通过简单示例来理解什么是机器学习
1 什么是机器学习
什么是机器学习?
这个问题不同的人员会有不同的理解。我个人觉得,用大白话来描述机器学习,就是让计算机能够通过一定方式的学习和训练,选择合适的模型,在遇到新输入的数据时,可以找出有用的信息,并预测潜在的需求。最终反映的结果就是,好像计算机或者其他设备跟人类一样具有智能化的特征,能够快速识别和选择有用的信息。
机器学习通常可以分为三个大的步骤,即 输入、整合、输出,可以用下图来表示大致的意思:
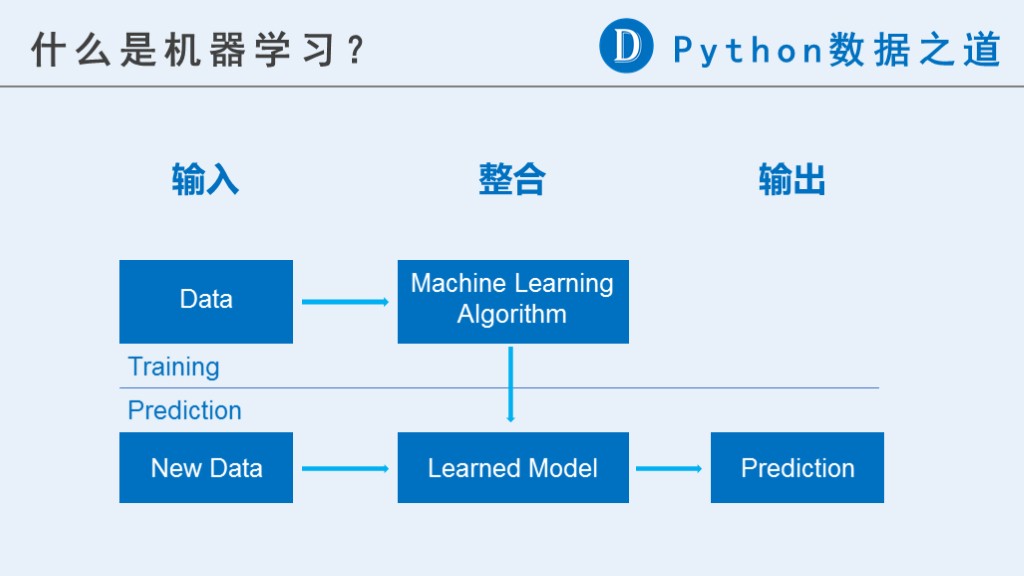
2 机器学习示例(scikit-learn)
在python语言中,scikit-learn是一个开源的机器学习库。下面以sklearn为例,来简单描述机器学习的过程。
2.1 加载数据
通常第一步是获取相关数据,并进行相应的处理,使之可以在后续过程中使用。
from sklearn import datasets
- 加载iris数据集并查看相关信息
# 加载数据集
iris = datasets.load_iris()
# print(iris)
print(type(iris))
print(iris.keys())
# 查看部分数据
print(iris.data[ :5, :])
# print(iris.data)
<class 'sklearn.datasets.base.Bunch'>
dict_keys(['DESCR', 'data', 'feature_names', 'target', 'target_names'])
[[ 5.1 3.5 1.4 0.2]
[ 4.9 3. 1.4 0.2]
[ 4.7 3.2 1.3 0.2]
[ 4.6 3.1 1.5 0.2]
[ 5. 3.6 1.4 0.2]]
# 查看数据维度大小
print(iris.data.shape)
# 数据属性
print(iris.feature_names)
# 特征名称
print(iris.target_names)
# 标签
print(iris.target)
(150, 4)
['sepal length (cm)', 'sepal width (cm)', 'petal length (cm)', 'petal width (cm)']
['setosa' 'versicolor' 'virginica']
[0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0
0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1
1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 1 2 2 2 2 2 2 2 2 2 2 2
2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2 2
2 2]
2.2 选择机器学习模型or算法
在获取数据,并将数据整理好后,需要选择合适的模型or算法来进行训练。
机器学习的模型有很多种,这里不作讨论,且每种模型的参数选择也是很大的一门学问。
from sklearn import svm
svm_classifier = svm.SVC(gamma=0.1, C=100)
# 预测结果得分很低
# svm_classifier = svm.SVC(gamma=10000, C=0.001)
# 定义测试集的数据量大小
N = 10
# 训练集
train_x = iris.data[:-N, :]
train_y = iris.target[ :-N]
# 测试集
test_x = iris.data[ :N, :]
y_true = iris.target[:N]
# 训练数据模型
svm_classifier.fit(train_x, train_y)
SVC(C=100, cache_size=200, class_weight=None, coef0=0.0,
decision_function_shape=None, degree=3, gamma=0.1, kernel='rbf',
max_iter=-1, probability=False, random_state=None, shrinking=True,
tol=0.001, verbose=False)
- 将训练好的模式进行测试
y_pred = svm_classifier.predict(test_x)
- 查看测试结果
from sklearn.metrics import accuracy_score
print(accuracy_score(y_true, y_pred))
1.0
2.3 将训练好的模型进行应用,即预测
- 保存模型
import pickle
with open('svm_model_iris.pkl', 'wb') as f:
pickle.dump(svm_classifier, f)
- 加载模型进行应用
import numpy as np
# np.random.seed(9)
with open('svm_model_iris.pkl', 'rb') as f:
model = pickle.load(f)
random_samples_index = np.random.randint(0,150,6)
random_samples = iris.data[random_samples_index, :]
random_targets = iris.target[random_samples_index]
random_predict = model.predict(random_samples)
print('真实值:', random_targets)
print('预测值:', random_predict)
真实值: [1 1 1 0 2 2]
预测值: [1 1 1 0 2 2]
闲谈
预测的结果好不好,直接体现出机器学习模型选择的优劣。对于机器学习这门高深的学问,我还有许多需要进一步学习的地方,欢迎一起交流,共同进步。
最后分享网上的一张图,来看看如何理解Machine Learning。

如果您喜欢我的文章,欢迎关注微信公众号:Python数据之道(ID:PyDataRoad)
作者:Lemon
出处:个人微信公众号:“Python数据之道”(ID:PyDataRoad)和博客园:http://www.cnblogs.com/lemonbit/
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文出处,否则保留追究法律责任的权利。
出处:个人微信公众号:“Python数据之道”(ID:PyDataRoad)和博客园:http://www.cnblogs.com/lemonbit/
本文版权归作者所有,欢迎转载,但未经作者同意必须保留此段声明,且在文章页面明显位置给出原文出处,否则保留追究法律责任的权利。

 浙公网安备 33010602011771号
浙公网安备 33010602011771号