Jvm 中的 重排序、主存、原子操作
一、重排序
好处:重排序可以提升性能,避免在一个耗时很长的指令在“执行”阶段呆很长时间,而导致后续的指令都卡在“执行”之前的阶段上。
坏处:重排序对多线程的影响
class ReorderExample {
int a = 0;
boolean flag = false;
public void writer() {
a = 1; //1
flag = true; //2
}
Public void reader() {
if (flag) { //3
int i = a * a; //4
……
}
}
}
1) 数据依赖性:所以有数据依赖性的语句不能进行重排序。
2) as-if-serial:如果操作之间不存在数据依赖关系,这些操作可能被编译器和处理器重排序。但是不管怎么重排序,必须保证单线程程序的执行结果不能被改变,故单线程中重排序不需要被禁止(不影响执行结果)。
double pi = 3.14; // Ⓐ double r = 1.0; // Ⓑ double area = pi * r * r; // Ⓒ
Ⓐ -> Ⓑ -> Ⓒ 按程序顺序的执行结果:area = 3.14
Ⓑ -> Ⓐ -> Ⓒ 按重排序后的执行结果:area = 3.14
注:as-if-serial 语义把单线程程序保护了起来,遵守as-if-serial语义的编译器,写单线程的程序员有一个幻觉:单线程程序是按程序写的顺序来执行的。
3) happens-before 规则
- 程序顺序规则:按照程序代码的执行流顺序,(时间上)先执行的操作happen—before(时间上)后执行的操作。
- 监视器锁规则:对一个监视器锁的解锁,happens- before 于随后对这个监视器锁的加锁。
- volatile变量规则:对一个volatile域的写,happens- before 于任意后续对这个volatile域的读。
- 传递性:如果A happens- before B,且B happens- before C,那么A happens- before C。
二、主存与可见性
1. 主存与工作内存
计算机系统中,为了尽可能地避免处理器访问主内存的时间开销,处理器大多会利用缓存(cache)以提高性能。其模型如下图所示:
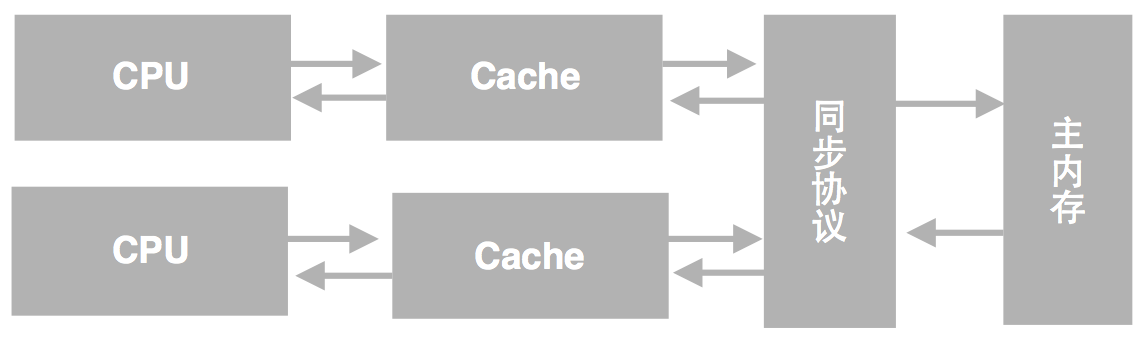
在这种模型下会存在一个现象,即缓存中的数据与主内存的数据并不是实时同步的,各CPU(或CPU核心)间缓存的数据也不是实时同步的。这导致在同一个时间点,各CPU所看到同一内存地址的数据的值可能是不一致的。从程序的视角来看,就是在同一个时间点,各个线程所看到的共享变量的值可能是不一致的。
有的观点会将这种现象也视为重排序的一种,命名为“内存系统重排序”。因为这种内存可见性问题造成的结果就好像是内存访问指令发生了重排序一样(实际上内存指令没有重排序,仅仅是内存可见性问题导致的结果)。
Java内存模型规定所有的变量都是存在主存当中,每个线程都有自己独立的工作内存,里面保存该线程的使用到的变量副本(该副本就是主内存中该变量的一份拷贝 )。线程对变量的所有操作都必须在工作内存中进行,而不能直接对主存进行操作。并且每个线程不能访问其他线程的工作内存。
2. 可见性
内存可见性其针对的是 共享资源在工作内存与主存之间的相互访问。
保证可见性的原义:指的是工作内存中对共享资源修改立即刷入到主存中,并且主存中的值立即同步到其它工作内存中。
它的实际实现方式可以是:
1) 使用 synchronized,线程在加锁时,先清空工作内存→在主内存中拷贝最新变量的副本到工作内存→执行完代码→将更改后的共享变量的值刷新到主内存中→释放互斥锁。
2) 使用 volatile,也就是对volatile变量执行写操作时,会在写操作后加入一条store指令,即强迫线程将最新的值刷新到主内存中,而其他工作内存中的值失效;而在读操作时,会加入一条load指令,即强迫从主内存(工作内存中的值已经失效)中读入变量的值。volatile 防止重排序针对的是内存屏障。但volatile不保证volatile变量的原子性。
三、原子操作
原子操作是指整个操作过程不会被线程调度机制打断。
使用 voilate 关键字 既可避免重排序问题,又可避免内存可见性问题,但无法解决非原子性问题。比如自增操作就不是原子性操作:
public class Test {
public volatile int inc = 0;
public void increase() {
inc++;
}
public static void main(String[] args) {
final Test test = new Test();
for(int i = 0; i < 10; i++) {
new Thread() {
public void run() {
for(int j = 0; j< 1000; j++)
test.increase();
};
}.start();
}
while(Thread.activeCount() > 1)
//保证前面的线程都执行完
Thread.yield();
System.out.println(test.inc);
}
}
这段程序的输出结果是多少?也许有些朋友认为是10000。但是事实上运行它会发现每次运行结果都不一致,都是一个小于10000的数字。
原因在于,自增操作是不具备原子性的,它包括读取变量的原始值、进行加1操作、写入工作内存。那么就是说自增操作的三个子操作可能会分割开执行,就有可能导致下面这种情况出现:
a) 线程1对变量进行自增操作:线程1先读取变量inc的原始值,然后线程1被阻塞了(还没有 inc 的值);
b) 然后线程2对变量进行自增操作:线程2也去读取变量inc的原始值,由于线程1只是对变量inc进行读取操作,而没有对变量进行修改操作,所以不会导致线程2的工作内存中缓存变量inc的缓 存行无效,所以线程2会直接去主存读取inc的值,发现inc的值时10,然后进行加1操作,并把11写入工作内存,最后写入主存。
c) 然后线程1接着进行加1操作,由于已经读取了inc的值,此时线程1的工作内存中inc的值仍然为10,所以线程1对inc进行加1操作后inc的值为11,然后将11写入工作内存,最后写入主存。
d) 那么两个线程分别进行了一次自增操作后,inc只增加了1。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号