word2vec原理
一、统计语言模型
统计语言模型就是指计算一个句子出现概率的模型。假设一句话由T个词按顺序构成,则这T个词的联合概率就是这个句子的概率:
p(W)=p(wT1)=p(w1,w2,…,wT)
利用贝叶斯公式,上式可写为:
p(W)=p(wT1)=p(w1)p(w2|w1)p(w3|w21)⋯p(wT|wT−11)=T∏t=1p(wt|wt−11)
其中的条件概率便是模型的参数,参数个数为T个。当语料库(Corpus)C足够大的时候,条件概率p(wt|wt−11)=p(wt1)p(wt−11)可表示为:
p(wt|wt−11)=p(wt1)p(wt−11)≈count(wt1)count(wt−11)
假设词汇表为V,其中词汇的个数是|V|,那么对于一个长度为T的句子,有|V|T种组合方式,对于每一种组合方式,都要计算T个参数,总共就需要计算T|V|T个参数,计算量非常之大,所以该模型并不容易实现。
二、n-gram模型
n-gram模型对条件概率p(wt|wt−11)做了一个Martov假设,认为一个词出现的概率只和它前面的n-1个词相关,可表示为:
p(wt|wt−11)≈p(wt|wt−1t−n+1)
当n=2时:
p(wt|wt−11)≈p(wt|wt−1)≈count(wt−1,wt)count(wt−1)
这时单个参数p(wt|wt−11)的统计就变得简单了。
在模型效果方面,n=2再到n=3,模型效果上升显著,从n=3到n=4时,模型效果提升不明显。
三、神经概率语言模型
从上面的模型可以看到,问题的核心在于找到一个方法去计算p(wt|wt−11),神经概率语言模型的方法是通过一个神经网络去学习这个概率,具体为:
1、将词汇表V中的任意一个词i通过映射关系C将其映射为一个m维实数向量C(i)∈Rm,其中C由|V|×m维矩阵来表示
2、对于词汇表中的第i个词i=wt,给定其上下文环境对应的特征向量:
Context=(C(wt−1),C(wt−2),…,C(wt−n+1))
则在Context出现的情况下,wt出现的条件概率可用概率函数来表示:
f(i,wt−1,…,wt−n+1)=g(i,C(wt−1),C(wt−2),…,C(wt−n+1))
其中映射关系C的参数就是词的特征向量本身,由|V|×m维矩阵来表示,其中第i行的就是词汇表V中第i个的特征向量C(i),函数g可认为是一个前馈或递归神经网络.
对于任意的上下文词组,在该词组出现的条件下,有如下约束:
|V|∑i=1f(i,wt−1,…,wt−n+1)=1
即在该上下文词组出现的情况下,下一个词必然出现在词汇表中,所以其加和为1,不同的词出现的概率不一样。
该模型的结构如下图所示:
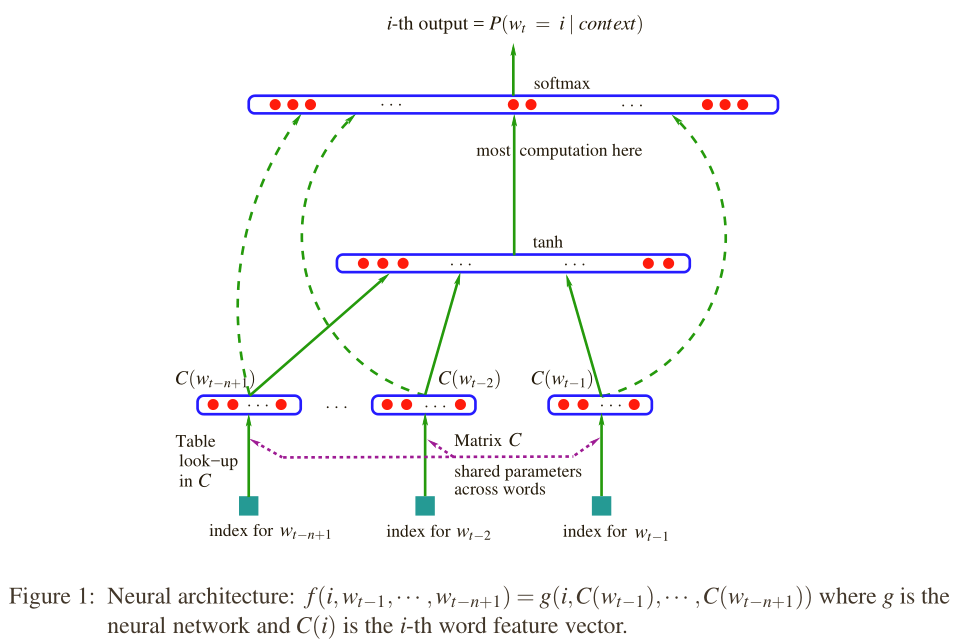
最下面表示的是上下文词组在词汇表中的索引,输入x即为上下文词组的特征向量,即将n-1个词的向量首尾连接起来,维度为(n−1)×m:
x=Context=(C(wt−1),C(wt−2),…,C(wt−n+1))
这个是输入层,中间层是一个隐藏层,具体为双曲正切函数tanh,隐藏层的输出为:
y=b+Utanh(d+Hx)
其中,H是一个h×(n−1)m的一个矩阵,其中h为隐藏层的神经元个数,d为隐藏层的偏移(共有h个元素),U是隐藏层输出的权重矩阵(|V|×h),b是隐藏层输出的偏移。
可以得到模型中的参数为:
θ=(b,d,U,H,C)
参数的个数为:
|V|(1+nm+h)+h(1+(n−1)m)
在输出层用softmax函数将概率归一化,具体为:
p(wt|wt−1,…,wt−n+1)=eywt∑i∈Veyi
其物理意义表示在给定上下文词组的条件下,输出wt为词汇表V中的第i个词(索引)的概率。
目标是最大化对数似然函数:
L=1T∑tlogf(wt,wt−1,…,wt−n+1;θ)
为了求得最优的参数θ,即可使用随机梯度上升法:
θ←θ+∂logp(wt|wt−1,…,wt−n+1)∂θ
四、word2vec
word2vec是在上面的模型基础上发展而来的,包括两个模型,CBOW模型(Continuous Bag-of-Words Model)和Skip-gram模型(Continuous Skip-gram Model)。可分别基于Hierarchical Softmax和Negative Sampling来设计,下面只介绍Hierarchical Softmax的CBOW和Skip-gram模型。
1、CBOW
与神经概率语言模型类似,CBOW模型同样包括三层神经网络结构,输入层,投影层,和输出层。
其中每一个样本形式为(Context(w),w),其中Context(w)为w的上下文环境,由词w前后各c各词组成。
输入层:Context(w)中2c个词的词向量
投影层:将2c个词向量做加和
xwt=2c∑i=1C(wi)∈Rm
输出层:一棵Huffman树,叶子节点共|V|个,|V|表示词汇表V的大小
该模型与神经概率语言模型有如下不同:
1、神经概率语言模型的输入层是上下文词组拼接而成,而CBOW是累加得到
2、神经概率语言模型有隐藏层tanh,而CBOW没有
3、神经概率语言模型输出的是线性结构,而CBOW的输出是树形结构Huffman树
未完待续
去吧,去吧,到彼岸去吧,彼岸是光明的世界!

【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】凌霞软件回馈社区,博客园 & 1Panel & Halo 联合会员上线
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】博客园社区专享云产品让利特惠,阿里云新客6.5折上折
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步