



Hive默认使用MapReduce作为执行引擎,即Hive on mr,Hive还可以使用Tez和Spark作为其执行引擎,分别为Hive on Tez和Hive on Spark。由于MapReduce中间计算均需要写入磁盘,而Spark是放在内存中,所以总体来讲Spark比MapReduce快很多。默认情况下,Hive on Spark 在YARN模式下支持Spark。
因为本人在之前搭建的集群中,部署的环境为:
hadoop2.7.3
hive2.3.4
scala2.12.8
kafka2.12-2.10
jdk1.8_172
hbase1.3.3
sqoop1.4.7
zookeeper3.4.12
#java export JAVA_HOME=/usr/java/jdk1.8.0_172-amd64 export JRE_HOME=$JAVA_HOME/jre export PATH=$JAVA_HOME/bin:$JRE_HOME/bin:$PATH export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar #hbase export HBASE_HOME=/home/workspace/hbase-1.2.9 export PATH=$HBASE_HOME/bin:$PATH #hadoop export HADOOP_HOME=/home/workspace/hadoop-2.7.3 export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib/native" export PATH=$PATH:$HADOOP_HOME/bin:$HADOOP_HOME/sbin ###enable hadoop native library export LD_LIBRARY_PATH=$HADOOP_HOME/lib/native #hive export HIVE_HOME=/home/workspace/software/apache-hive-2.3.4 export HIVE_CONF_DIR=$HIVE_HOME/conf export PATH=.:$HIVE_HOME/bin:$PATH export HADOOP_CLASSPATH=$HADOOP_CLASSPATH:$HIVE_HOME/lib/* export HCAT_HOME=$HIVE_HOME/hcatalog export PATH=$HCAT_HOME/bin:$PATH #Sqoop export SQOOP_HOME=/home/workspace/software/sqoop-1.4.7.bin__hadoop-2.6.0 export PATH=$PATH:$SQOOP_HOME/bin # zookeeper export ZK_HOME=/home/workspace/software/zookeeper-3.4.12 export PATH=$ZK_HOME/bin:$PATH #maven export MAVEN_HOME=/home/workspace/software/apache-maven-3.6.0 export M2_HOME=$MAVEN_HOME export PATH=$PATH:$MAVEN_HOME/bin #scala export SCALA_HOME=/home/workspace/software/scala-2.11.12 export PATH=$SCALA_HOME/bin:$PATH #kafka export KAFKA_HOME=/home/workspace/software/kafka_2.11-2.1.0 export PATH=$KAFKA_HOME/bin:$PATH #kylin export KYLIN_HOME=/home/workspace/software/apache-kylin-2.6.0 export KYLIN_CONF_HOME=$KYLIN_HOME/conf export PATH=:$PATH:$KYLIN_HOME/bin:$CATALINE_HOME/bin export tomcat_root=$KYLIN_HOME/tomcat #变量名小写 export hive_dependency=$HIVE_HOME/conf:$HIVE_HOME/lib/*:$HCAT_HOME/share/hcatalog/hive-hcatalog-core-2.3.4.jar #变量名小写 #spark export SPARK_HOME=/home/workspace/software/spark-2.0.0 export PATH=:$PATH:$SPARK_HOME/bin
现在想部署spark上去,鉴于hive2.3.4支持的spark版本为2.0.0,所以决定部署spark2.0.0,但是spark2.0.0,默认是基于scala2.11.8编译的,所以,决定基于scala2.12.8手动编译一下spark源码,然后进行部署。本文默认认为前面那些组件都已经安装好了,本篇只讲如何编译spark源码,如果其他的组件部署不清楚,请参见本人的相关博文。
1. 下载spark2.0.0源码
cd /home/workspace/software wget http://archive.apache.org/dist/spark/spark-2.0.0/spark-2.0.0.tgz tar -xzf spark-2.0.0.tgz cd spark-2.0.0
2. 修改pom.xml改为用scala2.12.8编译
vim pom.xml
修改scala依赖版本为2.12.8(原来为2.11.8)
<scala.version>2.12.8</scala.version> <scala.binary.version>2.12</scala.binary.version>
3. 修改make-distribution.sh
cd /home/workspace/software/spark-2.0.0/dev vim make-distribution.sh
修改其中的VERSION,SCALA_VERSION,SPARK_HADOOP_VERSION,SPARK_HIVE为对应的版本值
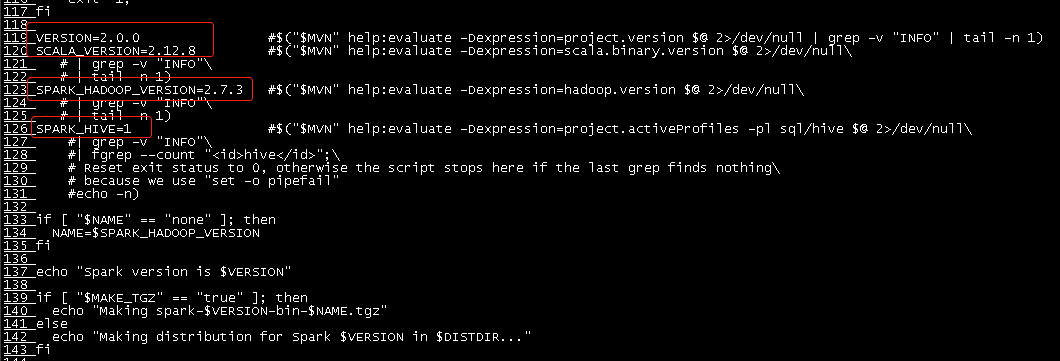
其中SPARK_HIVE=1表示打包hive,非1值为不打包hive。
此步非必须,若不给定,它也会从maven源中下载,为节省编译时间,直接给定;
4. 下载zinc0.3.9
Zinc is a long-running server version of SBT’s incremental compiler. When run locally as a background process, it speeds up builds of Scala-based projects like Spark. Developers who regularly recompile Spark with Maven will be the most interested in Zinc. The project site gives instructions for building and running zinc; OS X users can install it using brew install zinc.
If using the build/mvn package zinc will automatically be downloaded and leveraged for all builds. This process will auto-start after the first time build/mvn is called and bind to port 3030 unless the ZINC_PORT environment variable is set. The zinc process can subsequently be shut down at any time by running build/zinc-<version>/bin/zinc -shutdown and will automatically restart whenever build/mvn is called.
wget https://downloads.typesafe.com/zinc/0.3.9/zinc-0.3.9.tgz #下载zinc-0.3.9.tgz,scala编译库,如果不事先下载,编译时会自动下载
将zinc-0.3.9.tgz解压到/home/workspace/software/spark-2.0.0/build目录下
tar -xzvf zinc-0.3.9.tgz -C /home/workspace/software/spark-2.0.0/build
5. 下载scala2.12.8 binary file
wget https://downloads.lightbend.com/scala/2.12.8/scala-2.12.8.tgz #下载scala-2.12.8.tgz,scala编译库,如果不事先下载,编译时会自动下载 tar -xzvf scala-2.12.8.tgz -C /home/workspace/software/spark-2.0.0/build
6. 编译spark
cd /home/workspace/software/spark-2.0.0/dev ./make-distribution.sh --name "hadoop2.7.3-with-hive" --tgz -Dhadoop.version=2.7.3 -Dscala-2.12 -Phadoop-2.7 -Pyarn -Phive -Phive-thriftserver -Pparquet-provided -DskipTests clean package #或者 #./make-distribution.sh --name "hadoop2.7-with-hive" --tgz "-Pyarn,-Phive,-Phive-thriftserver,hadoop-provided,hadoop-2.7,parquet-provided,-Dscala-2.12,-Dhadoop.version=2.7.3,-DskipTests" clean package ####参数解释: # -DskipTests,不执行测试用例,但编译测试用例类生成相应的class文件至target/test-classes下。 # -Dhadoop.version 和-Phadoop: Hadoop 版本号,不加此参数时hadoop 版本为1.0.4 。 # -Pyarn :是否支持Hadoop YARN ,不加参数时为不支持yarn 。 # -Phive和-Phive-thriftserver:是否在Spark SQL 中支持hive ,hive jdbc支持,不加此参数时为不支持hive 。 # –with-tachyon :是否支持内存文件系统Tachyon ,不加此参数时不支持tachyon 。 # –tgz :在根目录下生成 spark-$VERSION-bin.tgz ,不加此参数时不生成tgz 文件,只生成/dist 目录。 # –name :和–tgz结合可以生成spark-$VERSION-bin-$NAME.tgz的部署包,不加此参数时NAME为hadoop的版本号。 # -Phadoop-provided: 不包含hadoop生态的其他库文件,在yarn模式部署时,不包含此参数,可能会造成有些文件有多个不同的版本,加入此参数后,一些hadoop生态的工程将不会被包含进来,如ZooKeeper,Hadoop.
或者使用maven编译
cd /home/workspace/software/spark-2.0.0
export MAVEN_OPTS="-Xmx6g -XX:MaxPermSize=2g -XX:ReservedCodeCacheSize=2g" #jdk 1.8不需要设置这个参数,但是1.8以下版本jdk需要设置这个参数 ../build/mvn -Dscala-2.12.8 -Phadoop-provided -Pparquet-provided -Phadoop-2.7 -Dhadoop.version=2.7.3 -Pyarn -Phive -Phive-thriftserver -DskipTests clean package #也可以使用maven编译
下面截图时使用/make-distribution.sh编译的截图

编译时间大概在半小时以上。
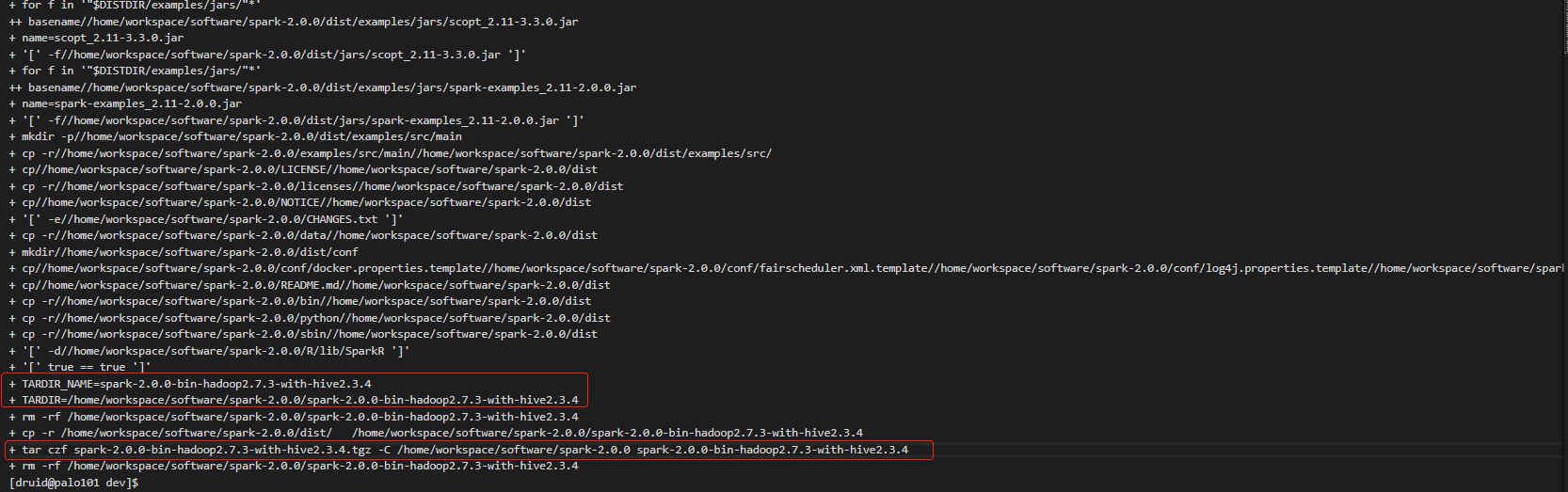
编译出来的二进制包在/home/workspace/software/spark-2.0.0根目录下
注:如果编译过程中出现类似
[ERROR] Failed to execute goal net.alchim31.maven:scala-maven-plugin:3.2.2:testCompile (scala-test-compile-first) on project spark-core_2.11: Execution scala-test-compile-first of goal net.alchim31.maven:scala-maven-plugin:3.2.2:testCompile failed. CompileFailed -> [Help 1] [ERROR] [ERROR] To see the full stack trace of the errors, re-run Maven with the -e switch. [ERROR] Re-run Maven using the -X switch to enable full debug logging. [ERROR] [ERROR] For more information about the errors and possible solutions, please read the following articles: [ERROR] [Help 1] http://cwiki.apache.org/confluence/display/MAVEN/PluginExecutionException [ERROR] [ERROR] After correcting the problems, you can resume the build with the command [ERROR] mvn <goals> -rf :spark-core_2.11
这样的错误,先执行一下:
./change-scala-version.sh 2.11
ps -ef | grep zinc
kill -9 {zinc process id}
然后重新编译即可。
编译完成!

