tidbv3.0日志查询系统
整体链路
filebeat ----> kakfa----> logstash(ruby) -----> elk
filebeat
采集主机上服务日志和慢日志推送到kafka
filebeat.inputs:
- type: log
paths:
- "/databases/deploy/log/tidb_slow_query.log"
- "/databases/deploy/log/tidb_slow_query.log"
fields:
service: tidb_slow
ip: yourip
cluster: clustername (用于区分多集群)
exclude_lines: ['COMMIT', 'commitTxn', 'mysql.', 'commit;']
multiline.pattern: "# Time:"
multiline.negate: true
multiline.match: after
tail_files: true
fields_under_root: true
scan_frequency: 1s
- type: log
paths:
- "/databases/deploy/log/pd.log"
- "/databases/deploy/log/tidb.log"
- "/databases/deploy/log/tikv.log"
fields:
service: tidb_serverlog
ip: yourip
cluster: com
exclude_lines: ['pushgateway','connection closed','new connection']
tail_files: true
fields_under_root: true
scan_frequency: 1s
- type: log
paths:
- "/data/log/mongodb/*.log"
- "/data/mongodb*/log/*.log"
fields:
service: mongodb_slow
ip: yourip
include_lines: ['ms']
exclude_lines: ['Successfully', 'killcursors', 'oplog.rs', 'admin.', 'config.']
multiline.pattern: "^20"
multiline.negate: true
multiline.match: after
tail_files: true
fields_under_root: true
scan_frequency: 1s
processors:
- drop_fields:
fields: ["beat", "offset", "input", "prospector"]
output.kafka:
hosts: ["kafka1.zzq.com:9092", "kafka2.zzq.com:9092", "kafka3.zzq.com:9092"]
topic: "beat-%{[service]}"
partition.round_robin:
reachable_only: false
required_acks: 1
compression: none
max_message_bytes: 10000000
logstash 主要是进行grok 对日志进行格式化
filter{
if [service] == "tidb_slow_new" {
ruby {
code => "
begin
a=event.get('message')
generate_time = a.scan(/# Time:\s(.*?)\n/)
if generate_time.length > 0
event.set('generate_time',generate_time)
end
user = a.scan(/# User:\s(.*?)@(.*?)\n/)
if user.length > 0
event.set('user',user[0][0])
event.set('client_ip',user[0][1])
end
query_time = a.scan(/Query_time:\s([1-9]\d*\.\d*|0\.\d*[1-9]\d*)\n/)
if query_time.length > 0
event.set('query_time',query_time[0][0].to_f)
end
process_time = a.scan(/Process_time:\s([1-9]\d*\.\d*|0\.\d*[1-9]\d*)/)
if process_time.length > 0
event.set('process_time',process_time[0][0].to_f)
end
compile_time = a.scan(/Compile_time:\s([1-9]\d*\.\d*|0\.\d*[1-9]\d*)/)
if compile_time.length > 0
event.set('compile_time',compile_time[0][0].to_f)
end
request_count = a.scan(/Request_count:\s(\d+?)/)
if request_count.length > 0
event.set('request_count',request_count[0][0].to_i)
end
total_keys = a.scan(/Total_keys:\s(\d+)/)
if total_keys.length > 0
event.set('total_keys',total_keys[0][0].to_i)
end
process_keys = a.scan(/Process_keys:\s(\d+)/)
if process_keys.length > 0
event.set('process_keys',process_keys[0][0].to_i)
end
db = a.scan(/# DB: (.*?)\n/)
if db.length > 0
event.set('DB',db[0][0])
end
is_internal = a.scan(/# Is_internal: (.*?)\n/)
if is_internal.length > 0
event.set('is_internal',is_internal[0][0])
end
index_name = a.scan(/# Index_names: \[([a-z_0-9]*?):([a-z_0-9]*?)\]\n/)
if index_name.length > 0
event.set('index_name',index_name[0][1])
event.set('table_name',index_name[0][0])
end
table = a.scan(/# Stats:\s([a-z_0-9]*?):(.*?)\n/)
if table.length > 0
event.set('table',table[0][0])
if table.include?(',')
table_list = table.split(/[,:]/)
event.set('sql_stat',table_list[1])
event.set('table_1',table_list[1])
event.set('sql_stat_1',table_list[2])
else
event.set('sql_stat',table[0][1])
end
else
table_spc = a.scan(/(INSERT INTO|from|UPDATE|FROM|update|insert into|analyze table|ALTER table|alter table|replace into)\s{1,3}(\S*?)[\s;]{1,3}/)
if table_spc.length > 0
str1=table_spc[0][1]
table_spc_list = str1.gsub(/\`/,'').split(/\./)
event.set('table',table_spc_list[0])
if !event.get('DB')
event.set('DB',table_spc_list[0])
end
end
end
digest = a.scan(/# Digest: (.*?)\n/)
if digest.length > 0
event.set('digest',digest[0][0])
end
num_cop_tasks = a.scan(/# Num_cop_tasks: (\d+?)\n/)
if num_cop_tasks.length > 0
event.set('num_cop_tasks',num_cop_tasks[0][0].to_i)
end
cop_proc_avg = a.scan(/# Cop_proc_avg: ([1-9]\d*\.\d*|0\.\d*[1-9]\d*) /)
if cop_proc_avg.length > 0
event.set('cop_proc_avg',cop_proc_avg[0][0].to_f)
end
cop_proc_p90 = a.scan(/Cop_proc_p90: ([1-9]\d*\.\d*|0\.\d*[1-9]\d*) /)
if cop_proc_p90.length > 0
event.set('cop_proc_p90',cop_proc_p90[0][0].to_f)
end
cop_proc_max = a.scan(/Cop_proc_max: ([1-9]\d*\.\d*|0\.\d*[1-9]\d*) /)
if cop_proc_max.length > 0
event.set('cop_proc_max',cop_proc_max[0][0].to_f)
end
cop_proc_addr = a.scan(/Cop_proc_addr: (.*?):(.*?)\n/)
if cop_proc_addr.length > 0
event.set('cop_proc_addr',cop_proc_addr[0][0])
event.set('cop_proc_port',cop_proc_addr[0][1])
end
cop_wait_avg = a.scan(/# Cop_wait_avg: ([1-9]\d*\.\d*|0\.\d*[1-9]\d*|\d*) /)
if cop_wait_avg.length > 0
event.set('cop_wait_avg',cop_wait_avg[0][0].to_f)
end
cop_wait_p90 = a.scan(/Cop_wait_p90: ([1-9]\d*\.\d*|0\.\d*[1-9]\d*|\d*) /)
if cop_wait_p90.length > 0
event.set('cop_wait_p90',cop_wait_p90[0][0].to_f)
end
cop_wait_max = a.scan(/Cop_wait_max: ([1-9]\d*\.\d*|0\.\d*[1-9]\d*|\d*) /)
if cop_wait_max.length > 0
event.set('cop_wait_max',cop_wait_max[0][0].to_f)
end
cop_wait_addr = a.scan(/Cop_wait_addr: (.*?):(.*?)\n/)
if cop_wait_addr.length > 0
event.set('cop_wait_addr',cop_wait_addr[0][0])
event.set('cop_wait_port',cop_wait_addr[0][1])
end
mem_max = a.scan(/# Mem_max: (\d+?)\n/)
if mem_max.length > 0
event.set('mem_max',mem_max[0][0].to_i)
end
succ = a.scan(/# Succ: (\w+?)\n/)
if succ.length > 0
event.set('succ',succ[0][0])
end
txn_retry = a.scan(/ Txn_retry: (\d+?)\n/)
if txn_retry.length > 0
event.set('txn_retry',txn_retry[0][0].to_i)
end
sql = a.scan(/\n([^#]{1}.*)/)
if sql.length > 0
event.set('sql',sql[0][0])
end
rescue
puts $!
a1 = event.get('message')
event.set('message_origin',a1)
ensure
event.remove('message')
end
"
}
}
}
ELK 展示界面
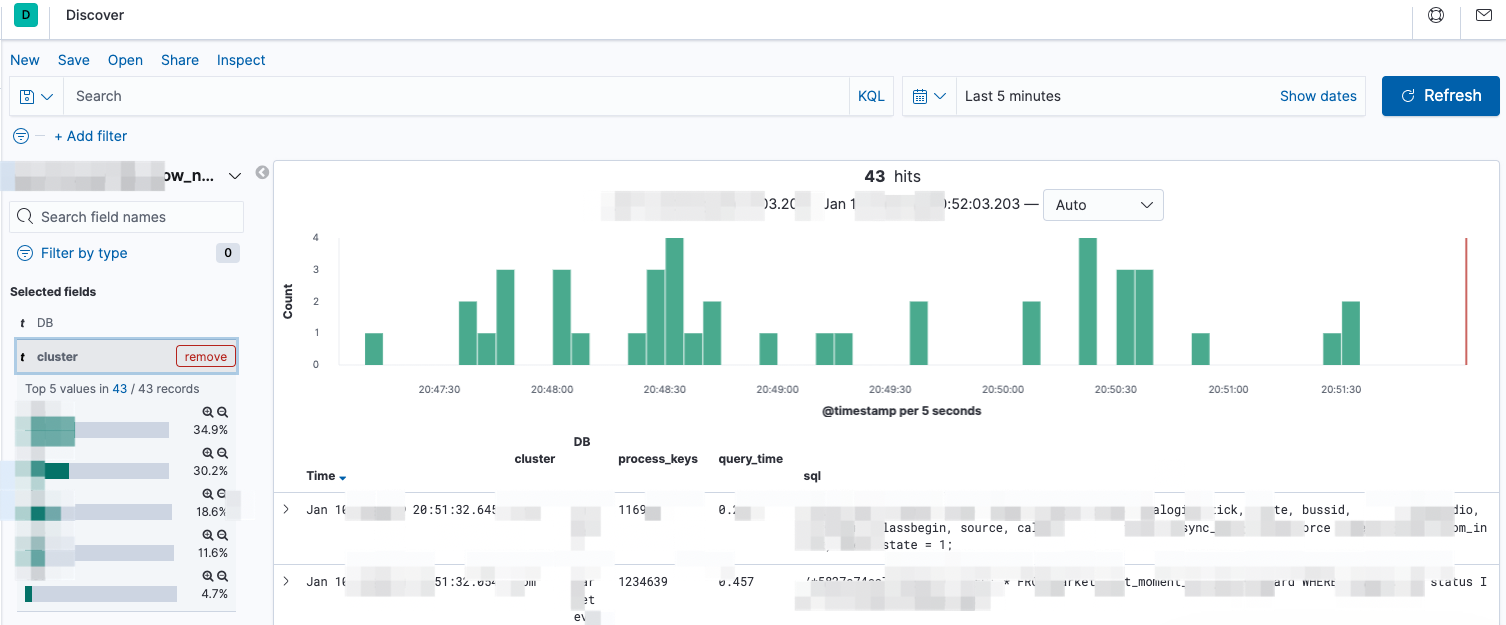
根据集群选择查看指定集群日志,故障时期按照process_keys 和 query_time 强排序 快速定位慢sql,根据慢sql digest 进行同类sql 汇聚操作
FAQs
- tidb 3.0 没有集成慢日志系统,需要自行补齐.高版本有成型的慢日志体系
- tidb 3.0 中server 组件分布式部署,每个节点的slow_query log 都要收集否则会有遗漏。高版本中已经存在 cluster slow query 的概念更便捷
- 慢日志字段顺序非定式,使用logstash 常规grok 常常会出现日志无法解析的情况。需要使用ruby 脚本进行字符串正则过滤
本文来自博客园,作者:萱乐庆foreverlove,转载请注明原文链接:https://www.cnblogs.com/leleyao/p/17041375.html
