

论文阅读笔记:《Interconnected Question Generation with Coreference Alignment and Conversion Flow Modeling》
论文阅读;《Interconnected Question Generation with Coreference Alignment and Conversion Flow Modeling》
作者:Yifan Gao, Piji Li, Irwin King, Michael R.yu
论文来源:ACL2019
WHAT
CQG会话问题生成,对于给定文章最终想要生成会话QA对的形式,并且要在每轮对话中实现平稳的过渡。
使用共指想要生成相互关联的问题。
HOW
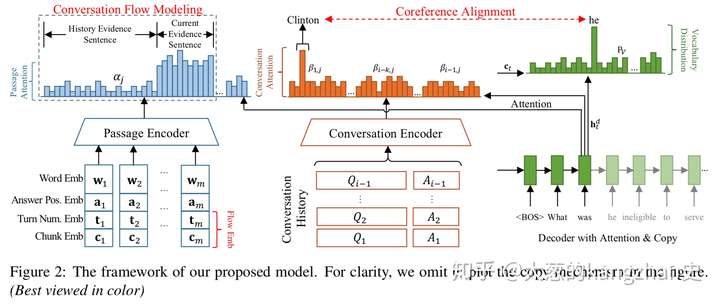
一、 模型
1.多源编码器(使用bi-LSTM)
- 文章编码器
输入词嵌入、答案位置嵌入,在每个答案位置嵌入要使用BIO标签打在答案位置嵌入上,获得一个隐藏状态
2)会话编码器
使用<q><a>标记历史QA对,形成一个QA序列;先使用词级Bi-LSTM生成关于上下文的隐藏状态,再使用上下文级Bi-LSTM生成关于上下文之间依赖的隐藏状态
2.具有注意力机制和复制机制的解码器(LSTM)
解码器的本身应该决定在每个解码时间步长时应该更多的关注段落隐藏层还是历史对话隐藏层状态。这里用到的是seq2seq模型的计算方法,计算出词注意力权重和文章注意力权重,对话注意力权重,然后计算上下文向量,和单词的概率分布。
3.共指对比建模
会话问题的关键是使用共指回溯历史会话。
共指建模的作用是查看看正确的非共指代词以生成公指代词的参考词
预处理阶段:使用共指消解系统找到共指关系
训练阶段:引入损失函数
4.会话流建模
1)流嵌入
在段落编码器中引入了一个门控自注意建模机制,通过答案位置嵌入的自注意力机来获得与答案相关的有效信息,通过嵌入轮数和块来更好的会话流建模。这里需要了解一下self-maching
门控的实质就是一个全连接层
2)流损失
目的:应该关注当前证据句而忽视历史证据句
二、 实验
数据集的准备:CoQA,ATM获得
步骤:
定位答案位置
会话历史轮数的确定(对话中的大多数问题在两轮内具有有限的依赖关系,因此,选择历史轮数为3,确保目标问题具有足够的转换历史信息来生成,避免从所有QA对的回合中引入过多的噪声)
有监督的训练
Feeling
相比于前人的工作,此模型的确有很大的进步,创新性也值得借鉴,但是本模型是抽取式的问答,生成的问题也是很简单的问题,如果想要实现对复杂问题的生成或者想要包含深度语义信息的问题此模型并不能解决。
研一NLP初学小白,欢迎各路大神一起讨论。
