1. 加载数据
from keras.datasets import imdb
(train_data,train_labels),(test_data,test_labels) = imdb.load_data(num_words=10000) # num_words表示保留训练数据中前10000个出个最常出现的单词,舍弃低频单词
<__array_function__ internals>:5: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
E:\my_software\anaconda3\lib\site-packages\tensorflow\python\keras\datasets\imdb.py:159: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
x_train, y_train = np.array(xs[:idx]), np.array(labels[:idx])
E:\my_software\anaconda3\lib\site-packages\tensorflow\python\keras\datasets\imdb.py:160: VisibleDeprecationWarning: Creating an ndarray from ragged nested sequences (which is a list-or-tuple of lists-or-tuples-or ndarrays with different lengths or shapes) is deprecated. If you meant to do this, you must specify 'dtype=object' when creating the ndarray
x_test, y_test = np.array(xs[idx:]), np.array(labels[idx:])
train_data[0]
[1,
14,
22,
16,
43,
530,
973,
1622,
1385,
65,
458,
4468,
66,
3941,
4,
173,
36,
256,
5,
25,
100,
43,
838,
112,
50,
670,
2,
9,
35,
480,
284,
5,
150,
4,
172,
112,
167,
2,
336,
385,
39,
4,
172,
4536,
1111,
17,
546,
38,
13,
447,
4,
192,
50,
16,
6,
147,
2025,
19,
14,
22,
4,
1920,
4613,
469,
4,
22,
71,
87,
12,
16,
43,
530,
38,
76,
15,
13,
1247,
4,
22,
17,
515,
17,
12,
16,
626,
18,
2,
5,
62,
386,
12,
8,
316,
8,
106,
5,
4,
2223,
5244,
16,
480,
66,
3785,
33,
4,
130,
12,
16,
38,
619,
5,
25,
124,
51,
36,
135,
48,
25,
1415,
33,
6,
22,
12,
215,
28,
77,
52,
5,
14,
407,
16,
82,
2,
8,
4,
107,
117,
5952,
15,
256,
4,
2,
7,
3766,
5,
723,
36,
71,
43,
530,
476,
26,
400,
317,
46,
7,
4,
2,
1029,
13,
104,
88,
4,
381,
15,
297,
98,
32,
2071,
56,
26,
141,
6,
194,
7486,
18,
4,
226,
22,
21,
134,
476,
26,
480,
5,
144,
30,
5535,
18,
51,
36,
28,
224,
92,
25,
104,
4,
226,
65,
16,
38,
1334,
88,
12,
16,
283,
5,
16,
4472,
113,
103,
32,
15,
16,
5345,
19,
178,
32]
train_labels[0]
1
word_index = imdb.get_word_index() # 将单词映射为整数索引的字典
# 将整数索引映射为单词
reverse_word_index = dict(
[(value,key) for (key,value) in word_index.items()]
)
# 将评论解码
# i-3 paddding 、start of sequence、unknown、保留索引
decoded_review = ' '.join(
[reverse_word_index.get(i-3,'?') for i in train_data[0]]
)
2. 将整数序列编码为二进制矩阵
import numpy as np
def vectorize_sequences(sequences,dimension=10000):
# 创建形状为(len(sequences),dimension)食物零矩阵
results = np.zeros((len(sequences),dimension))
for i, sequences in enumerate(sequences):
results[i,sequences] = 1 # 将results[i]的指定索引设为1
return results
x_train = vectorize_sequences(train_data) # 将训练数据向量化
x_test = vectorize_sequences(test_data) # 将测试数据向量化
x_train.shape
x_train[0]
array([0., 1., 1., ..., 0., 0., 0.])
x_test.shape
x_test[0]
array([0., 1., 1., ..., 0., 0., 0.])
# 将标签向量化
y_train = np.asarray(train_labels).astype('float32')
y_test = np.asarray(test_labels).astype('float32')
y_train
array([1., 0., 0., ..., 0., 1., 0.], dtype=float32)
y_test
array([0., 1., 1., ..., 0., 0., 0.], dtype=float32)
3. 构建网络
# 模型定义
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16,activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16,activation='relu'))
model.add(layers.Dense(1,activation='sigmoid'))
4. 编译模型
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
5.配置优化器
from keras import optimizers
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss='binary_crossentropy',
metrics=['accuracy'])
6. 自定义损失和指标
from keras import losses
from keras import metrics
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss=losses.binary_crossentropy,
metrics = [metrics.binary_accuracy])
7. 留出验证集
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
8. 训练模型
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['acc'])
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val,y_val))
Epoch 1/20
30/30 [==============================] - 6s 137ms/step - loss: 0.6149 - acc: 0.6893 - val_loss: 0.4173 - val_acc: 0.8633
Epoch 2/20
30/30 [==============================] - 1s 33ms/step - loss: 0.3482 - acc: 0.8993 - val_loss: 0.3179 - val_acc: 0.8861
Epoch 3/20
30/30 [==============================] - 1s 28ms/step - loss: 0.2478 - acc: 0.9261 - val_loss: 0.2951 - val_acc: 0.8857
Epoch 4/20
30/30 [==============================] - 1s 28ms/step - loss: 0.1934 - acc: 0.9394 - val_loss: 0.2740 - val_acc: 0.8904
Epoch 5/20
30/30 [==============================] - 1s 27ms/step - loss: 0.1523 - acc: 0.9566 - val_loss: 0.2881 - val_acc: 0.8845
Epoch 6/20
30/30 [==============================] - 1s 27ms/step - loss: 0.1294 - acc: 0.9624 - val_loss: 0.2855 - val_acc: 0.8859
Epoch 7/20
30/30 [==============================] - 1s 26ms/step - loss: 0.1056 - acc: 0.9713 - val_loss: 0.2986 - val_acc: 0.8846
Epoch 8/20
30/30 [==============================] - 1s 29ms/step - loss: 0.0858 - acc: 0.9791 - val_loss: 0.3196 - val_acc: 0.8824
Epoch 9/20
30/30 [==============================] - 1s 28ms/step - loss: 0.0714 - acc: 0.9821 - val_loss: 0.3501 - val_acc: 0.8742
Epoch 10/20
30/30 [==============================] - 1s 27ms/step - loss: 0.0595 - acc: 0.9862 - val_loss: 0.3557 - val_acc: 0.8801
Epoch 11/20
30/30 [==============================] - 1s 28ms/step - loss: 0.0464 - acc: 0.9898 - val_loss: 0.3814 - val_acc: 0.8785
Epoch 12/20
30/30 [==============================] - 1s 28ms/step - loss: 0.0356 - acc: 0.9933 - val_loss: 0.4075 - val_acc: 0.8765
Epoch 13/20
30/30 [==============================] - 1s 27ms/step - loss: 0.0306 - acc: 0.9944 - val_loss: 0.4390 - val_acc: 0.8730
Epoch 14/20
30/30 [==============================] - 1s 27ms/step - loss: 0.0241 - acc: 0.9960 - val_loss: 0.4865 - val_acc: 0.8744
Epoch 15/20
30/30 [==============================] - 1s 27ms/step - loss: 0.0186 - acc: 0.9975 - val_loss: 0.5017 - val_acc: 0.8692
Epoch 16/20
30/30 [==============================] - 1s 26ms/step - loss: 0.0132 - acc: 0.9989 - val_loss: 0.5573 - val_acc: 0.8700
Epoch 17/20
30/30 [==============================] - 1s 26ms/step - loss: 0.0118 - acc: 0.9989 - val_loss: 0.5675 - val_acc: 0.8711
Epoch 18/20
30/30 [==============================] - 1s 26ms/step - loss: 0.0082 - acc: 0.9993 - val_loss: 0.6111 - val_acc: 0.8701
Epoch 19/20
30/30 [==============================] - 1s 26ms/step - loss: 0.0057 - acc: 0.9998 - val_loss: 0.6308 - val_acc: 0.8685
Epoch 20/20
30/30 [==============================] - 1s 25ms/step - loss: 0.0040 - acc: 0.9998 - val_loss: 0.6980 - val_acc: 0.8664
history_dict = history.history
history_dict.keys()
dict_keys(['loss', 'acc', 'val_loss', 'val_acc'])
9. 绘制训练损失和验证损失
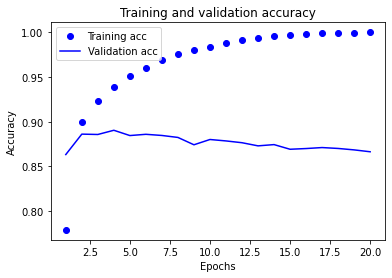
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1,len(loss_values)+1)
plt.plot(epochs,loss_values,'bo',label='Training loss')
plt.plot(epochs,val_loss_values,'b',label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
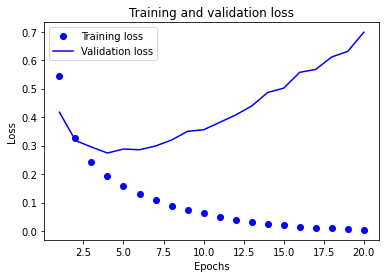
10. 绘制训练精度和验证精度
plt.clf() #清空图像
acc = history_dict['acc']
val_acc = history_dict['val_acc']
plt.plot(epochs,acc,'bo',label='Training acc')
plt.plot(epochs,val_acc,'b',label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()