自然语言处理
- 收集数据
- 经典数据集:Python NLTK 便提供了非常多经典的数据集。很多数据集都是手工标注而成,所以使用的时候不得不感叹工程的浩大。例如NLP中使用的Penn TreeBank,有兴趣的同学可以看看他们的论文《Building a Large Annotated Corpus of English: The Penn TreeBank》,那简直就是一部辛酸史啊!
- 从网页上抓取:直接动手写一个爬虫爬取特定的网页不难,通过正则表达式就能够将有效的内容提取出来;当然,发扬拿来主义精神的话,我们可以使用Python中一些优秀的库,比如scrapy,beautifulsoup 等等。
- 从日志、已有文件中分析:如果是海量数据的话可以使用hadoop这样的系统。结合传统SQL中的一些特殊功能,例如Partition,有时会有不错的效果,不过最多压缩空间、缩减特征再用SQL处理。
- 其他网络数据集:Stanford Large Network Dataset Collectionm,100+ Interesting Data Sets for Statistics
- 预处理
- 如果是网页内容,首先需要去掉Html Tag,lxml和html5lib是比较有名的Python库,beautifulsoup也对他们做了一层封装。不过别忘了,Python本身也自带了sgmllib这样的基本可扩展的解析器。如果是有特别的处理,其实正则表达式也是不错的选择。
- 处理编码,由于我主要是处理英文的数据,这一步基本也跳过了。
- 将文档分割成句子(可选)。很多时候我们采用的是词袋模型(bag of words),所以是否分割成句子也无所谓。比较简单的方法就是Python NLTK中的sent_tokenize()函数,用的是punkt算法,论文在这里。
- 将句子分割成词。首先用正则表达式可以自己完成;如果要利用已有工具,Python NLTK中的word_tokenize(),这个方式就是前文提到的Penn TreeBank语料库所使用的分词方法。听起来是不是很高大上,我是不会告诉你其实它也是正则表达式实现的,想知道具体实现,戳这里。分词其实主要干了这么几个事:1)将’分开. don't -> do n't, they'll -> they 'll; 2)将大部分标点当作单独的一个词; 3)将后一位是逗号或者引号的词分开; 4)单独出现在一行的句号分开。中文分词区别比较大,可以采用斯坦福或者ICTCLAS(中科院背景)的方案。
- 拼写错误纠正。推荐pyenchant,非常喜欢,因为简洁到四句语句就能完成。Windows 8中操作系统也直接提供了拼写检查的COM端口,不过就得多花时间研究啦。
- POS Tagging(根据实际应用)。还是Nltk,首页就有介绍;斯坦福也提供了这类工具。这一块属于NLP的范畴,还是Parsing等应用,要了解NLP原理推荐Coursera上一门不错的课程Natural Language Processing
- 去掉标点。正则表达式即可,有的时间非常短的单词也可以一起去掉,len<3的常见的选择
- 去掉非英文字符的词(根据实际应用决定)。
- 转换成小写。
- 去掉停用词。就是在各种句子中都经常出现的一些词,I、and什么的。NLTK有一个Stopwords。Matthew L. Jockers提供了一份比机器学习和自然语言处理中常用的停词表更长的停词表。中文停用词戳这里。什么?你问我停用词怎么找到的,我想大概是IDF这样的算法吧。
- 词型转换。简单来讲,我们希望do、did、done都能统一的返回do。第一种方法叫stem,Porter是比较常见的一种基于规则的算法,网页有snowball工具,也是它的论文。Porter的结果差强人意,单词末尾有e、y的,基本上stem之后都不间了,例如replace->replac;末尾有重复单词的,基本只剩一个了,例如ill->il。NLTK中也有Stem库,算法应该是类似的。第二种方法叫lemmatization,就是基于词典做词型转换,NLTK的Stem库中便有WordNetLemmatizer可以使用。
- 去掉长度过小的词(可选)。如果之前做了,这里要再做一次,因为stem会改变词型。
- 重新去停用词。理由同上。
- 训练
text3.count("smote")
100 * text4.count('a') / len(text4)
##定义计数函数
###词汇差异度,丰富度,越趋近1 越丰富(1 <= lexical_diversity <= len(text))
def lexical_diversity(text):
return len(text) / len(set(text))
###百分比
def percentage(count, total):
return 100 * count / total
7 载入你自己的语料库
(1) 将变量corpus_root的值设置为自己的语料的文件夹目录
(2) PlaintextCorpusReader 初始化函数的第二个参数可以是需要加载的文件,可以使用正则表达式
(3) CropsBPCRTest导入txt一类的数据很顺利,但是BracketParseCorpusReader载入宾州树库的实验是失败的,我看了自己的宾州树库语料库与书中描述的不一致但是不应该啊,还没有找到原因,先留下这个悬案,待日后再审。
#!/usr/python/bin #Filename:NltkTest59,一些关于语料库使用的测试 importnltk fromnltk.corpus import brown fromnltk.corpus import reuters fromnltk.corpus import inaugural fromnltk.corpus import udhr fromnltk.corpus import BracketParseCorpusReader fromnltk.corpus import PlaintextCorpusReader classNltkTest59: def __init__(self): print 'Initing...' def BrownTest(self,genres,modals): '''''来源于p59,对于不同问题的常用词统计的测试''' cfd = nltk.ConditionalFreqDist(\ (genre, word)\ for genre in brown.categories()\ for word inbrown.words(categories=genre)) cfd.tabulate(conditions=genres,samples=modals) def ReutersTest(self): # reuters.fileids() # reuters.categories() printreuters.categories('training/9865') printreuters.categories(['training/9865', 'training/9880']) # reuters.fileids('barley') # reuters.fileids(['barley', 'corn']) print reuters.words('training/9865')[:14] print reuters.words(['training/9865','training/9880']) printreuters.words(categories='barley') printreuters.words(categories=['barley', 'corn']) def InauguralTest(self): '''''运行会出错 ''' cfd=nltk.ConditionalFreqDist(\ (target, file[:4])\ for fileids in inaugural.fileids()\ for w in inaugural.words(fileids)\ for target in ['america','citizen']\ if w.lower().startswith(target)) cfd.plot() def UdhrTest(self): languages = ['Chickasaw', 'English','German_Deutsch',\ 'Greenlandic_Inuktikut','Hungarian_Magyar', 'Ibibio_Efik'] cfd=nltk.ConditionalFreqDist(\ (lang, len(word))\ for lang in languages\ for word in udhr.words(lang +'-Latin1')) cfd.plot(cumulative=False) def CropsPCRTest(self): corpus_root=r'C:\corpora\udhr2' file_pattern=r'.*' encoding='utf-8' pcr=PlaintextCorpusReader(corpus_root,file_pattern) print pcr.fileids() print pcr.words('007.txt') def CropsBPCRTest(self): '''''可耻的失败了,没法运行,可能是语料库版本问题,或者其他,待查''' corpus_root=r'C:\corpora\penntreebank\parsed' file_pattern=r'*.wsj' ptb=BracketParseCorpusReader(corpus_root, file_pattern) print ptb.fileids() print len(ptb.sents()) ptb.sents(fileids='\wsj_0001.mrg')[19] nt59=NltkTest59() genres= ['news', 'religion', 'hobbies', 'science_fiction', 'romance', 'humor'] modals= ['can', 'could', 'may', 'might', 'must', 'will'] #nt59.BrownTest(genres,modals) #nt59.ReutersTest() #不能运行,因为存在SOAP版本错误,不急着解决,以后再补一个解决方案 #nt59.InauguralTest() nt59.UdhrTest() #nt59.CropsPCRTest() #nt59.CropsBPCRTest()
##其他:
构建语料库与使用余料库https://my.oschina.net/kakablue/blog/321106
比较英文文档相似度https://my.oschina.net/kakablue/blog/314196
参考:
如何计算两个文档的相似度
http://www.52nlp.cn/%E5%A6%82%E4%BD%95%E8%AE%A1%E7%AE%97%E4%B8%A4%E4%B8%AA%E6%96%87%E6%A1%A3%E7%9A%84%E7%9B%B8%E4%BC%BC%E5%BA%A6%E4%B8%89
http://www.52nlp.cn/%E5%A6%82%E4%BD%95%E8%AE%A1%E7%AE%97%E4%B8%A4%E4%B8%AA%E6%96%87%E6%A1%A3%E7%9A%84%E7%9B%B8%E4%BC%BC%E5%BA%A6%E4%BA%8C
下面介绍如何利用NLTK快速完成NLP基本任务http://www.pythontip.com/blog/post/10012/
一、NLTK进行分词
用到的函数:
nltk.sent_tokenize(text) #对文本按照句子进行分割
nltk.word_tokenize(sent) #对句子进行分词

二、NLTK进行词性标注
用到的函数:
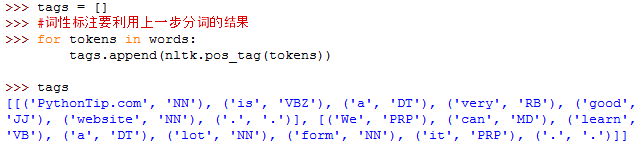
nltk.pos_tag(tokens)#tokens是句子分词后的结果,同样是句子级的标注
三、NLTK进行命名实体识别(NER)
用到的函数:
nltk.ne_chunk(tags)#tags是句子词性标注后的结果,同样是句子级
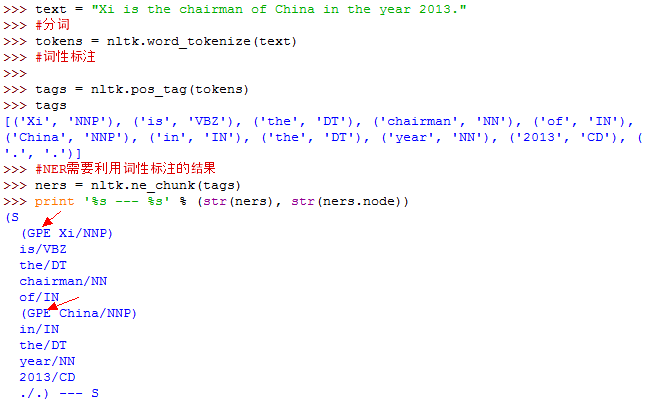
上例中,有两个命名实体,一个是Xi,这个应该是PER,被错误识别为GPE了; 另一个事China,被正确识别为GPE。
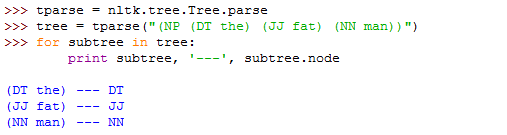
四、句法分析
词干提取:
https://marcobonzanini.com/2015/01/26/stemming-lemmatisation-and-pos-tagging-with-python-and-nltk/
The goal of both stemming and lemmatization is to reduce inflectional forms and sometimes derivationally related forms of a word to a common base form.
However, the two words differ in their flavor. Stemming usually refers to a crude heuristic process that chops off the ends of words in the hope of achieving this goal correctly most of the time, and often includes the removal of derivational affixes. Lemmatization usually refers to doing things properly with the use of a vocabulary and morphological analysis of words, normally aiming to remove inflectional endings only and to return the base or dictionary form of a word, which is known as the lemma .
From the NLTK docs:
Lemmatization and stemming are special cases of normalization. They identify a canonical representative for a set of related word forms.
-
Stemming reduces word-forms to (pseudo)stems, whereas lemmatization reduces the word-forms to linguistically valid lemmas. This difference is apparent in languages with more complex morphology, but may be irrelevant for many IR applications;
-
Lemmatization deals only with inflectional variance, whereas stemming may also deal with derivational variance;
-
In terms of implementation, lemmatization is usually more sophisticated (especially for morphologically complex languages) and usually requires some sort of lexica. Satisfatory stemming, on the other hand, can be achieved with rather simple rule-based approaches.
Lemmatisation is closely related to stemming. The difference is that a stemmer operates on a single word without knowledge of the context, and therefore cannot discriminate between words which have different meanings depending on part of speech. However, stemmers are typically easier to implement and run faster, and the reduced accuracy may not matter for some applications.

 浙公网安备 33010602011771号
浙公网安备 33010602011771号