

Pytorch搭建BP神经网络
一、环境准备
PyTorch框架安装,上篇随笔提到了 如何安装 ,这里不多说。
matplotlib模块安装,用于仿真绘图。
一般搭建神经网络还会用到numpy、pandas和sklearn模块,pip安装即可,这里我没有用到。
import torch from torch.autograd import Variable import matplotlib.pyplot as plt
导入模块
二、数据处理
根据实际预测需求确定输入结点数和输出结点数,我的代码中inputnum、hiddennum、outputnum分别为(2,12,1)
神经网络框架接受的输入和输出都是张量(tensor)形式,需要将多维度的数组或矩阵转化到一个tensor中。如果不了解tensor,可以看:https://www.pytorch123.com/SecondSection/what_is_pytorch/
inputdata = torch.tensor(inputdata) outputdata = torch.tensor(outputdata)
还需要保证输入(input)数据和目标(target)数据的维度相同,用torch.unsqueeze()来对输入数据实现升维,torch.squeeze()来对预测值(predication)实现降维。
xtrain = torch.unsqueeze(torch.tensor(xtrain).float(), dim=1) #升维 xtest = torch.unsqueeze(torch.tensor(xtest).float(), dim=1)
这里 '.float()'的作用是使input和target数据类型一致,否则会报错。可以声明为其他类型,只要保持一致即可。
然后就是数据归一化处理,数据归一化处理主要包括数据同趋化处理(中心化处理)和无量纲化处理。不同评价指标往往具有不同的量纲和量纲单位,这样的情况会影响到数据分析的结果,为了消除指标之间的量纲影响,需要进行数据标准化处理,以解决数据指标之间的可比性。具体的实现方法有很多种,可以自行查找。常用的处理方法:

建议只对input做归一化处理,如果对target也做归一化处理,就需要对预测值做反归一化处理。
最后就是对数据做噪声处理,这里我采用的方案是对target做手动添加噪声。
ytrain = ytrain + 0.2*torch.rand(ytrain.size()) #加入噪声提高鲁棒性 ytest = ytest + 0.2*torch.rand(ytest.size())
加入噪声可以认为是在增加网络训练的难度,可以达到一定的正则效果,常见的比如dropout,数据增强中给输入数据加入噪声。输入层注入噪声,其实可以看作是数据集增强的一种手段,本质是一种正则化。原因是神经网络对于噪声并不健壮,只好混入噪声再进行训练,提高鲁棒性。输出层注入噪声,其实是对标签噪声建模。大部分数据集的label,总会有一定的错误率。
三、搭建神经网络
用框架搭建神经网络有两种方法:
import torch
import torch.nn.functional as F
# 方法1,通过定义一个Net类来建立神经网络
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
net1 = Net(2, 12, 1)
第二种方案比第一种简单许多,两个网络结构不同,但功能相似。
net1 = torch.nn.Sequential(
torch.nn.Linear(2, 12),
torch.nn.ReLU(), #激活函数
torch.nn.Linear(12, 1),
torch.nn.Softplus()
)
激活函数的选取一般是ReLU、Sigmoid和Softplus等,根据无限逼近原理,选取合适的激活函数和隐含层结点数就可以得到一个非线性函数。
其次,搭建完神经网络可能需要保存网络结构或参数,具体操作看这里 save()
四、训练和测试数据
本例中6000组训练集数据,2000组测试集数据。
optimizer = torch.optim.SGD(net1.parameters(), lr=0.5) #梯度下降方法
loss_function = torch.nn.MSELoss() #计算误差方法
# 训练部分
for i in range(500):
prediction = net1(xtrain)
prediction = prediction.squeeze(-1)
loss = loss_function(prediction, ytrain)
if loss.data <= 0.06:
break
optimizer.zero_grad() #消除梯度
loss.backward() #反向传播
optimizer.step() #执行
lr是学习率,可以自己决定参数大小,也可以选用动态学习率。训练终止条件可以设置也可以不设置。如果不了解代码中的各个函数什么意思,推荐参考pytorch官方文档。
# 首先搭建相同的神经网络结构
net2 = torch.nn.Sequential(
torch.nn.Linear(2, 12),
torch.nn.ReLU(),
torch.nn.Linear(12, 1),
torch.nn.Softplus()
)
# 载入神经网络的模型参数
net2.load_state_dict(torch.load('net_params.pkl'))
prediction = net2(xtest)
prediction = prediction.squeeze(-1)
如果你之前保存了训练出的参数,那么你需要调用参数文件,然后再进行预测。
五、预测数据处理
可以自己选取要观测的数值,然后用matplotlib绘图。
plt.title('net2')
plt.scatter(ytest.data.numpy(), prediction.data.numpy())
plt.plot(ytest.data.numpy(), ytest.data.numpy(),'r--')
plt.show()
最终结果如下:
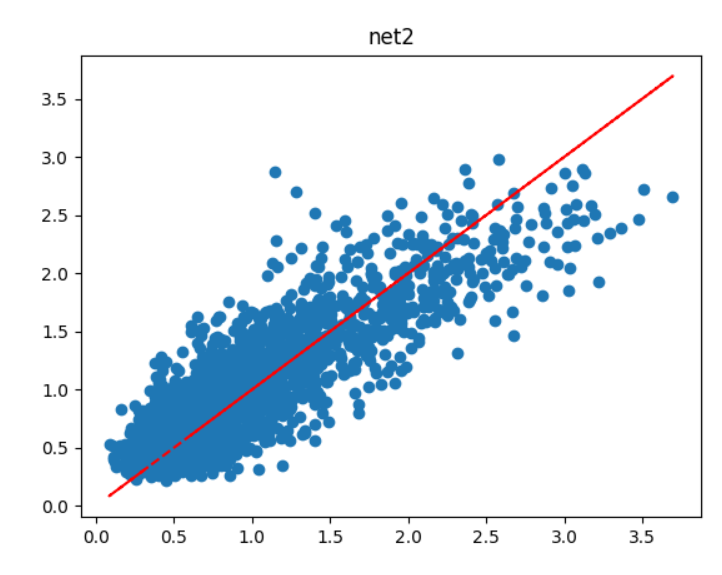
可以看到,预测结果还是可信的。

