
MySql
之前学过ObjectOutputstream-->java对象(张三 20)->序列化到文件当中
反序列化
new java对象
readobject
writeobject
常见的有哪些数据库管理系统?
IBM——>eclipse
Oracle 甲骨文(sun)
Oracle是做数据库起家的
Oracle-->MYSQL AB公司
MYSQL是占体积最小最方便的支持标准sql的数据库管理系统
Mysql
1.sql、DB、DBMS分别是什么,他们之间的关系?
DB:
DataBase(数据库,数据库实际上在硬盘上以文件的形式存在)
DBMS:
DataBase Management System (数据库管理系统,常见的有:MySQl Oracle DB2 Sybase SqlServer....)
SQl:
结构化查询语言,是一门标准通用语言。标准的sql适合所有的数据库产品。
SQL属于高级语言,只要能看懂英语单词的,写出来的sql语句,就可以读懂什么意思。
SQl语句执行的时候,实际上内部也会先进行编译,然后再执行sql。(sql语句的编译由DBMS完成)
DBSM负责执行sql语句,通过执行sql语句来操作DB当中的数据。
关系:DBMS-(执行)->SQL-(操作)->DB
2、 表
什么是表?
表是一种结构化文件,可以用来存储特定类型的数据,如,学生信息,课程信息,都可以放到表中。另外表都有特定的名称,而且不可重复,表中具有几个概念:列、行。主键。
列叫字段(Column),行叫表中的记录,每一个字段都有:字段名称/字段数据类型/字段约束/字段长度。

3.SQL语句增删改查,如何分类?
DQL(数据查询语言):查询语句,凡是select语句都是DQL
DML(数据操作语言):insert 、delete、update,对表中的数据进行增删改。
DDL(数据定义语言):create drop alter ,对表的结构的增删改。
TCL(事务控制语言):commit提交事务,rollback回滚事务。(TCL中的T是Transaction)
DCL(数据控制语言):qrant授权、revoke撤销权限等
4.导入数据(这个不是sql语句,是mysql的)
dos命令:
第一步:登录mysql数据库管理系统
mysql -uroot -p333
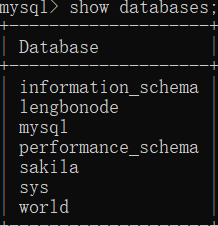
第二步:查看有哪些数据库
show databases;【mysql命令】
第三步 创建数据库
create database 名;
第四步 使用数据库
use 名
第五步 查看数据库中的表(查其其他库中的表后边要加个from 库名)
show tables;
最后一步:初始化数据库
source +数据库所在路径(.sql)可以直接拖过来
5.lengbonode.sql,这个文件以sql结尾,这样的文件被称为“sql脚本”。什么是sql脚本呢?
当一个文件的拓展名是sql,并且该文件中编写了大量的sql语句,我们称它为sql脚本
sql脚本数据量太大打不开时,可以使用source命令完成初始化。
6.删库跑路
drop database 名
7.‘desc’查看表结构
desc 表名;
查找dept;

MySQL常用命令:
mysql> select database();//查看当前使用的那个数据库
+------------+
| database() |
+------------+
| lengbonode |
+------------+
mysql> select version();//查看mysql的版本号。
+-----------+
| version() |
+-----------+
| 8.0.33 |
+-----------+
'\c'终止一条语句
‘exit’ 退出mysql
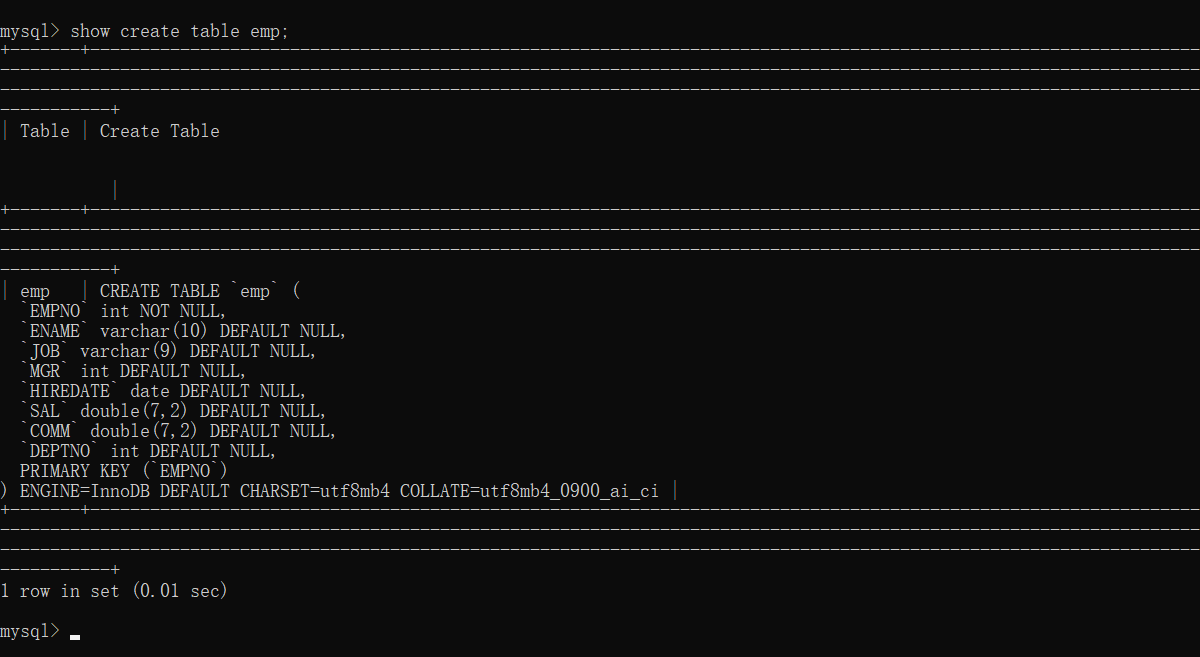
10,查看创建表的语句:
show create table 表名;
新建列
11.SQL简单查询语句(DQL)
语法格式:
查询多个字段。
select 字段名1,字段名2,字段名3,.....from 表名;
sal可以进行数学运算
重命名

as可以省略,
PS:1.任何一条sql语句以‘;’结尾。
2.sql语句不区分大小写。
3.标准sql中规定,输入字符串要用单引号括起来。
12 条件查询
语法格式:
select
字段1、字段2
from
表名
where
条件;
执行顺序:先from,然后where,最后select。
运算符:
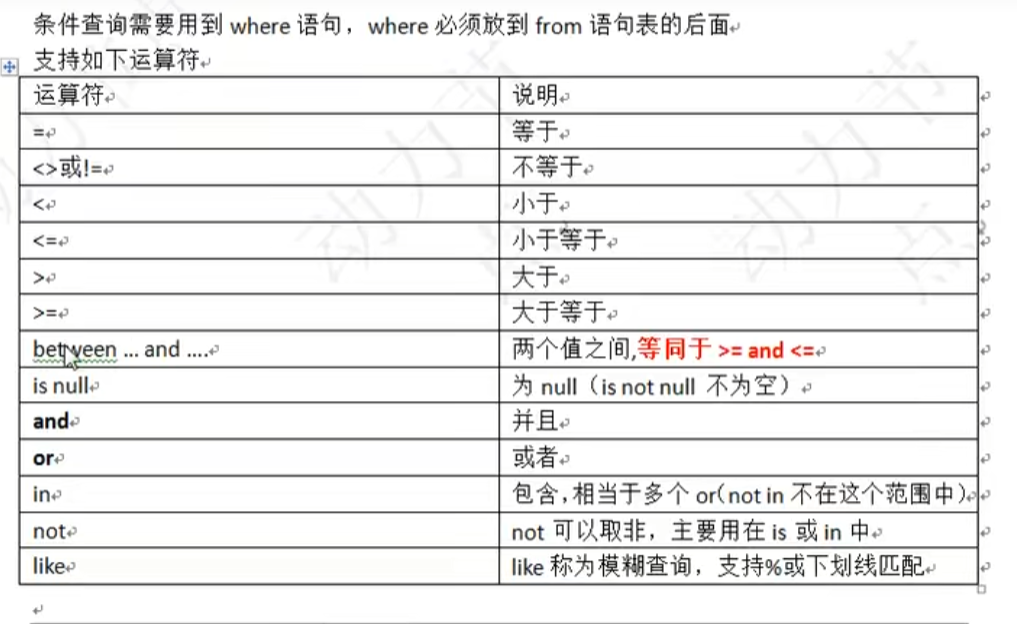
PS:
between那个要求左小右大的区间。
select ename from emp where ename between ‘A’ and ‘D’;//如果是字母比较的话,搜索出来的是[ A,D);左闭右开~,数字是【】都闭。
in=or in(1语句,2语句)同等于xxx =‘1语句’,xxx=‘2语句’(in后面不是区间,是具体的值。)
not in(,) :不在这几个值里
Like模糊查询


想用下划线用转义字符‘\’
数据排序
select
ename、sal
from
emp
order by
sal;
默认是升序排序,asc为升序,desc为降序。
PS:越在前的语句起主导作用,当前一个条件相等时才会用后一个条件。
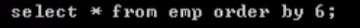
这样写数字表示这个表的第几列,不建议这么写,程序健壮性不好,还是老老实实写名字吧。
执行顺序

14.分组函数(多行处理函数)
count 计数
sum 求和
avg 平均值
max 最大
min 最小
什么是单行处理?
就是这个条件一行一行分别计算、输出还是多行
那什么是多行?
多行就是,这个表里面的一列或n列一起算,输出只有一行

ifnull函数
将可以将null替换成其他。 (下面代码含义是如果等于null,将comm换成0)

PS:1.分组函数自动忽略null
2.只要数学表达式里有null出现,不管运算结果是多少,都为null
3.分组函数不能出现在where语句里。

分组函数也可以连用


可以用嵌套select的形式解决

总结,排序在最后,条件在分组前


如何理解group by?
我的理解是,将一个组的相同的字段分为一组,如果是从多个列中分组就分别将组组合并,相同的字段分为一组。
举例子:
可以认为筛选字段,2个组结合的字段相同为一组。
举例子:找出每个部门最高工资,输出工资大于2900的数据
推荐使用where,效率高。它是没分组前执行

having过滤是group by后使用,也就是说,它是分组后才执行的,效率比where低

总结:group by 和 having 是绑定的,having不能单独使用,它是用来给分组后再次过滤筛选的。
如果能用where一定优先用where,因为where效率高,它在分组前就将数据筛选完了。
大总结!!!DQL查询语句顺序


distinct出现在所有字段的正前方。
如果distinct前有多个字段,表示多个字段联合起来去重。
2.连接查询
什么是连接查询?
从多张表联合查询取出最终结果。
2.1连接查询的分类?
有两种
sql92语法
sql99语法
根据表的连接形式来划分,包括:
内连接:
等值连接
非等值连接
自连接
外连接:
左外连接(左连接)
、 右外连接(右连接)
全连接:(很少用)
2.2笛卡尔积现象
当两张表连接查询时没有任何条件限制最终查询结果条数是两张表条数的乘积。
如何避免笛卡尔乘积现象?
:加条件过滤
but值得注意的是,条件过滤完它查询条数依然是乘积数,只是将符合条件的数表示出来了!!
2.3 表的别名
给表起名有什么好处?
一,执行效率高。(只会查询带该表名的表)
二,可读性好。
案例:找出每一个员工部门名称,要求显示员工名和部门名。
实际上还是56!!!!
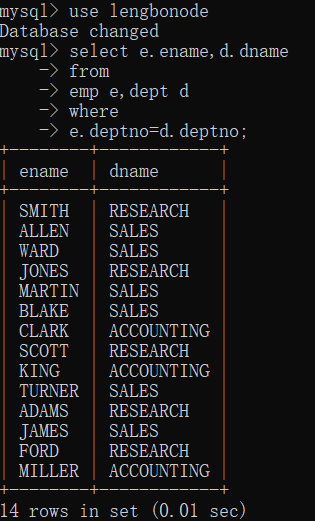
2.4 等值连接:
格式:

sql92:
sql99:
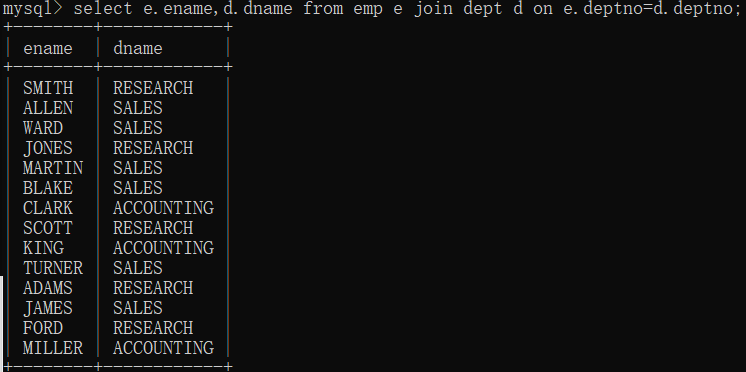
inner加上也行,可加可不加,表示内连接。

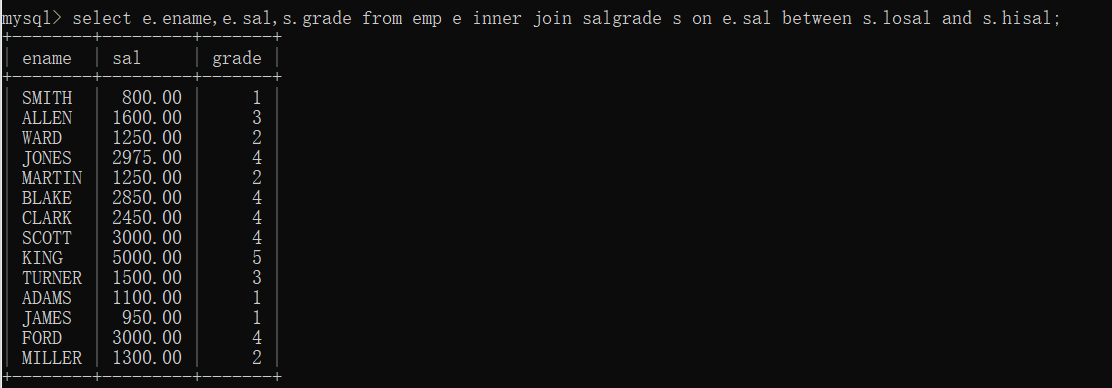
2.5非等值连接
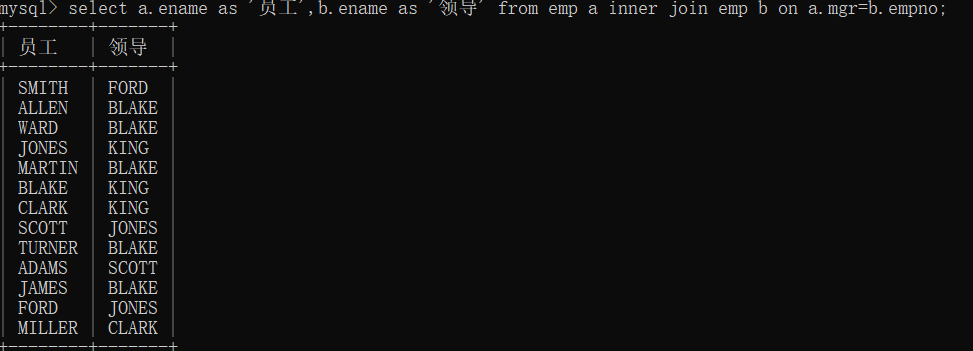
2.6 自连接:
什么是自连接?
一张表自己连自己就是自连接,用表名将表分成两张表,条件过滤。
3.外连接(包括等值连接,非等值连接,自连接)

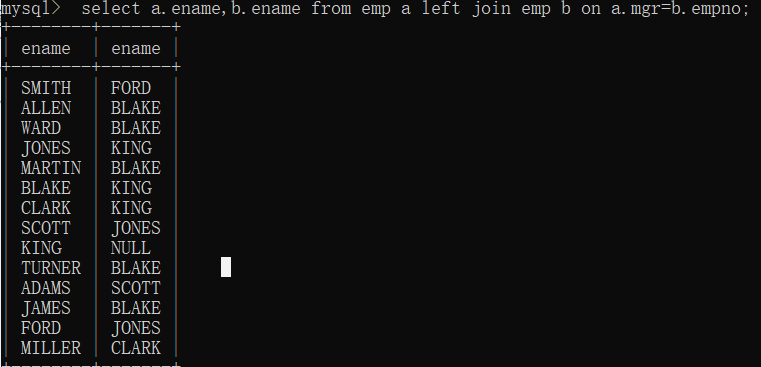

left outer /right outer
如何区分内外连接?
看join 前有没有left/right

总结:相对而言,内连接会损失数据,条件不匹配的不显示出来,而外连接不会,它会将不符合的输出null。
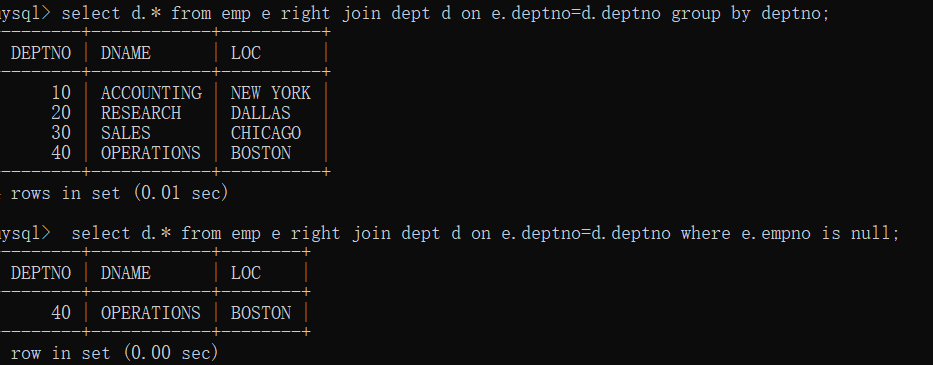
多张表怎么连接?

join都是按照第一个表连接的。
4,子查询

where子查询
案例:导出大于平均薪水
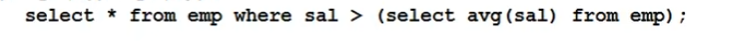
from子查询

把select语句当作一张新表,使用()表名的形式引用出来。
select子查询

4.union(查询结果集相加)

将两个查询结果相加为一张表上。

如果是不同位置的两张表相加,第二张表会直接加到第一张表的后面,值得注意的是,select列数必须相同,不然会报错。
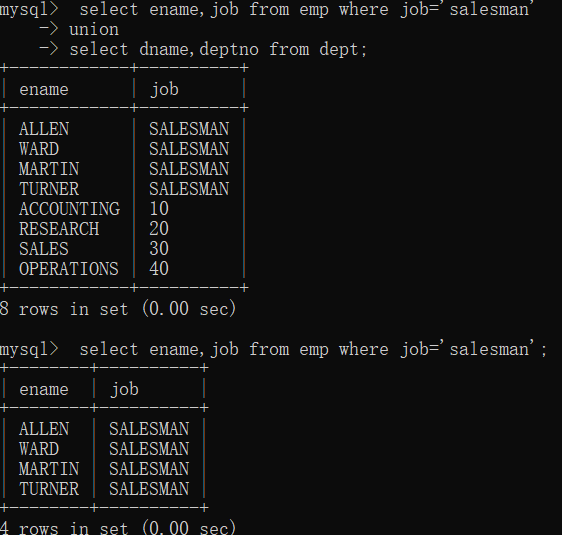
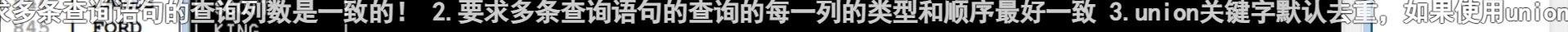

带EXist/not Exist关键字子查询(软考)
带EXIst的只返回逻辑值(真/假),不返回查询结果,当查询结果不是空值时就是真
出现时和while连用
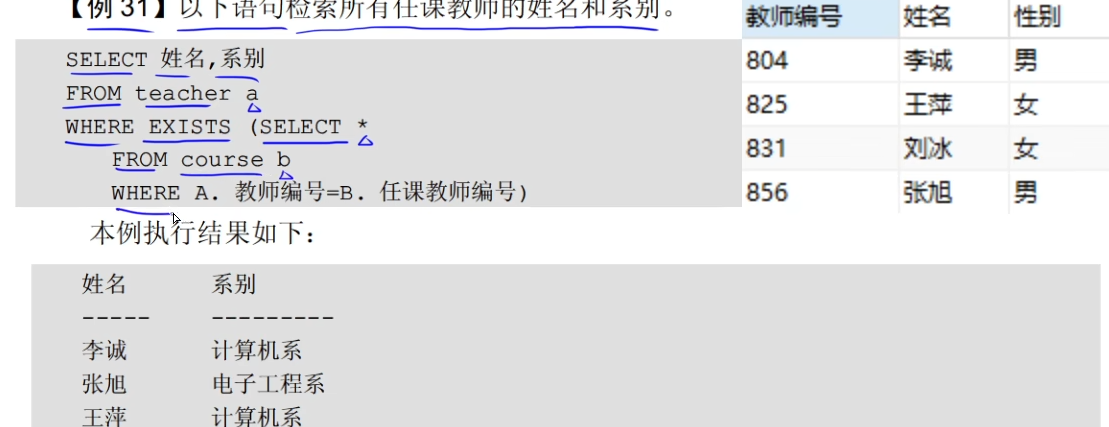
并交差(软考)
和数学当中的集合用法一致。
5,limit的使用(重点)分页查询


可以取区间,一个数就默认(0~那个数字)

(第n-1位数,取几个数)


------------------------------------------------------------------------------------------------------------------增----------------------------------------------------------------------------------------------------------------------------
创建表


ps(建表前得use一个数据库,表只能在数据库中创建)
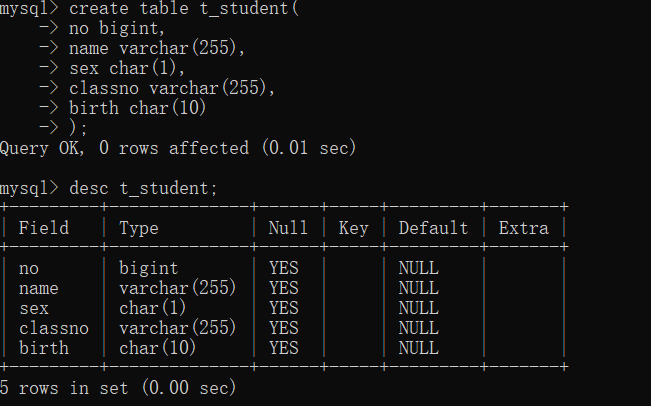

三种写法:
1.所有的全字段都写上
2.写一部分全字段,没写的默认赋值为null
3.可以在字段后边加default设置默认值。
ps:如果想改之前的值,只能用update了。
insert
格式:
insert into 表名(字段名,字段名...)values (填写数据,填写数据....)【第一组】,(填写数据,填写数据....)【第二组】(组数据和组数据之间用逗号隔开!)
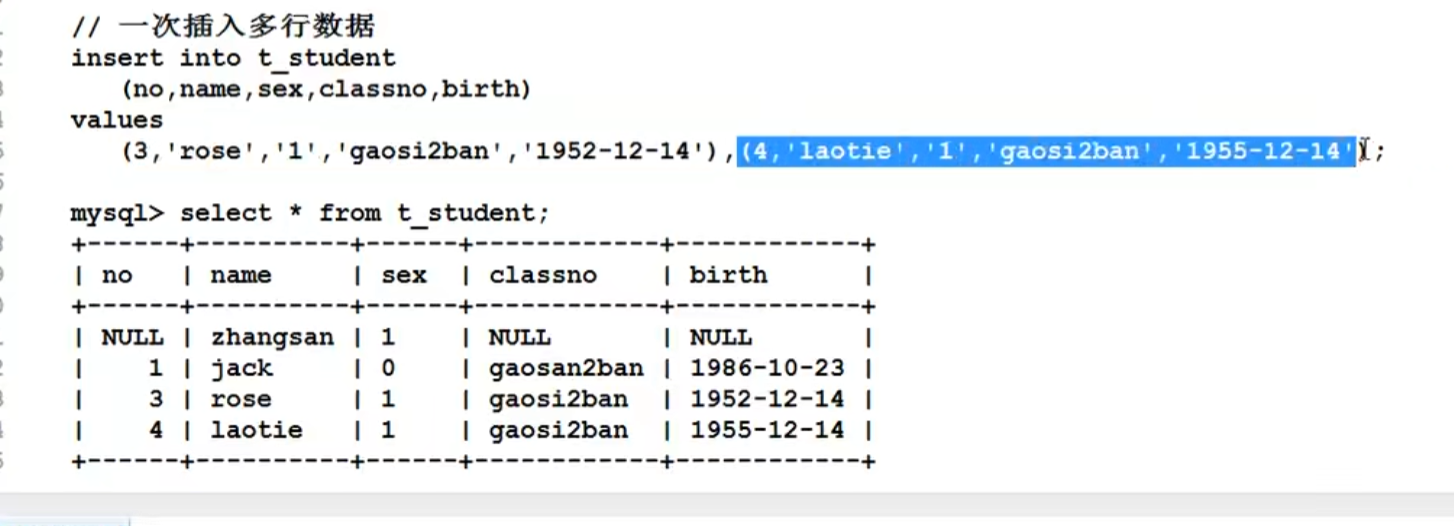
values与values间用,隔开。
8.表的复制:

--------------------------------------------------------------------------------------------------------------------------------改-----------------------------------------------------------------------------------------------------------------------------


--------------------------------------------------------------------------------------------------------------------------------删-----------------------------------------------------------------------------------------------------------------------------

delect可以恢复数据,但是对于数据庞大的表删起来时间很长。
truncate删的快,但是数据不可恢复,永久丢失。


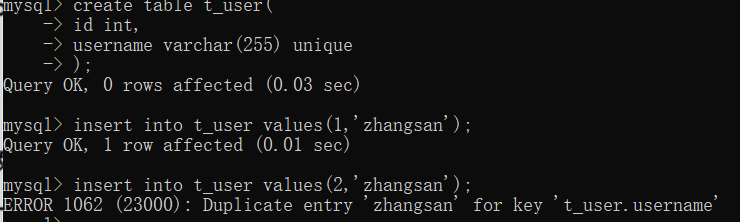
约束(重要)constraint





两个unique位置不同导致效果也不一样,第一个是( , )usercode,username两个字段连起来不能重复。
第二个是两个单独的字段不能重复,若我将两个字段赋值为111,111,第一个可以正常运行,第二个会报错。
ps:unique在列后添加是列级约束,在表最后加,是表级约束。
主键约束:

比如:身份证,有可能姓名,出生年月,家庭地址等等都一样,但,id不同,就是两个人,一个表中一定要有主键约束,不然无法标识表中数据。


也就是说?每个人的身份证都有一个自然数id??
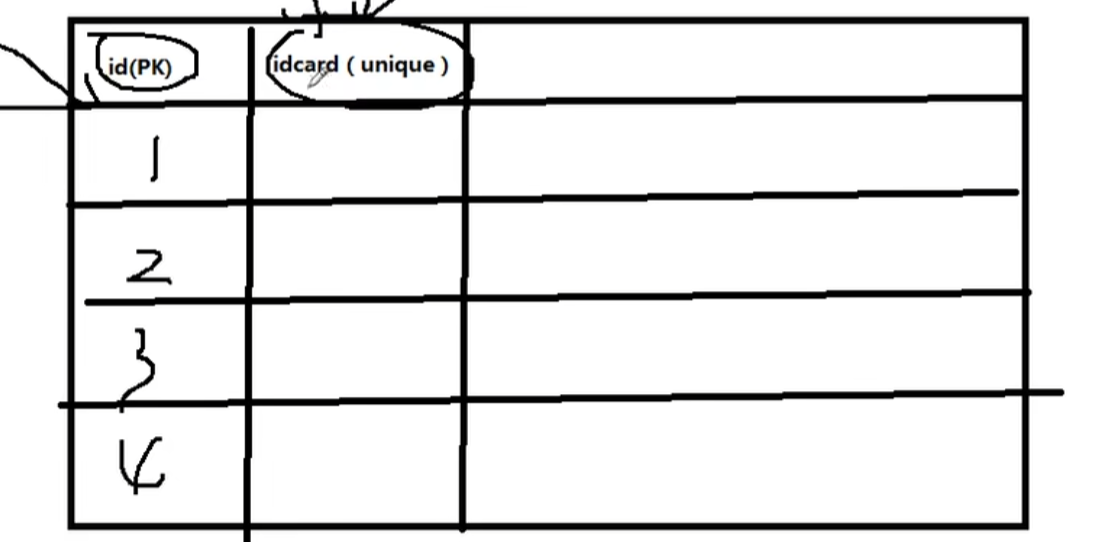

自增写了后以后就会自动维护一个数字了!!从1开始!

注册就是个很好的例子,以后补充下



一张表的外键是另一个表的主键。



事务:
什么是事务?

多条dml语句联合使用



提交,回滚,存档点
提交事务就真正修改硬盘上的数据了,当提交后,历史操作会清空。
回滚事务是将历史数据清空但不会修改数据。


第一级别:读未提交,事务中未提交但其他线程能够查到改动的代码。
线程一

线程二
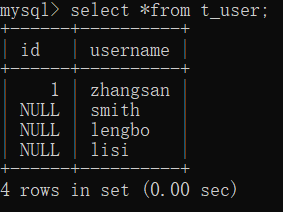
第二级别:读已提交
线程一:
mysql> select *from t_user;
+------+----------+
| id | username |
+------+----------+
| 1 | zhangsan |
| NULL | smith |
| NULL | lengbo |
| NULL | lisi |
+------+----------+
mysql> commit;
线程二:
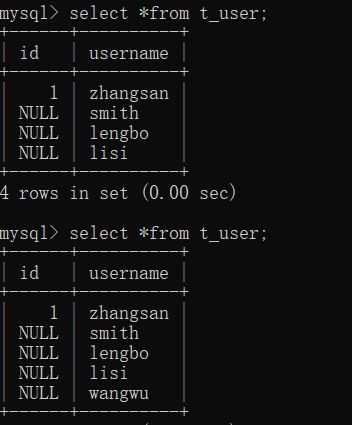
只有线程提交上事务以后其他线程才显示更改。
第三级别:可重复读
线程一:
mysql> delete from t_user;
Query OK, 5 rows affected (0.00 sec)
mysql> commit;
Query OK, 0 rows affected (0.00 sec)
已经删除user表并提交了
线程二:
但是这边还是能读到

读的是一个幻象,如果该线程不结束能一直读修改前的幻象。
第四阶级:Serializable序列化,排队机制。
线程一:该线程只要未提交或回滚(未结束),另一个线程会卡住进入等待状态
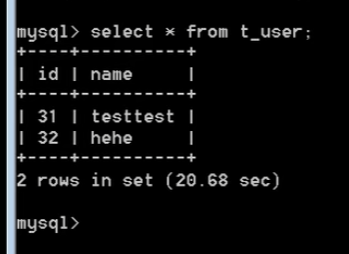
线程二:只要前一个线程结束这个线程才能进行。
Serlizeable在单一时刻只能有一个线程进行,其他线程进入等待状态。

如果想自己开启事务呢?

此时就可以进行,提交,回滚,存档点的操作

设置为读不提交级别。
mysql> set global transaction isolation level read uncommitted;
Query OK, 0 rows affected (0.00 sec)
查询事务级别
mysql> select @@transaction_isolation;
+-------------------------+
| @@transaction_isolation |
+-------------------------+
| READ-UNCOMMITTED |
+-------------------------+
索引:




all的意思就是全表扫描。

索引的底层原理:
每个表中的字段都存在一个物理地址,索引就是查找的对应的物理地址才能快速找到对应字段。
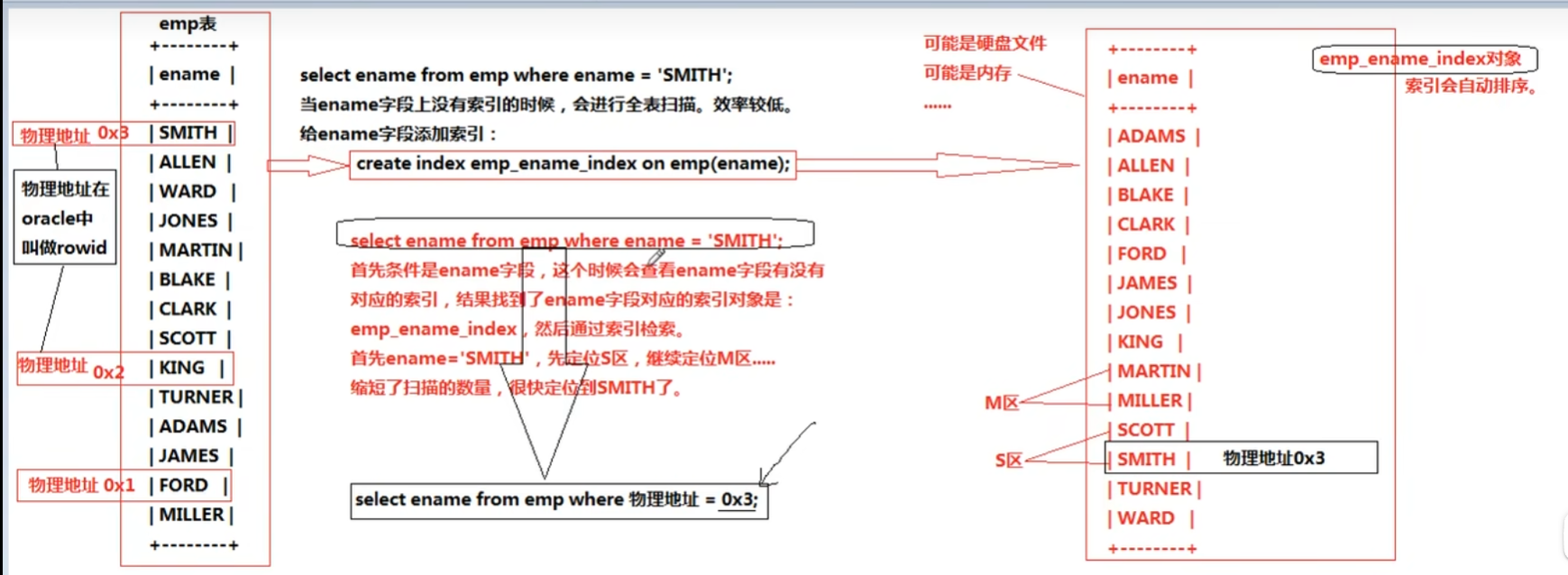


索引(软考)
索引存在三级结构中的内模式中,因为是找物理地址
视图:



视图(软考)
 with check option 是查询条件语句
with check option 是查询条件语句

导出到:

win10是反斜杠/

ps:在导入之前一定要先创建一个库,在库中在使用source导入
库又回来力~

表中的每个非主键字段完全依赖主键,不能产生部分依赖。(有多个主键的话,其他非主键字段都要和主键有关系,不能有的有有的没有!)

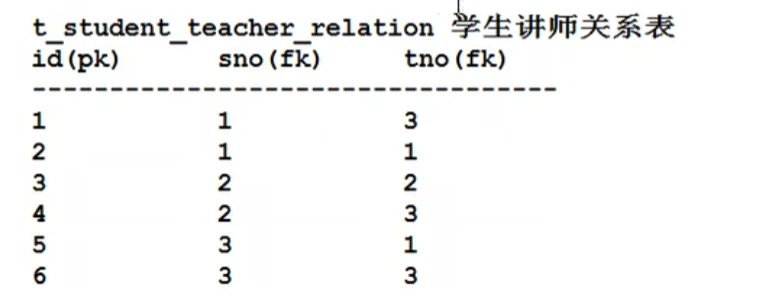



因为表表连接是遵循笛卡尔积的,查起来效率比较低,但是如果两张表合在一起就没事了......
主键就是外键

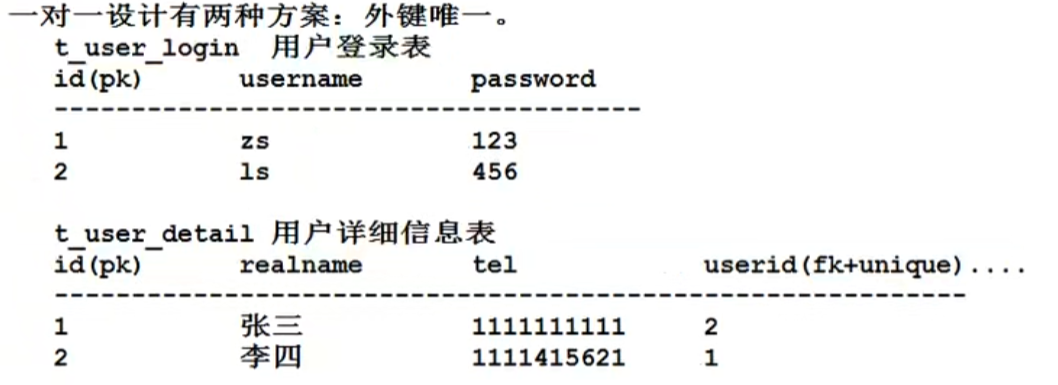
第二种方案:

 浙公网安备 33010602011771号
浙公网安备 33010602011771号