

python爬取快手ios端首页热门视频
最近快手这种小视频app,特别的火,中午吃过午饭,闲来无聊,想搞下快手的短视频,看能不能搞到。
于是乎,
打开了fiddler,开始准备抓包,

设置代理,重启,下一步,查看本机ip

手机打开网络设置
通过代理服务器;
设置好,刷新快手app
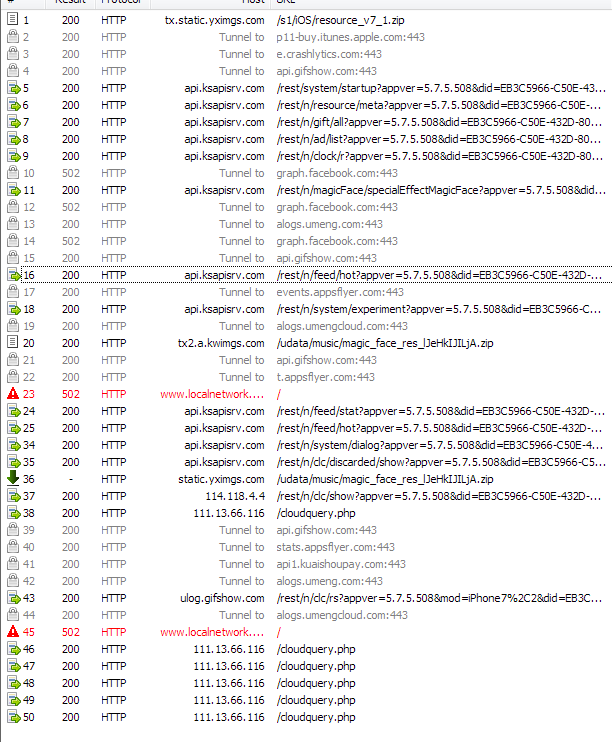
看到请求,去找自己要用的,
非了九牛二虎之力找到了。
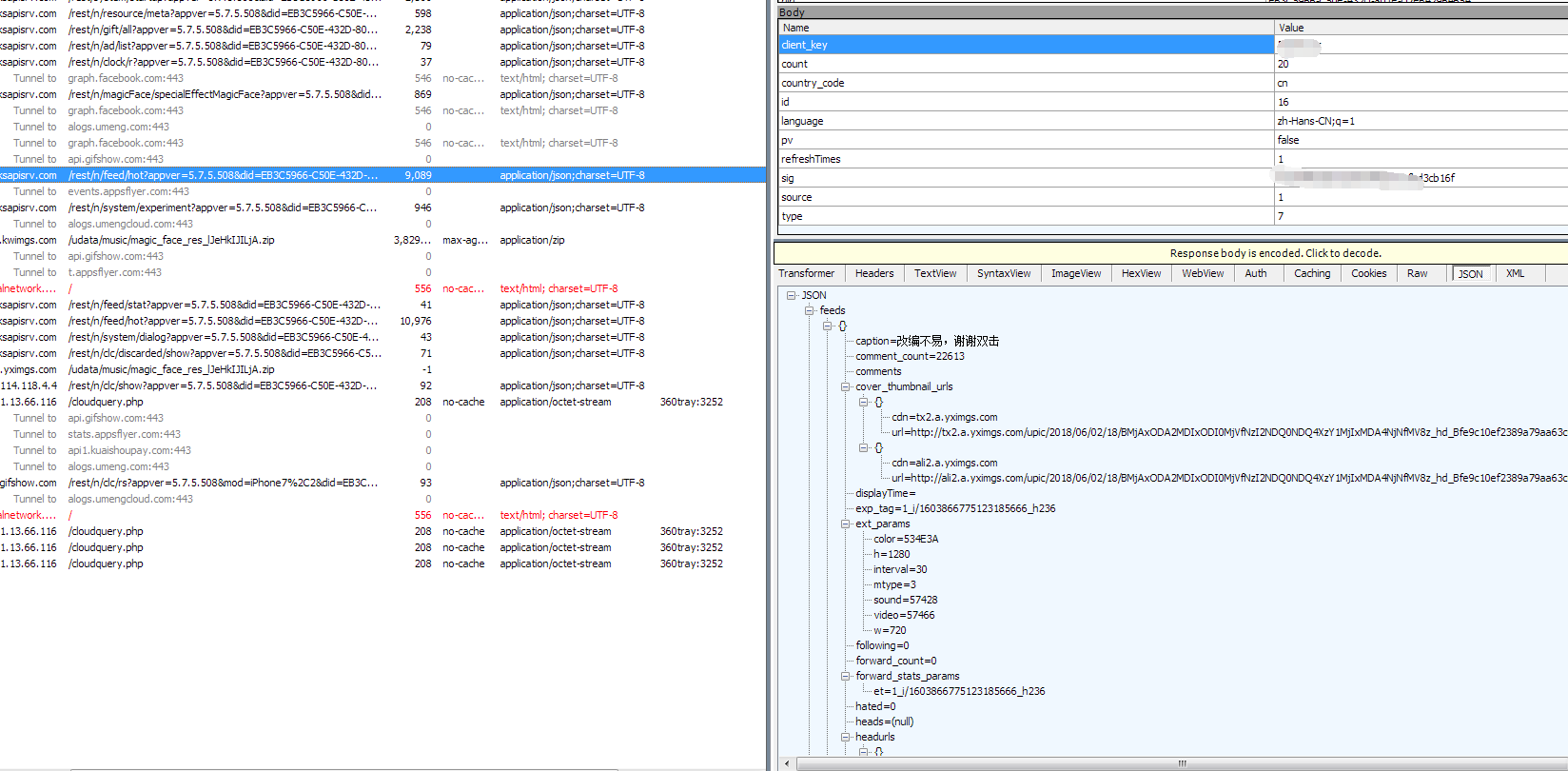
看下需要的参数,创建新的py文件,
吧参数完全复制过来。
1 2 3 4 5 6 7 8 9 10 | client_key 21121count 20country_code cnid 16language zh-Hans-CN;q=1pv falserefreshTimes 1sig 2121source 1type 7 |
然后去写代码

import requests,json url='http://124.243.249.4/rest/n/feed/hot?appver=5.7.5.508&did=EB3C5966-C50E-432D-801E-D7EB42964654&c=a&ver=5.7&sys=ios9.3.5&mod=iPhone7%2C2&net=%E4%B8%AD%E5%9B%BD%E7%A7%BB%E5%8A%A8_5' headers={ 'Content-Type': 'application/x-www-form-urlencoded', 'Host': '124.243.205.129', 'Accept-Language': 'zh-Hans-CN;q=1' } data={ 'client_key':'12', 'coldStart':'true', 'count':'20', 'country_code':'cn', 'id':'5', 'language':'zh-Hans-CN;q=1', 'pv':'false', 'refreshTimes':'0', 'sig': '111', 'source':'1', 'type':'7' } jso=requests.post(url,data=(data),headers=headers) list=jso.json()['feeds'] for i in list: print('描述:%s'%i['caption']) print('视频连接:%s'%i['main_mv_urls'][0]['url']) print('作者:%s'%i['user_name'])print('用户id:%s'%i['user_id'])
打印下我们输出的

打开连接。下载后就可以播放了。

然后这里还可以根据返回的信息去找视频的评论。
仔细去分析,就能爬取到。
热门视频,热门图片等都能爬取到。


 访问量
访问量

【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 如何编写易于单元测试的代码
· 10年+ .NET Coder 心语,封装的思维:从隐藏、稳定开始理解其本质意义
· .NET Core 中如何实现缓存的预热?
· 从 HTTP 原因短语缺失研究 HTTP/2 和 HTTP/3 的设计差异
· AI与.NET技术实操系列:向量存储与相似性搜索在 .NET 中的实现
· 周边上新:园子的第一款马克杯温暖上架
· Open-Sora 2.0 重磅开源!
· 分享 3 个 .NET 开源的文件压缩处理库,助力快速实现文件压缩解压功能!
· Ollama——大语言模型本地部署的极速利器
· DeepSeek如何颠覆传统软件测试?测试工程师会被淘汰吗?