
8、zookeeper的集群搭建
完全配置——https://zookeeper.apache.org/doc/r3.4.14/zookeeperAdmin.html#sc_zkMulitServerSetup https://zookeeper.apache.org/doc/r3.4.14/zookeeperAdmin.html#sc_configuration
首先我们要先理解一下zookeeper的选举机制
得到的票数/集群的总数 > 50%就成leader(这句话很关键)
当启动了130
130就会投自己一票 此时的到的总票数 1/3=30%
启动129:
129与130进行新一轮投票
129 投自己一票 1/3
130 投自己一票 1/3
pk投票
pk规则(选举的规则)
对比事物id(zxid)谁大就该投谁
假如出现事物id相同
比较服务器id谁大(myid),就改投谁。130=3 129=2
130胜出,129改投130
130 票数 2/3 = 66% > 50% leader
128启动时同理所以130必定当选leader
所以这个时候建议服务器性能比较好,设置他的id值大一些
当我们了解了zookeeper选举机制后就能来讲为什么集群需要2n+1个
1、防止由脑裂问题造成的集群不可用。
关于脑裂首先我们来讲一下什么是脑裂
在"双机热备"高可用(HA)系统中,当联系两个节点的"心跳线"断开时(即两个节点断开联系时),本来为一个整体、动作协调的HA系统,就分裂成为两个独立的节点(即两个独立的个体)。由于相互失去了联系,都以为是对方出了故障,两个节点上的HA软件像"裂脑人"一样,“本能"地争抢"共享资源”、争起"应用服务"。就会发生严重后果:
1)或者共享资源被瓜分、两边"服务"都起不来了;
2)或者两边"服务"都起来了,但同时读写"共享存储",导致数据损坏(常见如数据库轮询着的联机日志出错)。
两个节点相互争抢共享资源,结果会导致系统混乱,数据损坏。对于无状态服务的HA,无所谓脑裂不脑裂,但对有状态服务(比如MySQL)的HA,必须要严格防止脑裂
[但有些生产环境下的系统按照无状态服务HA的那一套去配置有状态服务,结果就可想而知]
首先,什么是脑裂?集群的脑裂通常是发生在节点之间通信不可达的情况下,集群会分裂成不同的小集群,小集群各自选出自己的master节点,导致原有的集群出现多个master节点的情况,这就是脑裂。
脑裂导致的问题
引起数据的不完整性:集群中节点(在脑裂期间)同时访问同一共享资源,而且没有机制去协调控制的话,那么就存在数据的不完整性的可能。
服务异常:对外提供的服务出现异常。
运行时复制的zookeeper
说明:对于复制模式,至少需要三个服务器,并且强烈建议您使用奇数个服务器。如果只有两台服务器,那么您将处于一种情况,如果其中一台服务器发生故障,则没有足够的计算机构成多数仲裁(zk采用的是过半数仲裁。因此,搭建的集群要容忍n个节点的故障,就必须有2n+1台计算机,这是因为宕掉n台后,集群还残余n+1台计算机,n+1台计算机中必定有一个最完整最接近leader的follower,假如宕掉的n台都是有完整信息的,剩下的一台就会出现在残余的zk集群中。也就是说:zk为了安全,必须达到多数仲裁,否则没有leader,集群失败,具体体现在leader选举-章)。由于存在两个单点故障,因此两个服务器还不如单个服务器稳定。
——关于2n+1原则,Kafka官网有权威的解释(虽然Kafka不采用)http://kafka.apache.org/0110/documentation.html#design_replicatedlog
多数仲裁的设计是为了避免脑裂
-
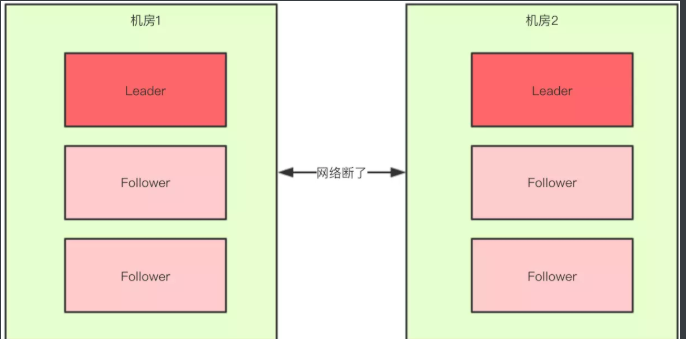
脑裂:由于网络延迟等各种因素,最终导致集群一分为二,各自独立运行(两个
leader),集群就是坏的 -
如果有两台服务器,两台都认为另外的
zk宕掉,各自成为leader运行(假设可以,实际上选不出leader,可以实际搭建一个集群,看看一台zk是否能够成功集群,详见leader选举),就会导致数据不一致。 -
如果有三台服务器,一台因为网络分区,无法连接,剩下两台网络正常,选举出了
leader,集群正常 -
以此类推
![]()
tickTime=2000 dataDir=/var/lib/zookeeper clientPort=2181 initLimit=5 syncLimit=2 server.1=zoo1:2888:3888 # 这是多机部署 server.2=zoo2:2888:3888 server.3=zoo3:2888:3888
-
-
对于这两个超时,您都可以使用tickTime指定时间单位。在此示例中,
initLimit的超时为5个滴答声,即2000毫秒/滴答声,即10秒 -
表格
server.X的条目列出了组成ZooKeeper服务的服务器。服务器启动时,它通过在数据目录中查找文件myid来知道它是哪台服务器。该文件包含ASCII的服务器号。 -
最后,记下每个服务器名称后面的两个端口号:
“ 2888”和“ 3888”。对等方使用前一个端口连接到其他对等方。这种连接是必需的,以便对等方可以进行通信,例如,以商定更新顺序。更具体地说,ZooKeeper服务器使用此端口将follower连接到leader。当出现新的leader者时,follower使用此端口打开与leader的TCP连接。因为默认的leader选举也使用TCP,所以我们当前需要另一个端口来进行leader
1.zookeeper核心
Zookeeper的核心是原子广播,这个机制保证了各个Server之间的同步。实现这个机制的协议叫做Zab协议。Zab协议有两种模式,它们分别是恢复模式(选主)和广播模式(同步)。当服务启动或者在领导者 崩溃后,Zab就进入了恢复模式,当领导者被选举出来,且大多数Server完成了和leader的状态同步以后,恢复模式就结束了。状态同步保证了leader和Server具有相同的系统状态。
• 为了保证事务的顺序一致性,zookeeper采用了递增的事务id号(zxid)来标识事务。所有的提议(proposal)都在被提出的时候加上了zxid。实现中zxid是一个64位的数字,它高32位是epoch用来标识leader关系是否改变,每次一个leader被选出来,它都会有一个新的epoch,标识当前属于那个leader的统治时期。低32位用于递增计数。
2、Zookeeper 的读写机制
» Zookeeper是一个由多个server组成的集群
» 一个leader,多个follower
»每个server保存一份数据副本
» 全局数据一致
» 分布式读写
» 更新请求转发,由leader实施
3、Zookeeper 的保证
» 更新请求顺序进行,来自同一个client的更新请求按其发送顺序依次执行
» 数据更新原子性,一次数据更新要么成功,要么失败
» 全局唯一数据视图,client无论连接到哪个server,数据视图都是一致的
» 实时性,在一定事件范围内,client能读到最新数据
4、Zookeeper节点数据操作流程
1.在Client向Follwer发出一个写的请求
2.Follwer把请求发送给Leader
3.Leader接收到以后开始发起投票并通知Follwer进行投票
4.Follwer把投票结果发送给Leader
5.Leader将结果汇总后如果需要写入,则开始写入同时把写入操作通知给Leader,然后commit;
6.Follwer把请求结果返回给Client

 浙公网安备 33010602011771号
浙公网安备 33010602011771号