


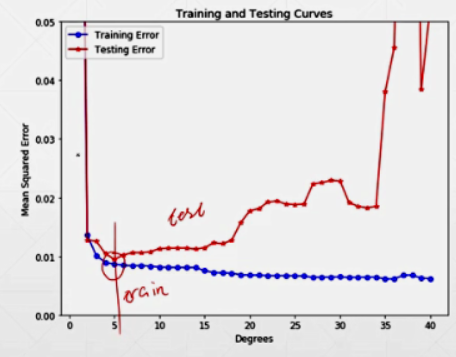
Overfitting & Train Set & Test Set
假设数据集是独立同分布的,可以将数据集划分为不同的比例:Train Set and Test Set.
同时在Train Set and Test Set上做精度测试,或者隔一段时间在Test Set上做测试,来判断训练模型是否发生过拟合,受否需要提前的终止,目的是选择最好的模型参数。(严格的说,其实应该是Validation)
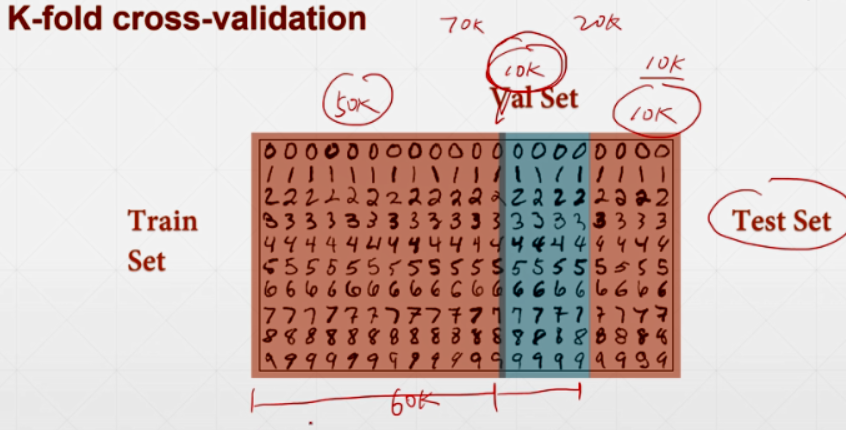
严格的会分为三部分:Train Set; Validation Set(提前终止,提高泛化能力); Test Set(不会得到)
K-fold cross-validation:每个数据都有可能back propagation。
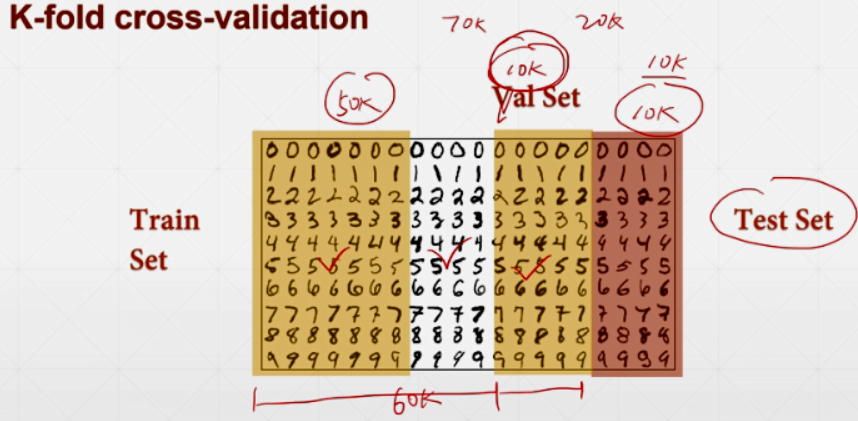
换着方式取Train Set,将能利用的数据都利用起来: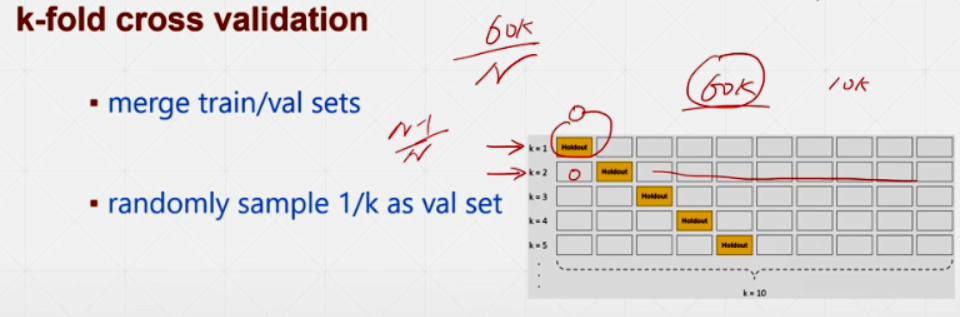
减缓过拟合的方法:

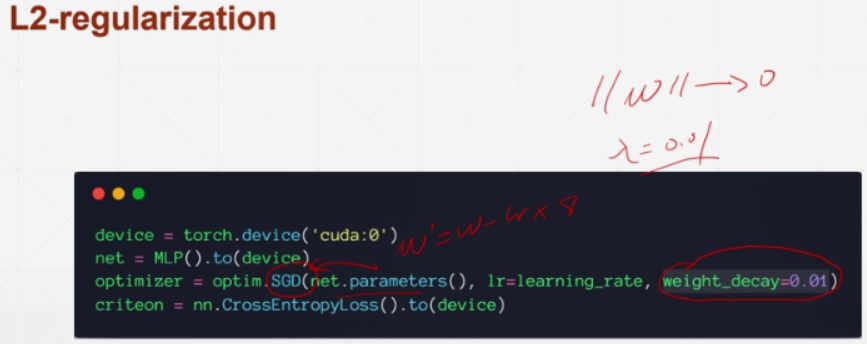
1) regularization
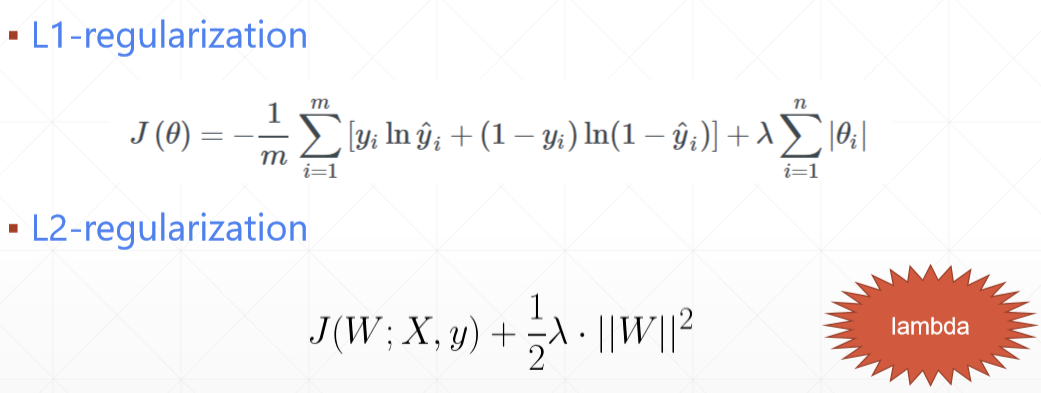

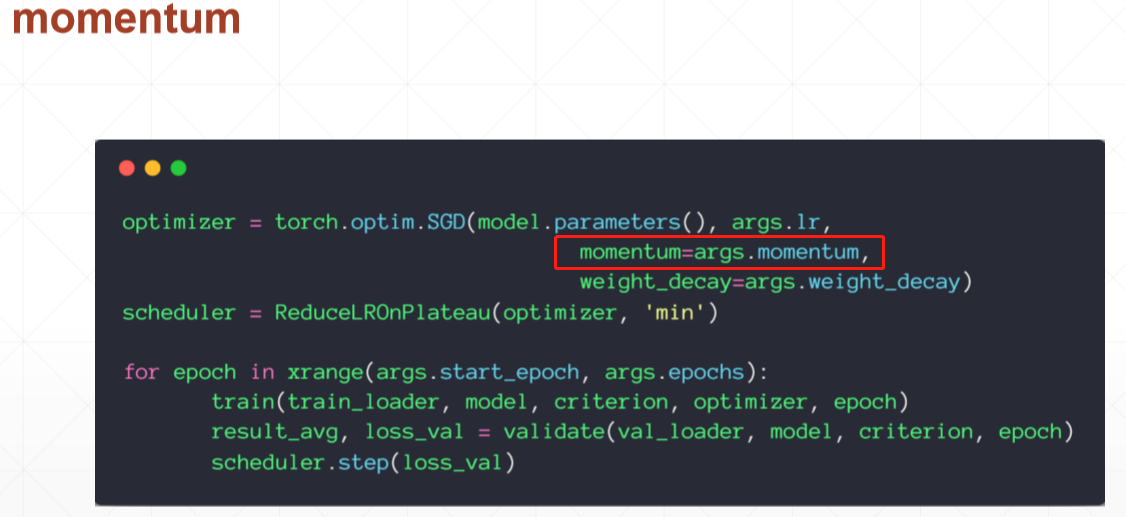
2)momentum
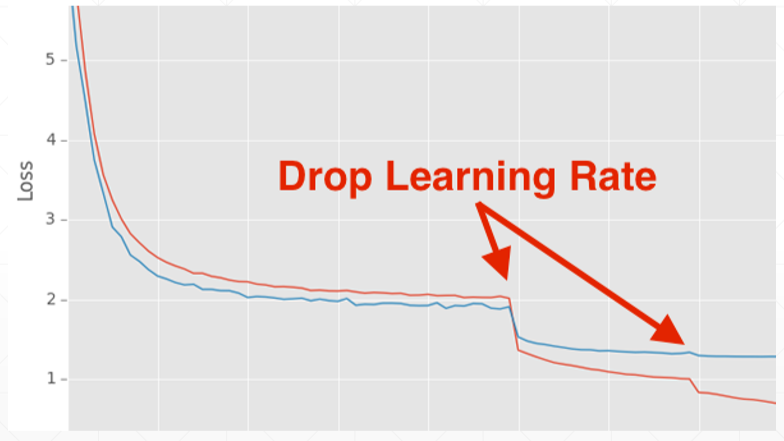
3)Learning rate tunning

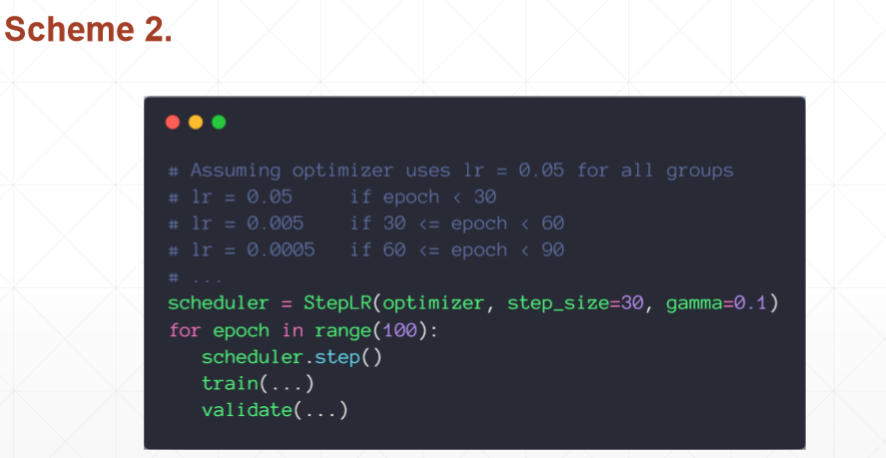
4)Early Stopping
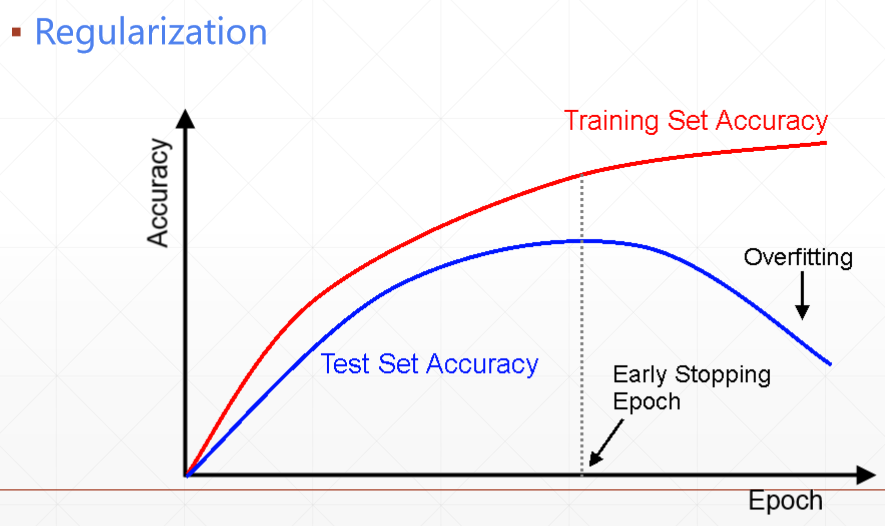

5)Dropout


pytorch和tensorflow中的Dropout参数含义是不同的

标签:
深度学习


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 开发者必知的日志记录最佳实践
· SQL Server 2025 AI相关能力初探
· Linux系列:如何用 C#调用 C方法造成内存泄露
· AI与.NET技术实操系列(二):开始使用ML.NET
· 记一次.NET内存居高不下排查解决与启示
· 阿里最新开源QwQ-32B,效果媲美deepseek-r1满血版,部署成本又又又降低了!
· 开源Multi-agent AI智能体框架aevatar.ai,欢迎大家贡献代码
· Manus重磅发布:全球首款通用AI代理技术深度解析与实战指南
· 被坑几百块钱后,我竟然真的恢复了删除的微信聊天记录!
· 没有Manus邀请码?试试免邀请码的MGX或者开源的OpenManus吧