支持向量机-可分的类
本次我们将提出另一种设计线性分类器的原理。我们将从二类线性可分的任务开始,然后将这种方法扩展到数据不可分的更一般的情形。
让 $x_i,i=1,2,\ldots,N$,表示训练集X的特征向量,这些向量属于两类中的任意一类,并且假设这些向量是线性可分的,目标还是设计一个超平面:
$$g(x)=w^Tx+w_0=0$$
使该超平面可以将所有的训练数据正确分类。由于这样的一个超平面并不是唯一的。根据已有的经验,感知机算法会收敛到任意一个可能的解,这次我们希望更加严苛。下图阐明了分类任务的两个可能的超平面的解。两个超平面都完成了对训练集分类的任务。然而,在实践中,训练集以外的数据将会被送到分类器中,一个敏锐的工程师将选择这两个超平面中的哪一个作为分类器呢?毫无疑问答案是实线表示的分类器,原因是这个超平面为两边都留了更多的空间,使得两类中的数据都可以更加自由的移动,而产生错误的风险更小。当它面对处理未知数据的挑战时,这样的一个超平面更加被信服。此时我们遇到了在分类器设计阶段一个非常重要的问题,它被称为“分类器的通用性能”,这涉及到分类器的性能问题,分类器使用训练数据集设计,用来正确地处理训练集以外的数据。
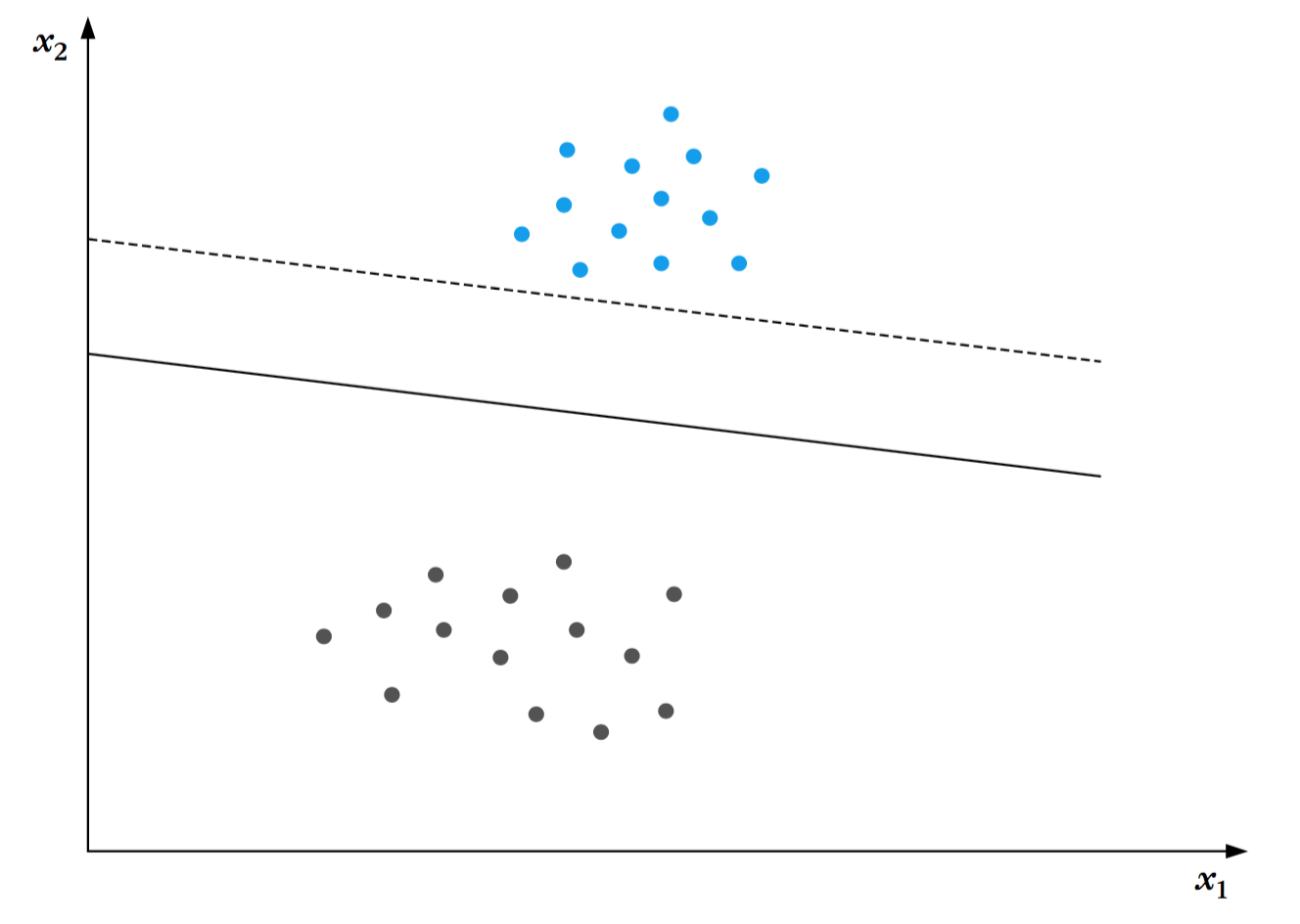
通过上面简要的讨论,我们即将接受,对超平面分类器的一个很明智的选择是选取的超平面可以给两边的类都留出最大间隔。后面我们将看到这个明智的选择有着更深的原理,是源自于Vapnik和Chervonenkis所提供给我们的优雅的数学公式。
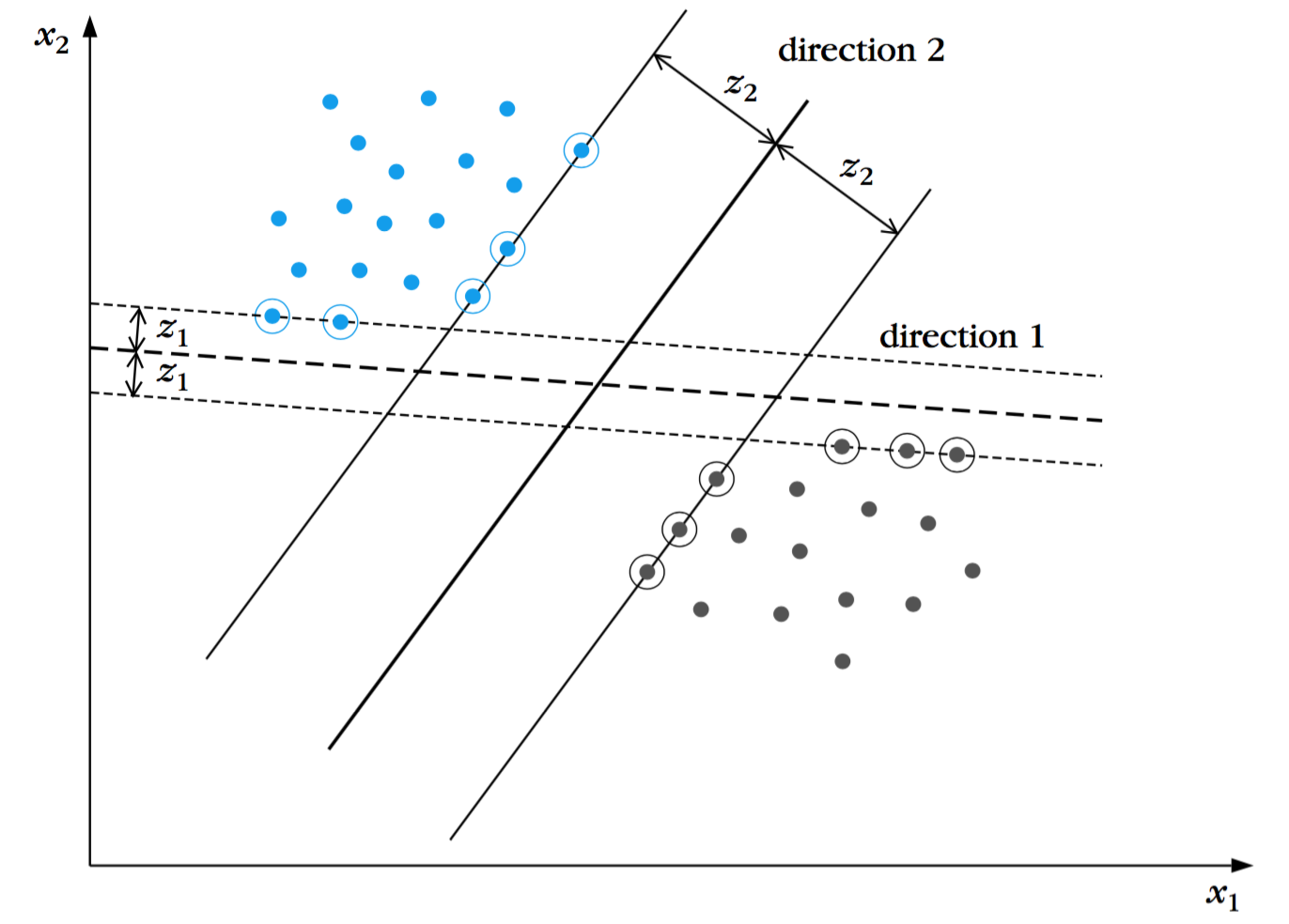
现在让我们将超平面给两边留出的间隔定量化。每个超平面都是由其方向和空间中的位置所描述。由于我们并不偏袒两类中的任何一类,所以对每一个方向来讲,选择这样的一个超平面是合理的:这个超平面到$\omega_1$与$\omega_2$两个类中相应的最近点的距离是相同的。这一点在下图中阐明。用黑线表示的超平面是从各个方向的无限个超平面集合中选择出来的。方向1的间隔是$2z_1$,方向2的间隔是$2z_2$。我们的目标是寻找能够给出最大可能间隔的方向。然而,每一个超平面都由一个缩放因子决定,我们希望从中解放出来,通过对所有的候选超平面采用合适的缩放比例。
点到超平面的距离由下式给定:
$$z=\frac{\vert g(x) \vert}{\Vert w \Vert}$$
我们现在可以缩放$w,w_0$使得$\omega_1,\omega_2$两个类中到超平面最近的点代入$g(x)$之后的值分别为1和-1.这等价于:
1、间隔为$\frac{1}{\Vert w \Vert} + \frac{1}{\Vert w \Vert} = \frac{2}{\Vert w \Vert}$
2、需要满足:
$$\begin{align*}w^Tx+w_0 &\ge 1,&\forall x \in \omega_1 \\ w^Tx+w_0 &\le -1,&\forall x \in \omega_2 \end{align*}$$
下面就交给数学来处理了。对于每个$x_i$,我们用$y_i$表示相应的类。我们的任务现在可以被总结为:计算超平面的参数$w,w_0$使得:
$$\begin{align*}&minimize&&J(w,w_0)=\frac{1}{2}\Vert w \Vert^2 \\ &subject \quad to&&y_i(w^Tx_i+w_0) \ge 1,i=1,2,\ldots,N\end{align*}$$
显然,最小化这个范数可以使间隔最大化。这个一个非线性(二次)优化任务,约束条件为一组线性不等式约束。
上面最小化的表达式所必须满足的KKT条件是:
$$\frac{\partial}{\partial w}L(w,w_0,\lambda)=0$$
$$\frac{\partial}{\partial w_0}L(w,w_0,\lambda)=0$$
$$\lambda_i \ge 0,i=1,2,\ldots,N$$
$$\lambda_i[y_i(w^Tx_i+w_0)-1]=0,i=1,2,\ldots,N$$
其中$\lambda$是拉格朗日乘子$\lambda_i$组成的向量,$L(w,w_0,\lambda)$是拉格朗日函数:
$$L(w,w_0,\lambda)=\frac{1}{2}w^Tw-\sum_{i=1}^{N}\lambda_i[y_i(w^Tx_i+w_0)-1]$$
将上面的式子结合起来可以得到:
$$w=\sum_{i=1}^{N}\lambda_iy_ix_i$$
$$\sum_{i=1}^{N}\lambda_iy_i=0$$
注释:
拉格朗日乘子可以是0或者正数。这样,最优解的向量$w$是与$\lambda_i \ne 0$对应的$N_s$个特征向量的线性组合,即:
$$w=\sum_{i=1}^{N_s}\lambda_iy_ix_i$$
这些特征向量被称为支持向量,最优超平面分类器即是一个支持向量机。一个非零的拉格朗日乘子与所谓的有效约束对应。因此在约束集合( $\lambda_i[y_i(w^Tx_i+w_0)-1]=0,i=1,2,\ldots,N$ )中表明对于$\lambda_i \ne 0$时,支持向量落在其中一个超平面上,即:
$$w^Tx+w_0=\pm1$$
换句话说,它们是与线性分类器最近的训练向量,构成了训练集中的临界元素。与$\lambda_i = 0$对应的特征向量既可以落在“类分离带”的外面,由两个超平面之间的区域所定义,也可以落在其中一个超平面上(退化情形)。假设这样的特征向量没有渡过类分离带,那么得到的超平面与这些特征向量的数值和位置无关。
尽管$w$可以显式得到,$w_0$可以通过互补松弛条件隐式得到,满足严格互补(即$\lambda \ne 0$)。在实际中,$w_0$是通过该类型所有条件所得值的平均值。
代价函数$J(w,w_0)=\frac{1}{2}\Vert w \Vert^2$是严格凸的,该性质是由相应的海塞矩阵为正定所确保的。此外,不等式约束是由线性函数组成的。这两个条件确保了局部最小值也即全局唯一最小值。这是我们最欢迎的,支持向量机的最佳超平面分类器是唯一的。
阐明了支持向量机的最佳超平面的所有这些有趣的性质之后,接下来我们就要计算涉及到的参数。从计算的观点来看,这并不是一个容易的任务,但是已经存在一些算法。我们将要使用一种方法,是由我们的最优化任务所给出的特殊的性质所表明的。它属于凸规划家族问题的一种,由于代价函数是凸的,而且约束是线性的并定义了一个可行解的凸集。这样的问题可以用拉格朗日对偶来求解。这个问题可以用Wolfe对偶表达式来等价的称述,即:
$$\begin{align*}&minimize&&L(w,w_0,\lambda) \\ &subject \quad to&&w=\sum_{i=1}^{N}\lambda_iy_ix_i, \\&&&\sum_{i=1}^{N}\lambda_iy_i=0,\\ &&&\lambda \ge 0\end{align*}$$
这两个等式约束是从拉格朗日函数关于$w,w_0$的梯度等于0得到的。我们已经有些进展。训练数据集中的特征向量通过等式约束而非不等式约束参与到问题中更容易被处理。通过一些带入计算我们最终可以将最优化问题等价地转换为:
$$\begin{align*}&\max \limits_{\lambda}&&\left(\sum_{i=1}^{N}\lambda_i-\frac{1}{2}\sum_{i,j}\lambda_i\lambda_jy_iy_jx_i^Tx_j\right) \\ &subject \quad to &&\sum_{i=1}^N\lambda_iy_i=0, \\ &&&\lambda \ge 0 \end{align*}$$
一旦最优的拉格朗日乘子被计算出来,则最优化超平面也可以获得,$w_0$可以通过互补松弛条件得到。
注释
除了引入的约束条件更加诱人之外,该公式流行还有另外一个重要的原因,训练集中的向量是以内积的形式成对参与进来的。这是最有趣的,因为代价函数并不显式地依赖于输入空间的维度!这个性质允许高效地推广到非线性可分类的情形之中。
尽管最终的最佳超平面是唯一的,但是并不确保与之关联的拉格朗日乘子$\lambda_i$是唯一的。换句话说,表达式中关于支持向量对$w$的展开式可能是不唯一的,尽管最终的结果是唯一的。
去吧,去吧,到彼岸去吧,彼岸是光明的世界!

