoch 值大于内存中的 controller_epoch 值,那么说明已经有新的控制器当选了。
-
主题管理(创建、删除、增加分区)
-
分区重分配
-
Preferred 领导者选举
Preferred 领导者选举主要是 Kafka 为了避免部分 Broker 负载过重而提供的一种换 Leader 的方案。 -
集群成员管理(新增 Broker、Broker 主动关闭、Broker 宕机)
控制器组件会利用 Watch 机制检查 ZooKeeper 的 /brokers/ids 节点下的子节点数量变更。目前,当有新 Broker 启动后,它会在 /brokers 下创建专属的 znode 节点。
一旦创建完毕,ZooKeeper 会通过 Watch 机制将消息通知推送给控制器,这样,控制器就能自动地感知到这个变化,进而开启后续的新增 Broker 作业。
-
数据服务
控制器上保存了最全的集群元数据信息。
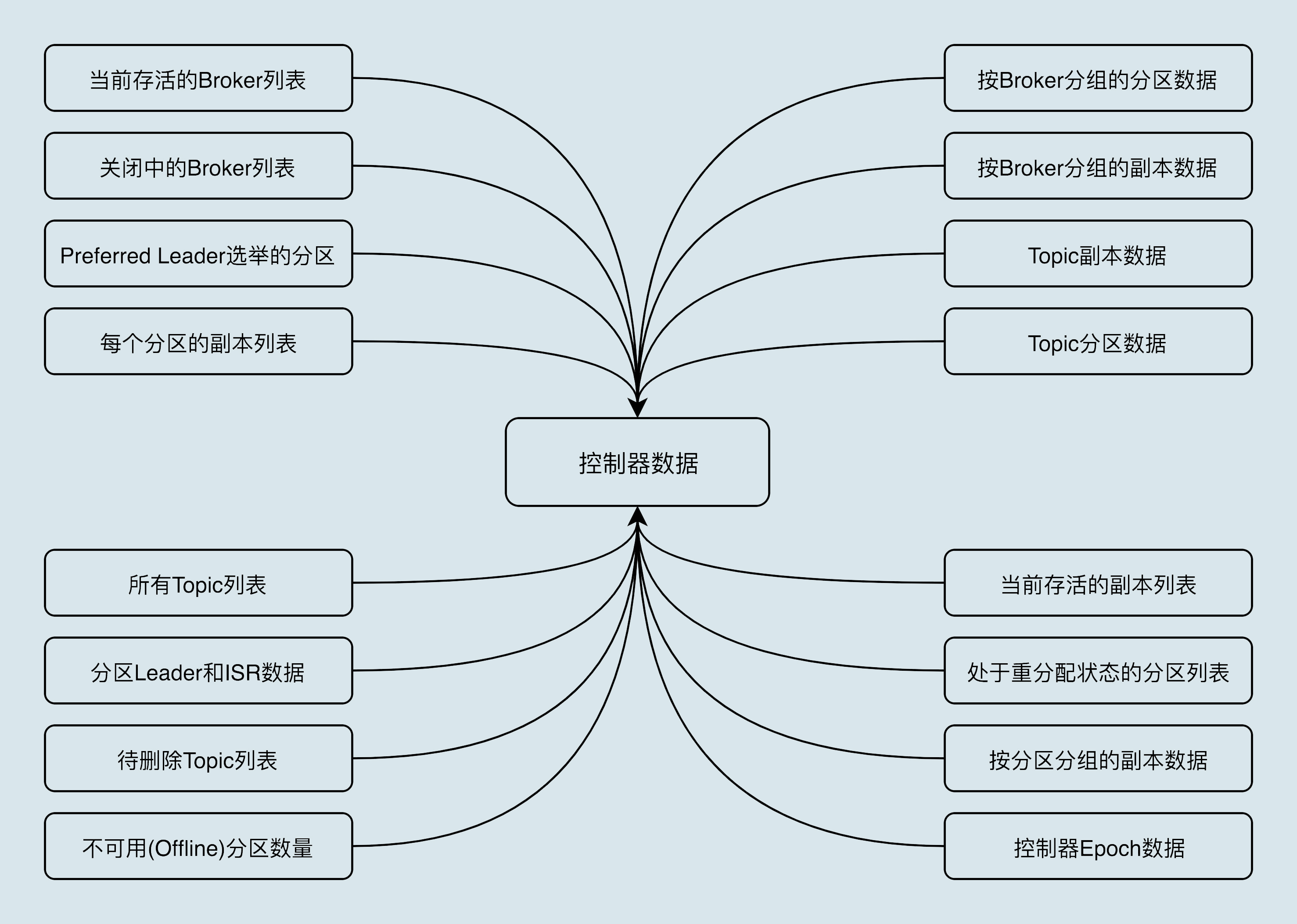
当运行中的控制器突然宕机或意外终止时,Kafka 能够快速地感知到,并立即启用备用控制器来代替之前失败的控制器。
这个过程就被称为 Failover,该过程是自动完成的,无需你手动干预。
ref:
https://www.cnblogs.com/luozhiyun/p/12443889.html

 浙公网安备 33010602011771号
浙公网安备 33010602011771号