


1. 环境准备
JDK1.8
Scala2.11.8
Maven 3.3+
IDEA with scala plugin
2. 下载spark源码
下载地址 https://archive.apache.org/dist/spark/spark-2.0.0/spark-2.0.0.tgz
将下载好的spark源码解压到c:\workspace
3. Idea 导入spark-2.0.0源码工程


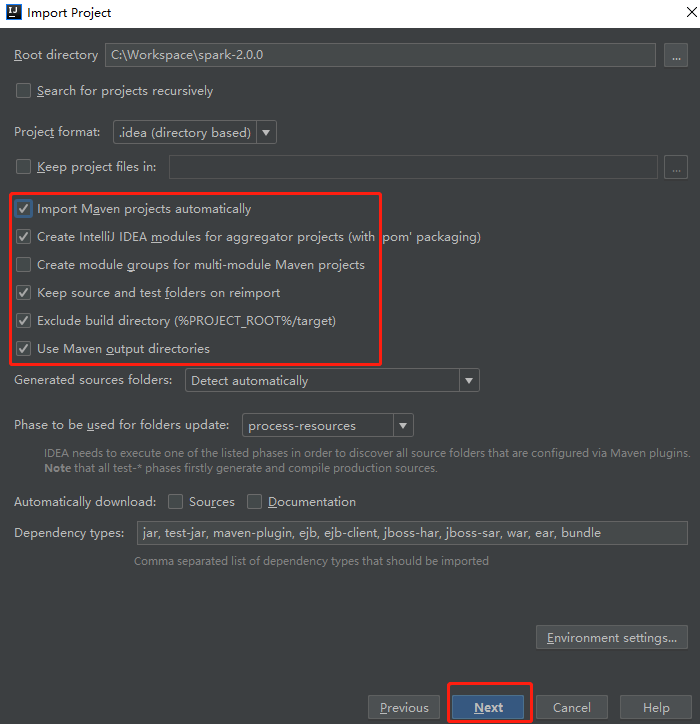
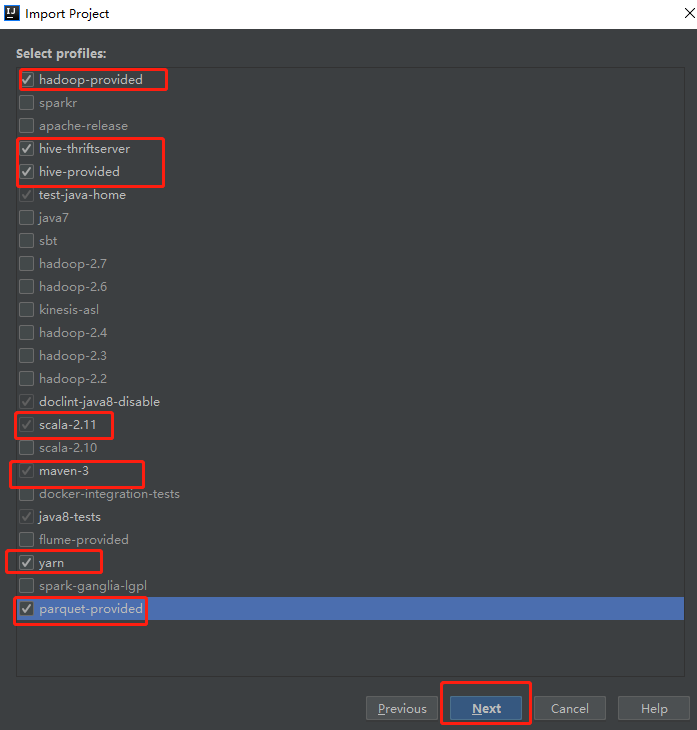
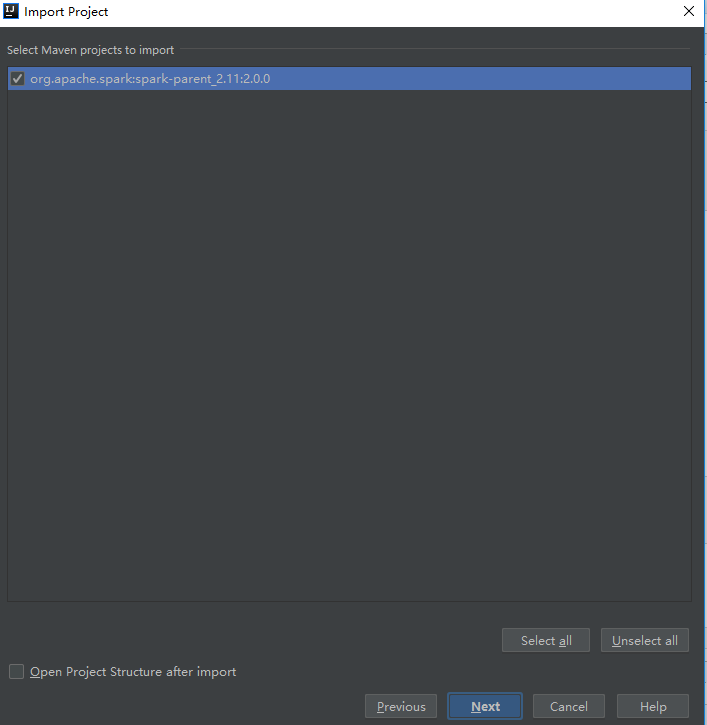

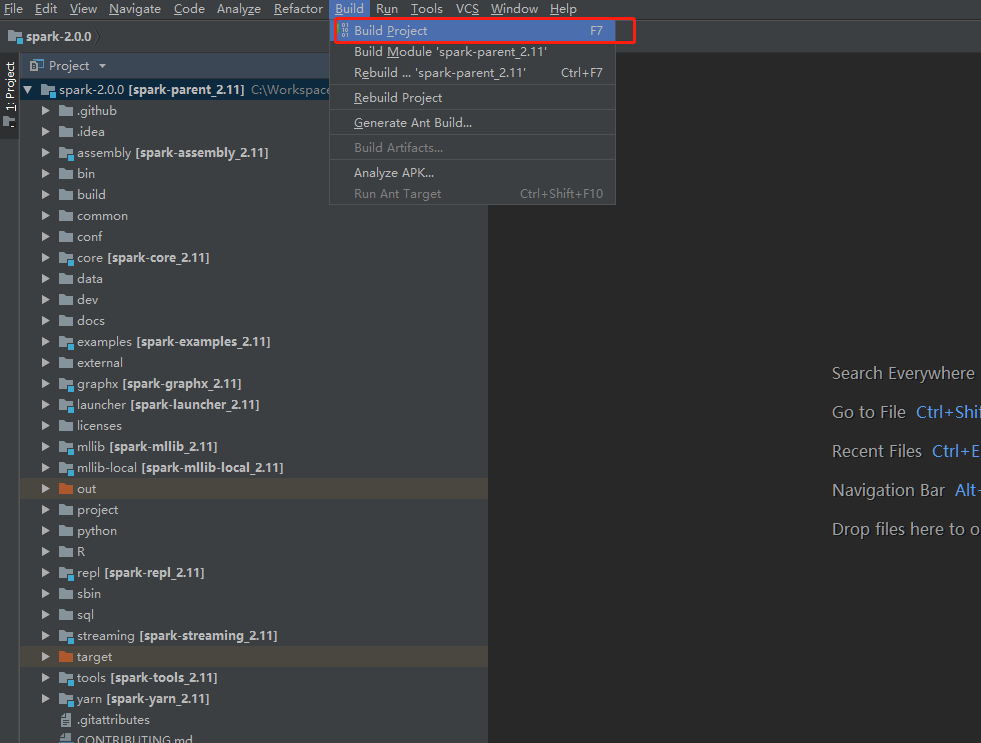
一路next下去,最后点击finish。
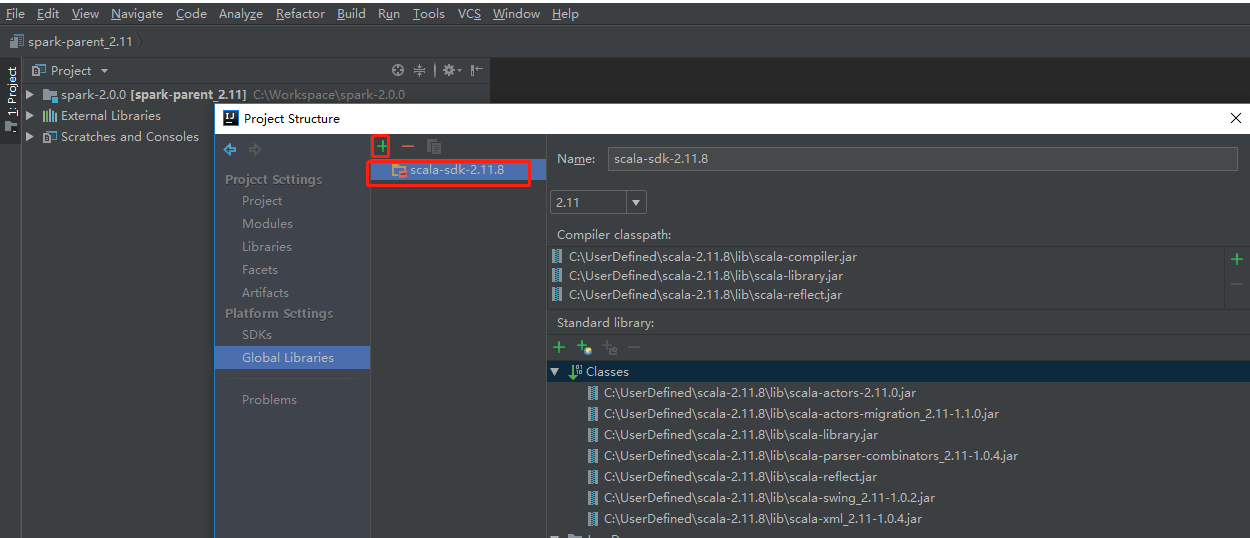
最后,进行项目的编译
4. 可能遇到的问题
4.1 not found: type SparkFlumeProtocol
spark\external\flume-sink\src\main\scala\org\apache\spark\streaming\flume\sink\SparkAvroCallbackHandler.scala Error:(45, 66) not found: type SparkFlumeProtocol
解决方案:
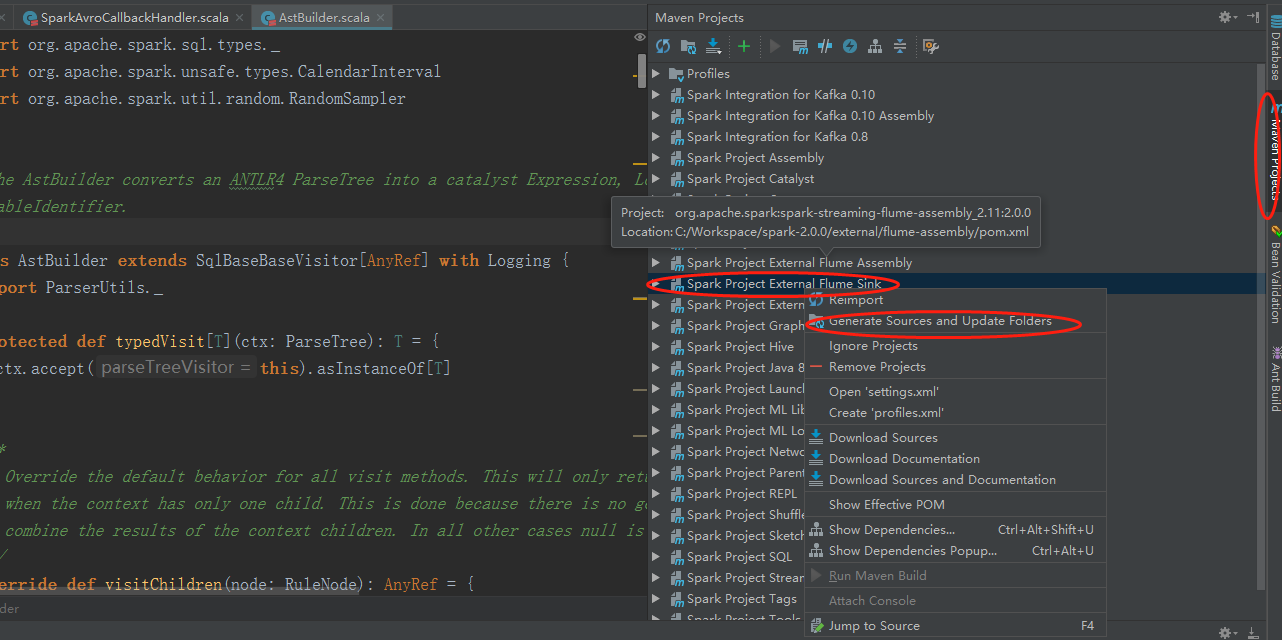
选中Spark Project External Flume Sink,并右键点击Generate Sources and Update Folders. 然后重新编译应该就会消失。
4.2 Error:(34, 45) object SqlBaseParser is not a member of package org.apache.spark.sql.catalyst.parser
\spark\sql\catalyst\src\main\scala\org\apache\spark\sql\catalyst\parser\AstBuilder.scala Error:(34, 45) object SqlBaseParser is not a member of package org.apache.spark.sql.catalyst.parser import org.apache.spark.sql.catalyst.parser.SqlBaseParser._
解决方案:
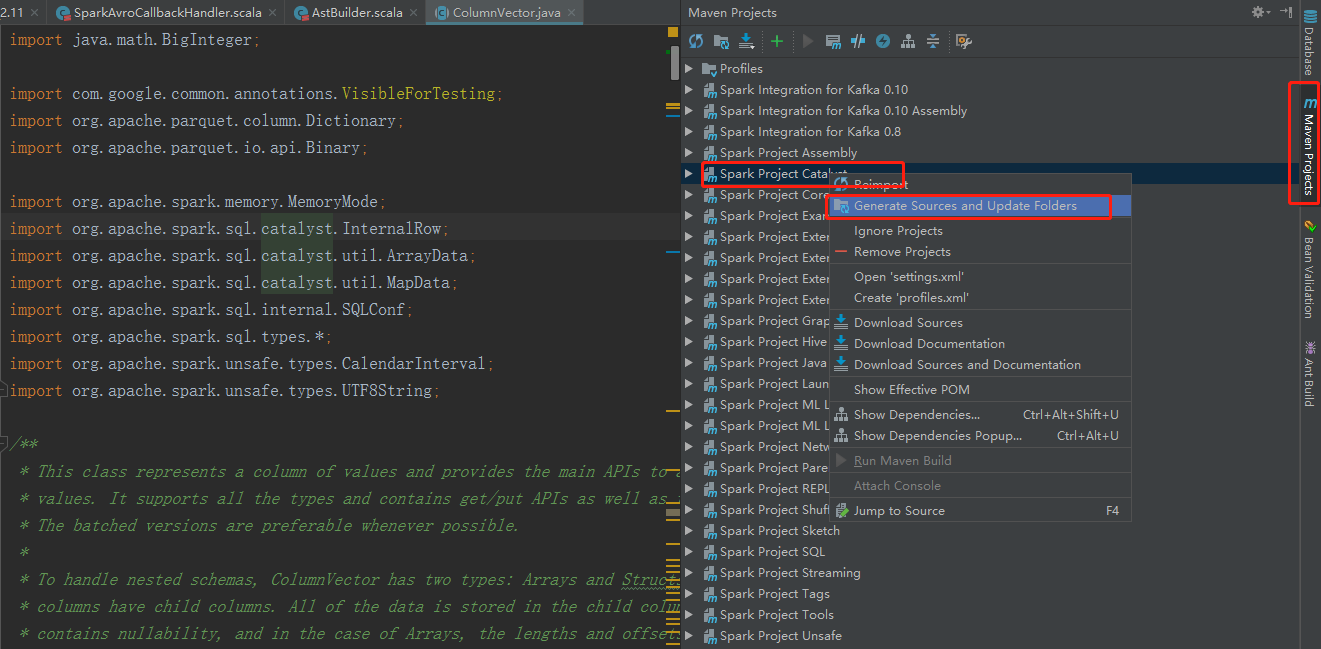
选中Spark Project External Catalyst,并右键点击Generate Sources and Update Folders. 然后重新编译应该就会消失.
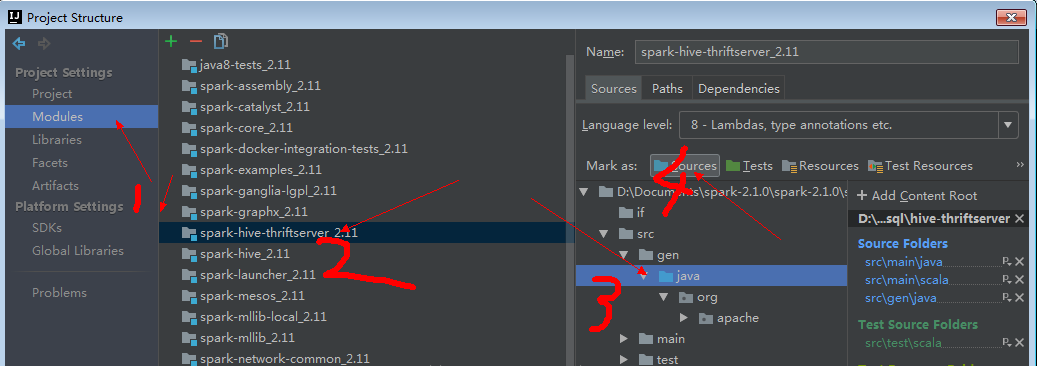
4.3 Error:(52, 75) not found: value TCLIService
spark\sql\hive-thriftserver\src\main\java\org\apache\hive\service\cli\thrift\ThriftCLIService.java Error:(52, 75) not found: value TCLIService public abstract class ThriftCLIService extends AbstractService implements TCLIService.Iface, Runnable {………..
一般来讲,这几个问题解决之后,编译就会成功。

5. gitBash中进行编译
为什么使用gitbash,因为在idea中编译时会出现各种各种的报错,gitbash中拥有一些idea中没有的环境。可能出现如下错误,使用gitbash即可解决
使用gitbash进入项目的根目录下,执行下面3条命令
cd /c/Workspace/spark-2.0.0
export MAVEN_OPTS="-Xmx2g -XX:MaxPermSize=512M -XX:ReservedCodeCacheSize=512m" ./build/mvn -Pyarn -Phadoop-2.7 -Dhadoop.version=2.7.3 -DskipTests clean package

最后编译出来的结果如下:

参考:
https://blog.csdn.net/make__It/article/details/84258916
http://dengfengli.com/blog/how-to-run-and-debug-spark-source-code-locally/

