Huffman编码和解码(C++)
关于哈夫曼树的讲解,已有珠玉在前,我就不赘述了。
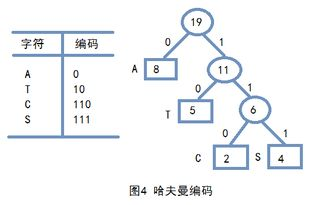
基本原理:统计字符串内的字符出现频率,由此建立哈夫曼树,频率高的离根结点越近,原则上左子树频率小于右子树。从根节点一路访问到叶子结点,路径权重即为结点字符的编码,且独一无二。解码过程就是从根节点遍历huffman树的过程。
编程实践:实现对纯英文字符串和文件的哈夫曼编码和解码。
代码如下:
#include <iostream>
#include <stdlib.h>
#include <string>
#include <map>
#include <fstream>
#include<math.h>
using namespace std;
map<char,string> huffcode; //用来存储字符编码
struct Node //结点数据结构
{
double weight;
char ch;
string code;
int lchild, rchild, parent;
};
void Select(Node huffTree[], int *a, int *b, int n) //找权值最小的两个a和b
{
int i;
double weight = 0; //找最小的数
for (i = 0; i <n; i++)
{
if (huffTree[i].parent != -1) //判断节点是否已经选过
continue;
else
{
if (weight == 0)
{
weight = huffTree[i].weight;
*a = i;
}
else
{
if (huffTree[i].weight < weight)
{
weight = huffTree[i].weight;
*a = i;
}
}
}
}
weight = 0; //找第二小的数
for (i = 0; i < n; i++)
{
if (huffTree[i].parent != -1 || (i == *a))//排除已选过的数
continue;
else
{
if (weight == 0)
{
weight = huffTree[i].weight;
*b = i;
}
else
{
if (huffTree[i].weight < weight)
{
weight = huffTree[i].weight;
*b = i;
}
}
}
}
int temp;
if (huffTree[*a].lchild < huffTree[*b].lchild) //小的数放左边
{
temp = *a;
*a = *b;
*b = temp;
}
}
void Huff_Tree(Node huffTree[], int w[], char ch[], int n)
{
for (int i = 0; i < 2 * n - 1; i++) //初始过程
{
huffTree[i].parent = -1;
huffTree[i].lchild = -1;
huffTree[i].rchild = -1;
huffTree[i].code = ""; //初始化
}
for (int i = 0; i < n; i++) //前n个节点为叶子结点
{
huffTree[i].weight = w[i];
huffTree[i].ch = ch[i];
}
for (int k = n; k < 2 * n - 1; k++)
{
int i1 = 0;
int i2 = 0;
Select(huffTree, &i1, &i2, k); //将i1,i2节点合成节点k
huffTree[i1].parent = k;
huffTree[i2].parent = k;
huffTree[k].weight = huffTree[i1].weight + huffTree[i2].weight;
huffTree[k].lchild = i1;
huffTree[k].rchild = i2;
}
}
void Huff_Code(Node huffTree[], int n)
{
int i, j, k;
string s;
for (i = 0; i < n; i++)
{
s = "";
j = i;
while (huffTree[j].parent != -1) //从叶子往上找到根节点
{
k = huffTree[j].parent;
if (j == huffTree[k].lchild) //如果是根的左孩子,则记为0
s = s + "0";
else
s = s + "1";
j = huffTree[j].parent;
}
cout << "字符 " << huffTree[i].ch << " 的编码:";
for (int l = s.size() - 1; l >= 0; l--) //反向回溯
{
cout << s[l];
huffTree[i].code += s[l]; //保存编码
}
huffcode[huffTree[i].ch] = huffTree[i].code;
cout << endl;
}
}
string Huff_Decode(Node huffTree[], int n,string s)
{
cout << "解码后为:";
string temp = "",str="";//保存解码后的字符串
for (int i = 0; i < s.size(); i++)
{
temp = temp + s[i];
for (int j = 0; j < n; j++)
{
if (temp == huffTree[j].code)
{
str=str+ huffTree[j].ch;
temp = "";
break;
}
else if (i == s.size()-1 && j==n-1 && temp!="")//全部遍历后没有
str= "解码错误!";
}
}
return str;
}
int main(){
cout << "编码字符串或文件(1/2):";
int cho,n; //n是编码个数
cin >> cho;
string s,res;
if(cho == 1)
{
cout << "输入字符串:" <<endl;
cin >> s;
}
else if(cho == 2)
{
//cout << "输入文件路径:" <<endl;
//cin >> s;
ifstream infile;
infile.open("Huffman.txt");
infile >> s;
infile.close();
cout << s << endl;
}
else
cout << "输入错误!" <<endl;
if(cho == 1 || cho ==2)
{
string res = "";
int i;
map<char,int> mp;
for(i=0;i<s.length();i++){
if(mp.count(s[i]) == 0)
mp[s[i]] = 1;
else
mp[s[i]] += 1;
}
map<char,int>::iterator iter;
iter = mp.begin(); //声明迭代器
n=mp.size(),i=0;
Node huffTree[2*n-1]; //所有节点数
char ch[n];
int w[n];
while(iter != mp.end())
{
ch[i] = iter->first;
w[i] = iter->second;
iter++;
i++;
}
mp.clear();
Huff_Tree(huffTree, w, ch, n);
Huff_Code(huffTree, n);
for(i=0;i<s.length();i++)
res += huffcode[s[i]];
if(cho == 1)
cout << "字符编码:" << endl << res << endl;
else{
ofstream outfile;
outfile.open("Huffman.txt");
outfile << res;
outfile.close();
cout << "文件编码完成!" <<endl;
}
i = 0;
while(pow(2,i) < n)
i++;
cout << "压缩率:" << (s.length()*i-res.length())*100/(s.length()*i) << "%" <<endl;
//解码过程
cout << "输入合法的编码:" <<endl;
cin >> s;
cout << Huff_Decode(huffTree, n, s)<< endl;
huffcode.clear();
}
return 0;
}
用map容器统计字符频率,之后放入数组排序,建立结构体数组当作哈夫曼树。
运行截图:
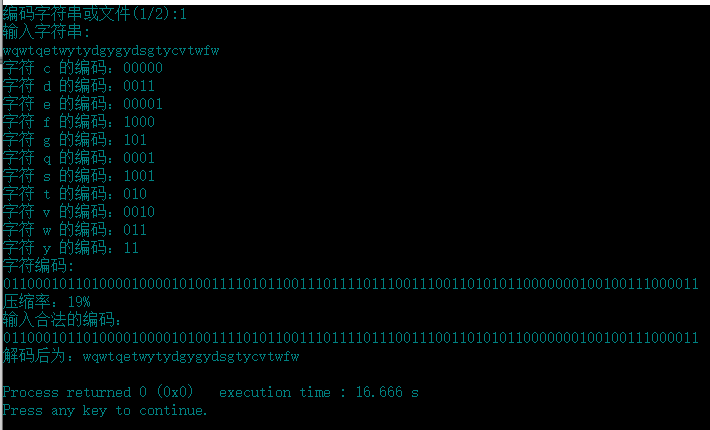

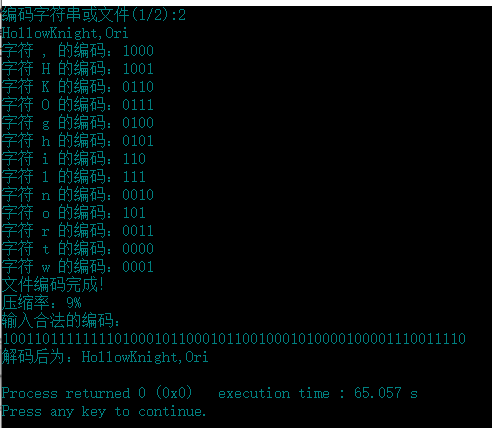
文件编码结果:

目前存在的问题:文件读取不到空格。
可完善的地方:结构体数组可以用int数组代替,但变化过程略复杂;map如果用允许自定义排序的话就不用另开一个数组。
---end---

 浙公网安备 33010602011771号
浙公网安备 33010602011771号