大数据 基础配置 (jdk,hadoop,zookeeper,kafka)
版本如下:

jdk: jdk1.8.0_131 mysql: 5.5.54 hadoop: 2.8.1 zookeeper:3.4.10 kafka: 2.11-2.4.1
网盘链接 链接: https://pan.baidu.com/s/1XUhqSbKnzREBOTo5W_gl1Q 提取码: rfp8
安装jdk :linux安装jdk-8u65-linux-x64.tar.gz - 御本美琴初号机 - 博客园 (cnblogs.com)
安装hadoop:linux配置hadoop伪集群 - 御本美琴初号机 - 博客园 (cnblogs.com)
安装zookeeper:
zookeeper-3.4.10.tar.gz
1.上传至opt目录下解压
tar -zxvf zookeeper-3.4.10.tar.gz
2.进入zookeeper ,创建存储数据的文件夹

3.进入conf目录

[root@hdp1 conf]# mv zoo_sample.cfg zoo.cfg
vim zoo.cfg
dataDir=/opt/zookeeper-3.4.10/data (存储数据地址)
在文件下面添加 hdp1 2 3 为主机名称
4.vim data 预先创建好的文件夹
vim myid (存储zookeeper的编号) 写入 1
5.分发到虚拟机2和3
为了方便,我是用脚本进行分发,由于使用的是最小安装的linux,所以无法使用第一种,在这里两种方法都列出,大家自己选择
##第一种 #!/bin/sh # 获取输入参数个数,如果没有参数,直接退出 pcount=$# if((pcount==0)); then echo no args...; exit; fi # 获取文件名称 p1=$1 fname=`basename $p1` echo fname=$fname # 获取上级目录到绝对路径 pdir=`cd -P $(dirname $p1); pwd` echo pdir=$pdir # 获取当前用户名称 user=`whoami` # 循环 for((host=2; host<=3; host++)); do echo $pdir/$fname $user@slave$host:$pdir echo ==================slave$host================== rsync -rvl $pdir/$fname $user@hdp$host:$pdir done #Note:这里的slave对应自己主机名,需要做相应修改。另外,for循环中的host的边界值
使用方法为 : 先给文件执行权限,然后在后面加上参数
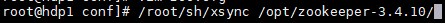
第二种:也是最小安装使用的方法,使用scp
scp -r zookeeper-3.4.10/ root@hdp2:$PWD hdp2 为要分发到的虚拟机
6.修改分发好的虚拟机myid
进入到我们之前创建的文件data下的myid中 依次修改标号为2、3 根据你的虚拟机数量而定
7.启动zookeeper
/opt/zookeeper-3.4.10/bin/zkServer.sh start (开启) /opt/zookeeper-3.4.10/bin/zkServer.sh stop (关闭) 为了方便也可以使用脚本 /opt/zookeeper-3.4.10/bin/zkServer.sh $1 ssh hdp2 "source /etc/profile;/opt/zookeeper-3.4.10/bin/zkServer.sh $1" ssh hdp3 "source /etc/profile;/opt/zookeeper-3.4.10/bin/zkServer.sh $1"
8.查看是否启动成功
使用jps即可查看
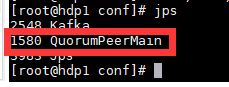
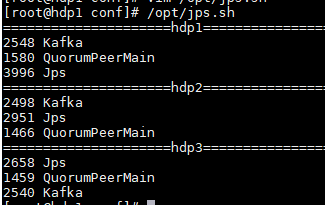
也可以使用脚本查看所有虚拟机正在运行的状态
echo "=====================hdp1===================" jps echo "=====================hdp2===================" ssh hdp2 "source /etc/profile; jps" echo "=====================hdp3===================" ssh hdp3 "source /etc/profile; jps"
安装kafka:
kafka_2.11-2.4.1
1.解压到opt
2.修改配置文件
vim kafka_2.12-1.0.0/config --> server.properties broler.id=0 标志当前机器在集群中的唯一标识 别的虚拟机依次配置 listeners=PLAINTEXT://hdp1:9092 提供的地址 依次修改 log.dirs=/opt/kafka_2.11-2.4.1/kafka_logs 设置日志地址 zookeeper.connect=hdp1:2181,hdp2:2181,hdp3:2181 \#删除topic功能使能 没有就添加 delete.topic.enable=true
3.分发并修改
还有两台机器 scp -r /opt/kafka_2.11-2.4.1/ root@hdp2:$PWD scp -r /opt/kafka_2.11-2.4.1/ root@hdp2:$PWD
更改hdp2和hdp3中broler.id,listeners,使id唯一,listener对应各节点ip
4.简单使用 ,cd 到kafka的bin目录下
启动关闭服务
./kafka-server-start.sh -daemon ../config/server.properties
./kafka-server-stop.sh -daemon ../config/server.properties
创建主题 test
./kafka-topics.sh --bootstrap-server hdp1:9092,hdp2:9092,hdp3:9092 --create --topic test
创建一个分区,一个副本
./kafka-topics.sh --create --zookeeper 192.168.224.111:2181 --partitions 1 -- replication-factor 1 --topic test
查看主题
./kafka-topics.sh --bootstrap-server hdp1:9092,hdp2:9092,hdp3:9092 --list
删除主题
./kafka-topics.sh --bootstrap-server hdp1:9092,hdp2:9092,hdp3:9092 --delete --topic test
启动生产者
./kafka-console-producer.sh --broker-list hdp1:9092,hdp2:9092,hdp3:9092 --topic test
启动消费者
./kafka-console-consumer.sh --bootstrap-server hdp1:9092,hdp2:9092,hdp3:9092 --topic test
需要注意,应该先启动zookeeper在启动kafka,关闭时也应该先关闭kafka再关闭zookeeper
我有一杯酒,足以慰风尘。


