return code 3 from org.apache.hadoop.hive.ql.exec.spark.SparkTask. Spark job failed during runtime. Please check stacktrace for the root cause.
运行时Spark作业失败。请检查堆栈跟踪查找根本原因。
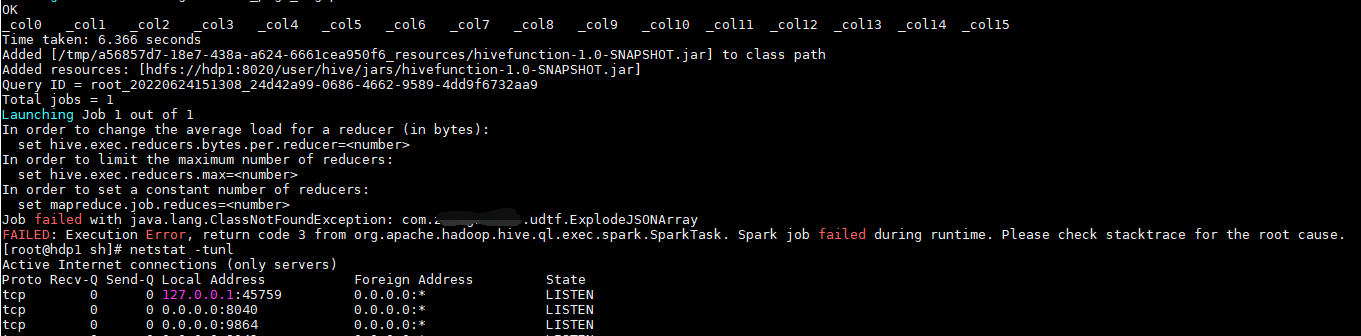
解决方法:增加ApplicationMaster资源比例
容量调度器对每个资源队列中同时运行的 Application Master 占用的资源进行了限制,
该限制通过 yarn.scheduler.capacity.maximum-am-resource-percent 参数实现,其默认值是 0.1,
表示每个资源队列上 Application Master 最多可使用的资源为该队列总资源的 10%,目的是防止大部分资源都被 Application Master 占用,而导致 Map/Reduce Task 无法执行。
生产环境该参数可使用默认值。但学习环境,集群资源总数很少,如果只分配 10%的
资源给 Application Master,则可能出现,同一时刻只能运行一个 Job 的情况,因为一个
Application Master 使用的资源就可能已经达到 10%的上限了。故此处可将该值适当调大。
(1)在 hadoop102 的/opt/module/hadoop-3.1.3/etc/hadoop/capacity-scheduler.xml 文件中
修改如下参数值
[bawei@hadoop102 hadoop]$ vim capacity-scheduler.xml
<property>
<name>yarn.scheduler.capacity.maximum-am-resource-percent</name>
<value>0.8</value>
</property
(2)分发 capacity-scheduler.xml 配置文件
[bawei@hadoop102 hadoop]$ xsync capacity-scheduler.xml
(3)关闭正在运行的任务,重新启动 yarn 集群
[bawei@hadoop103 hadoop-3.1.3]$ sbin/stop-yarn.sh
[bawei@hadoop103 hadoop-3.1.3]$ sbin/start-yarn.sh
然而!!!问题并没有解决,我在hive里面各种查找,就是没找到这个函数在哪里,查也查不到,已知我使用了下列方式,请找出bug
我的函数名字为:explode_json_array
我查询的方式为: show functions like "e*";
show functions;
均没有看到和我函数长的一样的
然后就是删除创建删除创建,甚至我怀疑我的jar有问题,重新写了一个,然后!!!还是查不到,后面我用的都是like 查询。
但是:它能用了!!!
结论:猜测我之前在默认库创建过一次,然后在这个仓库又创建了一次。导致出现概率问题,找不到了。
其实,不是我没查到,是它穿了马甲。
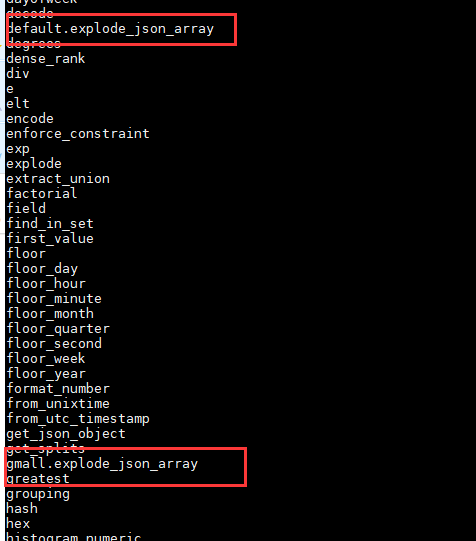 所以,创建函数一定要加数据库名字!!!
所以,创建函数一定要加数据库名字!!!
我有一杯酒,足以慰风尘。


