

Download
Before starting make sure you have this two softwares
Extract downloaded tar file
Configuration
Step 1 – Windows path configuration
set HADOOP_HOME path in enviornment variable for windows
Right click on my computer > properties > advanced system settings > advance tab > environment variables > click on new
Set hadoop bin directory path
Find path variable in system variable > click on edit > at the end insert ‘; (semicolon)’ and paste path upto hadoop bin directory in my case it’s a
F:/Hortanwork/1gbhadoopram/Software/hadoop-2.7/hadoop-2.7.1/bin

Step 2 – Hadoop configuration
Edit hadoop-2.7.1/etc/hadoop/core-site.xml, paste the following lines and save it.
<configuration> <property> <name>fs.defaultFS</name> <value>hdfs://localhost:9000</value> </property> </configuration>
Edit hadoop-2.7.1/etc/hadoop/mapred-site.xml, paste the following lines and save it.
<configuration> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property> </configuration>
Edit hadoop-2.7.1/etc/hadoop/hdfs-site.xml, paste the following lines and save it, please create data folder somewhere and in my case i have created it in myHADOOP_HOME directory
<configuration> <property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/f:/Hortanwork/1gbhadoopram/Software/hadoop-2.7/hadoop-2.7.1/data/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>/f:/Hortanwork/1gbhadoopram/Software/hadoop-2.7/hadoop-2.7.1/data/datanode</value> </property> </configuration>
OR

Edit hadoop-2.7.1/etc/hadoop/yarn-site.xml, paste the following lines and save it.
<configuration> <property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce.shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property> </configuration>
Edit hadoop-2.7.1/etc/hadoop/hadoop-env.cmd, comment existing%JAVA_HOME% using @rem at start, give proper path and save it. (my jdk is in program files to avoid spaces i gave PROGRA~1)
Demo
Step 3 – Start everything
Very Important step!!!!
3.1) Before starting everything you need to add some [dot].dll and [dot].exe files of windows please download bin folder from my github repository –sardetushar_gitrepo_download
or download from https://github.com/steveloughran/winutils/tree/master/hadoop-2.7.1/bin
3.2) copy all the files dowloaded into the %HADOOP_HOME%\bin folder (The download file contains .dll and .exe file (winutils.exe for hadoop 2.7.1) which adapte for windows os).
3.3) Open cmd and type ‘hdfs namenode -format’ – after execution you will see below logs

3.4) Open cmd and point to sbin directory and type ‘start-all.cmd’
C:\UserDefined\BigData\hadoop-2.7.1\sbin>start-all.cmd
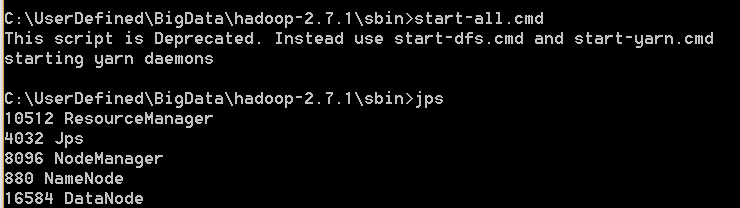
It will start following process
Namenode
Datanode
YARN resourcemanager
YARN nodemanager

JPS – to see services are running
open cmd and type – jps (for jps make sure your java path is set properly)

GUI
Step 4 – namenode GUI, resourcemanager GUI
Resourcemanager GUI address – http://localhost:8088
Namenode GUI address – http://localhost:50070
In next tutorial we will see how to run mapreduce programs in windows using eclipse and this hadoop setup

 浙公网安备 33010602011771号
浙公网安备 33010602011771号