


Howdy friends!
In this blog post, I show how Kudu, a new random-access datastore, can be made to function as a more flexible queueing system with nearly as high throughput as Kafka.
One of the more exciting recent developments in data processing is the rise of high-throughput message queues. Systems like Apache Kafka allow you to share data between different parts of your infrastructure: for example, changes in your production database can be replicated easily and reliably to your full-text search index and your analytics data warehouse, keeping everything in sync. If you’re interested in more detail of how this all works, this tome is your jam.
The key advantage is that these systems have enough throughput that you can just replicate everything and let each consumer filter down the data its interested in. But in achieving this goal, Kafka has made some tradeoffs that optimize for throughput over flexibility and availability. This means that many use cases, such as maintaining a queue per-user or modifying queue elements after enqueue, are hard or impossible to implement using Kafka. That’s where Kudu comes in.
Contents:
- What’s Apache Kafka?
- What’s Apache Kudu?
- Kudu as a Kafka replacement
- The mechanics of making Kudu act like a Kafka-style message queue
- Results
- Reasons you might not want to do this in production just yet/Further work
What’s Apache Kafka?
![]()
Apache Kafka is a message queue implemented as a distributed commit log. There’s a good introductionon their site, but the takeaway is that from the user’s point of view, you log a bunch of messages (Kafka can handle millions/second/queue), and Kafka holds on to them while one or more consumers process them. Unlike traditional message queues, Kafka pushes the responsibility of keeping track of which messages have been read to the reader, which allows for extremely high throughput and low overhead on the message broker. Kafka has quickly become indispensable for most internet-scale companies’ analytics platform.
What’s Apache Kudu?
![]()
Apache Kudu (incubating) is a new random-access datastore. Its interface is similar to Google Bigtable,Apache HBase, or Apache Cassandra. Like those systems, Kudu allows you to distribute the data over many machines and disks to improve availability and performance. Unlike Bigtable and HBase, Kudu layers directly on top of the local filesystem rather than GFS/HDFS. Unlike Cassandra, Kudu implements the Raft consensus algorithm to ensure full consistency between replicas. And unlike all those systems, Kudu uses a new compaction algorithm that’s aimed at bounding compaction time rather than minimizing the numbers of files on disk.
Kudu as a Kafka replacement
So the proposal is to make Kudu (a random-access datastore) act like Kafka (a messaging queue). Why would any arguably sane person want to do this? Those of you who aren’t familiar with the space but have gamely made it this far are likely wondering what the payoff might be, while those are more familiar are probably remembering posts like this one expressly suggesting that doing this is a bad idea.
Firstly, there are two advantages Kudu can provide as a queue compared to Kafka:
Advantage 1: Availability

A quorum of Kudus (source http://bit.ly/1nghnwf )
Update 2016-01-26: As of Kafka 0.8.2+ there’s a new configuration option min.insync.replicas that in conjunction with request.required.acks can provide similar guarantees to Raft consensus. More details available here. Apologies for the confusion, and thanks to Jay Kreps for the clarification.
Kafka has replication between brokers, but by default it’s asynchronous. The system that it uses to ensure consistency is homegrown and suffers from the problems endemic to achieving consistency on top of an asynchronous replication system. If you’re familiar with the different iterations of traditional RDBMS replication systems, the challenges will sound familiar. Comparatively, Kudu’s replication is based on the Raft consensus algorithm, which guarantees that as long as you have enough nodes to form a quorum, you’ll be able to satisfy reads and writes within a bounded amount of time and a guarantee of a consistent view of the data.
Advantage 2: Flexibility

An inflexible Kudu (source http://bit.ly/1WIxNtL )
There are many use cases that initially seem like a good fit for Kafka, but that need flexibility that Kafka doesn’t provide. A datastore like Kudu gives more options.
For instance, some applications require processing of infrequent events that require queue modification, which Kafka doesn’t provide:
-
A Twitter firehose-style app needs to be able to process Tweet deletions/edits.
-
A system for storing RDBMS replication logs needs to be able to handle replica promotions, which sometimes requires rewriting history due to lost events.
Many other applications require many independent queues (e.g. one per domain or even one per user).
In practice, Kafka suffers significant bottlenecks as the number of queues increase: leader reassignment latency increases dramatically, memory requirements increase significantly, and many of the metadata APIs become noticeably slower. As the queues become smaller and more numerous, the workload begins to resemble that of a generic random-access datastore.
If Kudu can be made to work well for the queue workload, it can bridge these use cases. And indeed,Instagram, Box, and others have used HBase or Cassandra for this workload, despite having serious performance penalties compared to Kafka (e.g. Box reports a peak of only ~1.5K writes/second/node in their presentation and Instagram has given multiple talks about the Cassandra-tuning heroics required).
Reasons disadvantages don’t render this insane
Happily, Kudu doesn’t have many of the disadvantages of other datastores when it comes to queue-based workloads:
-
Unlike Cassandra, Kudu doesn’t require a lengthy tombstone period holding onto deleted queue entries.
-
Unlike Bigtable and HBase, Kudu doesn’t have to optimize for large files suitable for storing in GFS-derived filesystem. Its compaction strategy (read section 4.10 of of the Kudu paper for the gory details) makes the compaction overhead for the queue use-case constant rather than scaling with the overall volume of data in the queue.
The mechanics of making Kudu act like a Kafka-style message queue
At a high level, we can think of Kafka as a system that has two endpoints:
enqueueMessages(String queue, List<String> message)(List<String> messages, int nextPosition) <- retrieveNextMessages(String queue, long position)
for which enqueueMessage is high throughput and retrieveNextMessage is high throughput as long as its called with sequential positions.
Behind the scenes, enqueueMessages needs to assign each message passed in a position and store it in a format where retrieveNextMessages can iterate over the messages in a given queue efficiently.
This API suggests that we want our Kudu primary key to be something like (queue STRING, position INT). But how do we find the next position for enqueueMessage? If we require the producers submitting the messages to find their own position, it would both be an annoying API to use and likely a performance bottleneck. Luckily, the outcome of the Raft consensus algorithm is a fully ordered log, which gives each message a unique position in its queue.
Specifically, in Kudu’s implementation of Raft, the position is encoded as an OpId, which is a tuple of(term, index), where term is incremented each time a new consensus leader is elected and index is incremented each time. There’s an additional wrinkle in that each Raft entry can hold multiple row inserts, so we need to add a third int called offset to add an arbitrary but consistent ordering within each Raft entry. This means that (term, index, offset) monotonically increases with each element and we can use it as our position.
There’s an implementation challenge here: the position isn’t computed until after we’ve done the Raft round, but we need to give each message a primary key before we submit the entry to Raft. Fortunately, since the Raft log produced is the same on each replica, we can get around this by submitting the entry with a placeholder value and then substituting in the position whenever we read the entry from the consensus log. The full change is here.
Results
I first tested the change by instrumenting Kudu and the client and ensuring that the position generated was correctly generated.
Then I wanted to check to see if the expected theoretical performance was in practice.
I tested the change on a cluster of 5x Google Compute Engine n1-standard-4 instances. Each had a 1 TB standard persistent HDD shared between both the logs and the tablets. I built Kudu from this revision. I ran the master on one machine, the client on another, and tablet servers on the remaining three nodes.
It’s important to note that this is not a particularly optimized setup nor is it a particularly close comparison topublicly available Kafka benchmarks. However, it should give us a ballpark estimate of whether this is workable.
I used a 100 byte string value with this schema:
KuduSchema schema;
KuduSchemaBuilder b;
b.AddColumn("queue")->Type(KuduColumnSchema::INT32)->NotNull();
b.AddColumn("op_id_term")->Type(KuduColumnSchema::INT64)->NotNull();
b.AddColumn("op_id_index")->Type(KuduColumnSchema::INT64)->NotNull();
b.AddColumn("op_id_offset")->Type(KuduColumnSchema::INT32)->NotNull();
b.AddColumn("val")->Type(KuduColumnSchema::STRING)->NotNull();
vector<string> keys;
keys.push_back("queue");
keys.push_back("op_id_term");
keys.push_back("op_id_index");
keys.push_back("op_id_offset");
b.SetPrimaryKey(keys);The whole client harness is available here.
The results are encouraging. Inserting 16M rows in 1024 row batches sharded across 6 queues took 104 seconds for a total of 161k rows/second.
Given that this is unoptimized and with 1/6th the hard drive bandwidth of the Kafka benchmark, it’s definitely in the same realm as Kafka’s 2 million row/second result.
Reasons you might not want to do this in production just yet/Further work
First off, the change above isn’t committed to Apache Kudu. It breaks the abstraction between the consensus layer and the random-access storage layer. That’s a tradeoff that’s probably only worth making if this is something that people actively want. If you have a matching use case and you’d be interested in trying out Kudu for it, I’d love to hear from you: email me.
Secondly, Apache Kudu is in beta. There are two relevant blockers:
-
Kudu doesn’t have multi-master support yet, so there is a single point of failure in the system. Currently, the team’s best guess is that this support is coming late summer, but as in all software development, that’s subject to change.
-
Kudu doesn’t yet fully garbage collect tombstone row entries. Unlike Cassandra, there’s no architectural necessity for this, but there’s some implementation work to be done.
Beyond that, there’s some support work that needs to be done before this is something I’d be looking to deploy in production:
-
Currently the bottleneck appears to be network bandwidth between two nodes in the cluster:
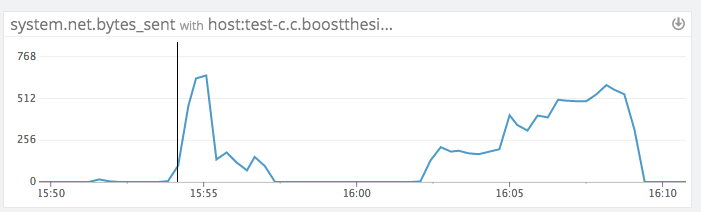 is a representation of network utilization in MB/s during the test vs. an iperf maximum bandiwdth result between the two nodes of 800MB/s with no other resources maxed out. This is likely to be an optimization opportunity for the replication protocol.
is a representation of network utilization in MB/s during the test vs. an iperf maximum bandiwdth result between the two nodes of 800MB/s with no other resources maxed out. This is likely to be an optimization opportunity for the replication protocol. -
More generally, the performance testing so far suggests that Kudu is in the same neighborhood as Kafka, but much more rigorous testing would be needed to show the full picture. Since reads and writes are competing for many of the same resources, a full performance test would need to compare read/write workloads. Also, for the smaller queue use case, the test would need to parameterize on Kudu partition sizes as well as number of queues.
-
It would probably make sense to add a long polling scan call to Kudu to decrease latency while tailing a queue.
