

爬虫笔记
一、bs4和lxml
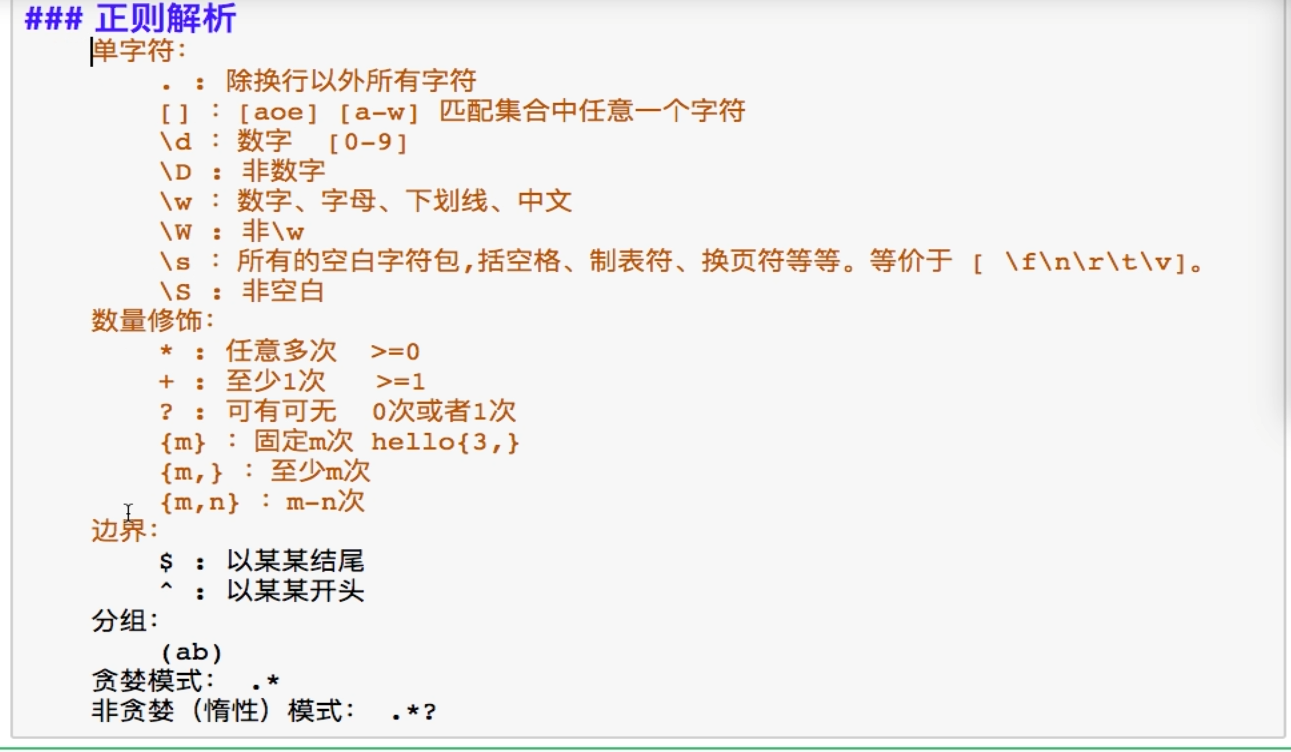
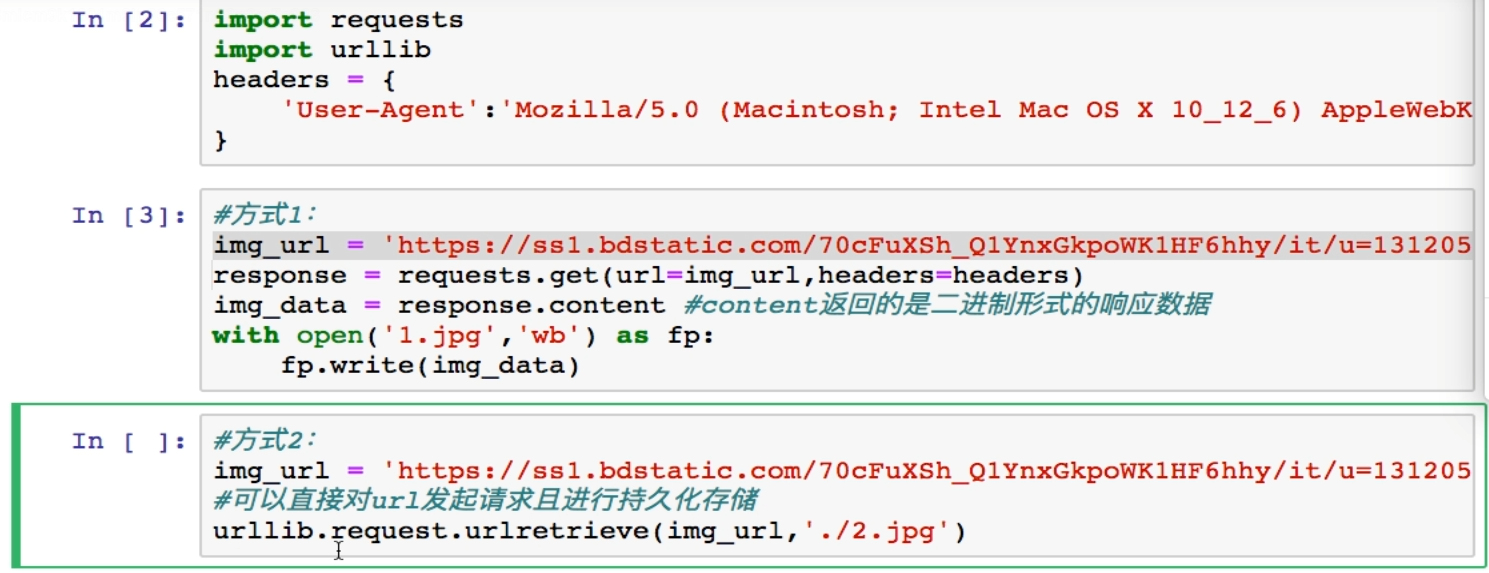


-------------------------------------------------------------------------------------------------------------
二、requests模块高级操作



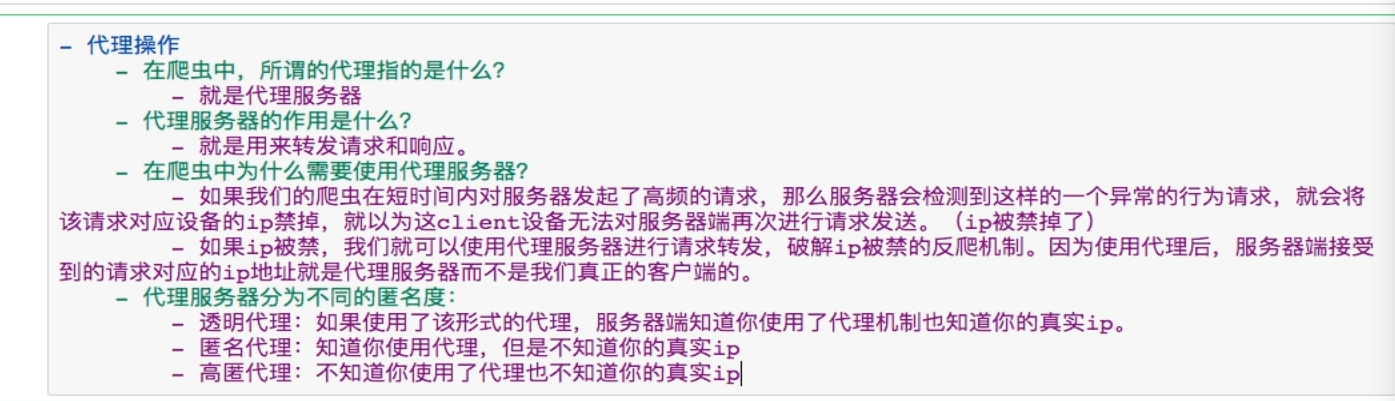
——————注意代理参数格式是{ 'http/https' : " ip:端口 “ }字典
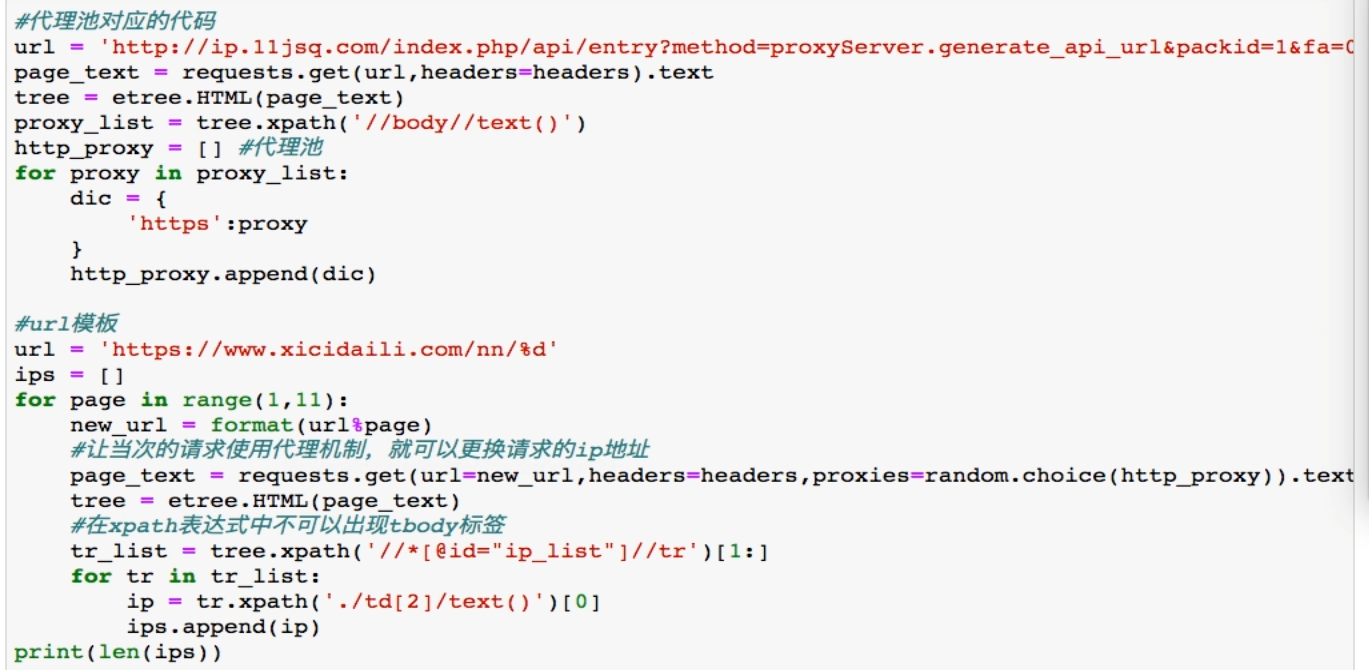

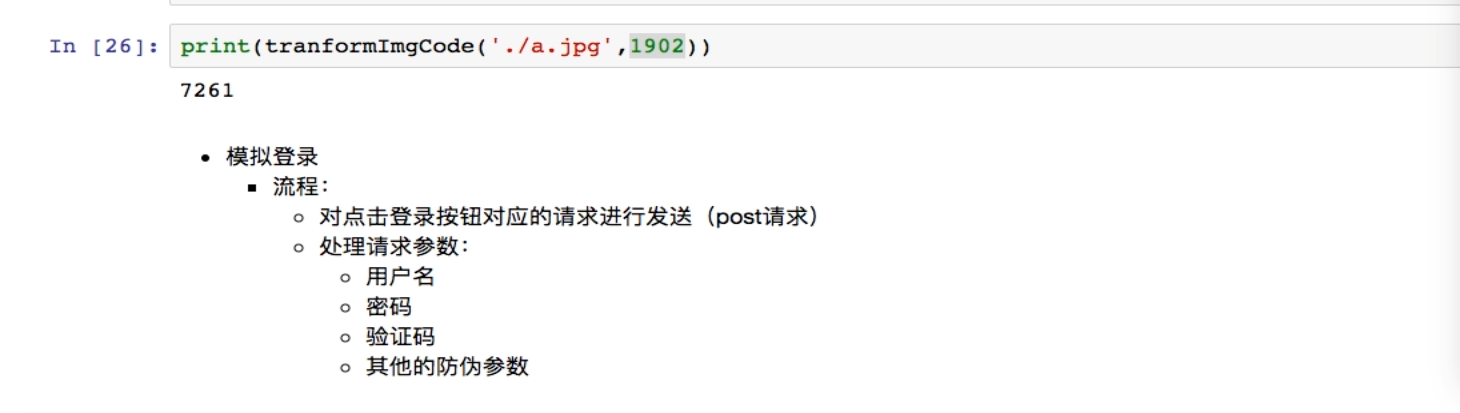
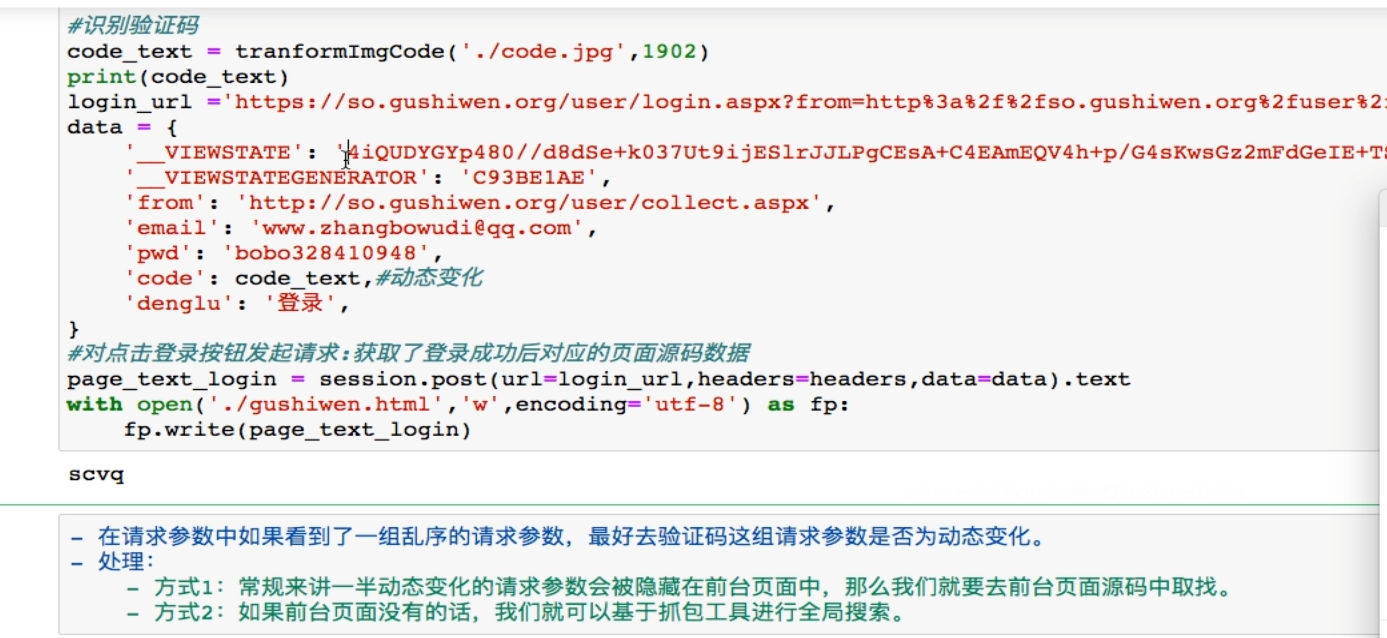
--------------------------------------------------------------
三、异步多任务爬虫(gevent是多协程)
3.1gevent多协程
1 import uuid 2 3 import gevent 4 from gevent import monkey, pool 5 import time, random 6 import urllib.request 7 8 monkey.patch_all() 9 10 jpg_num = 0 11 12 13 def down_load_img(img_uel, img_name): 14 global jpg_num 15 jpg_num += 1 16 print("正在下载第{}张".format(jpg_num)) 17 18 img = urllib.request.urlopen(img_uel) # 设置网络连接 19 img_content = img.read() # 读取网址信息 20 # 设置一个新的文件并将信息写入 21 with open(r"%s" % img_name, "wb") as f1: 22 f1.write(img_content) 23 time.sleep(random.random()) 24 time.sleep(2) 25 26 27 def main(): 28 p = pool.Pool(50) # 创建协程池 29 url = 'https://www.google.com/imgres?imgurl=https%3A%2F%2Fpic2.cwuzx.com%2Fe390d4d07e852ebc2de3bbbbfd08bb31db705194-800.jpg&imgrefurl=https%3A%2F%2Fwww.cwuzx.com%2Fimage%2F24.html&tbnid=VTjovih6x09TsM&vet=12ahUKEwi4n_fHm5nqAhXwzIsBHWacBQ0QMygFegUIARCrAQ..i&docid=HC2ZQVVBJ4T2qM&w=650&h=432&q=%E7%8C%AB%E5%9B%BE%E7%89%87&ved=2ahUKEwi4n_fHm5nqAhXwzIsBHWacBQ0QMygFegUIARCrAQ' 30 ret_list = [url for i in range(0,1000)] 31 32 # 重置列表 33 num = 0 34 my_list = [] 35 36 t_start = time.time() # 设置开始时间 37 for img_url in ret_list: 38 my_list.append(p.spawn(down_load_img, img_url, "%s.jpg" % str(uuid.uuid4()))) 39 if num == 100: # 设置想要的下载文件数量 40 break 41 num += 1 42 43 gevent.joinall(my_list) # 添加任务到协程池 44 t_stop = time.time() # 设置结束时间 45 print("下载文件一共用了:%.2f秒" % (t_stop - t_start)) # 计时 46 47 48 if __name__ == '__main__': 49 main()
3.2 async(参考:https://www.cnblogs.com/yoyoketang/p/16256696.html)
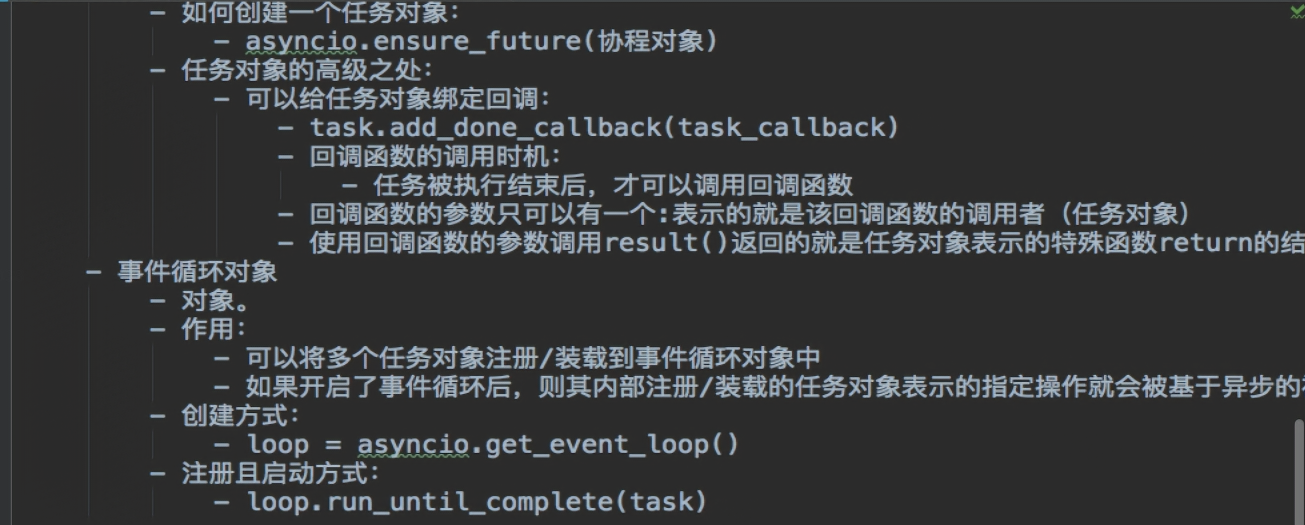

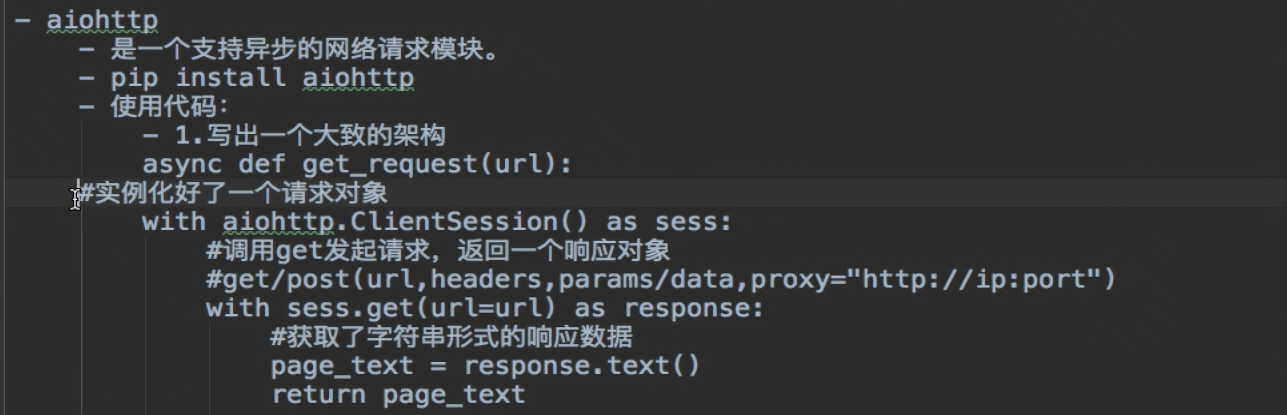
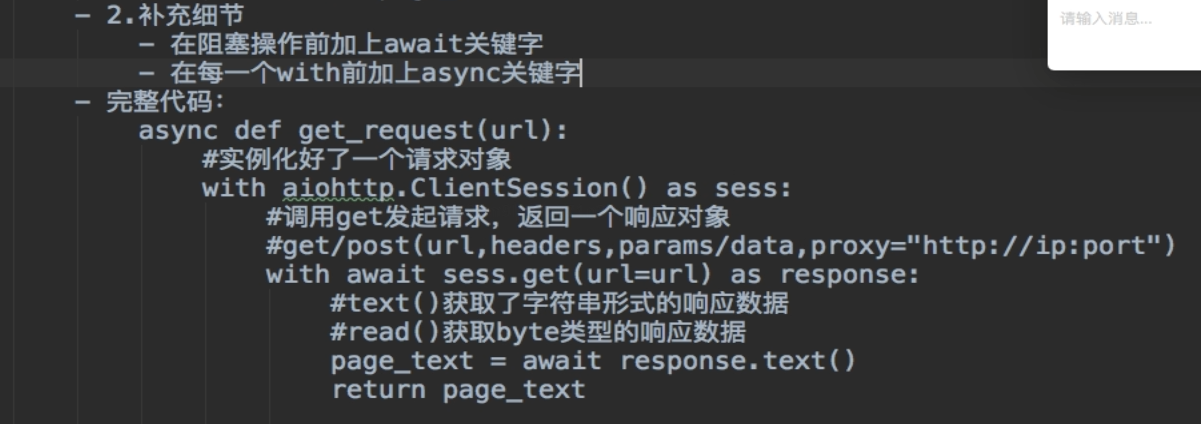

import time import asyncio async def washing1(): await asyncio.sleep(3) # 第一台洗衣机, print('washer1 finished') # 洗完了 async def washing2(): await asyncio.sleep(8) print('washer2 finished') async def washing3(): await asyncio.sleep(5) print('washer3 finished') if __name__ == '__main__': print('start main:') start_time = time.time() # step1 创建一个事件循环 loop = asyncio.get_event_loop() # step2 将异步函数(协程)加入事件队列 tasks = [ washing1(), washing2(), washing3() ] # step3 执行事件队列 直到最晚的一个事件被处理完毕后结束 loop.run_until_complete(asyncio.wait(tasks)) end_time = time.time() print('-----------end main----------') print('总共耗时:{}'.format(end_time-start_time)) async def my_coroutine(task_name, duration): print(f"Task {task_name} started") await asyncio.sleep(duration) print(f"Task {task_name} finished") async def main(): tasks = [] for i in range(3): task = asyncio.create_task(my_coroutine(f"Task-{i}", 2)) tasks.append(task) await asyncio.gather(*tasks) asyncio.run(main())
四、selenium在爬虫的应用
4.1 工作原理
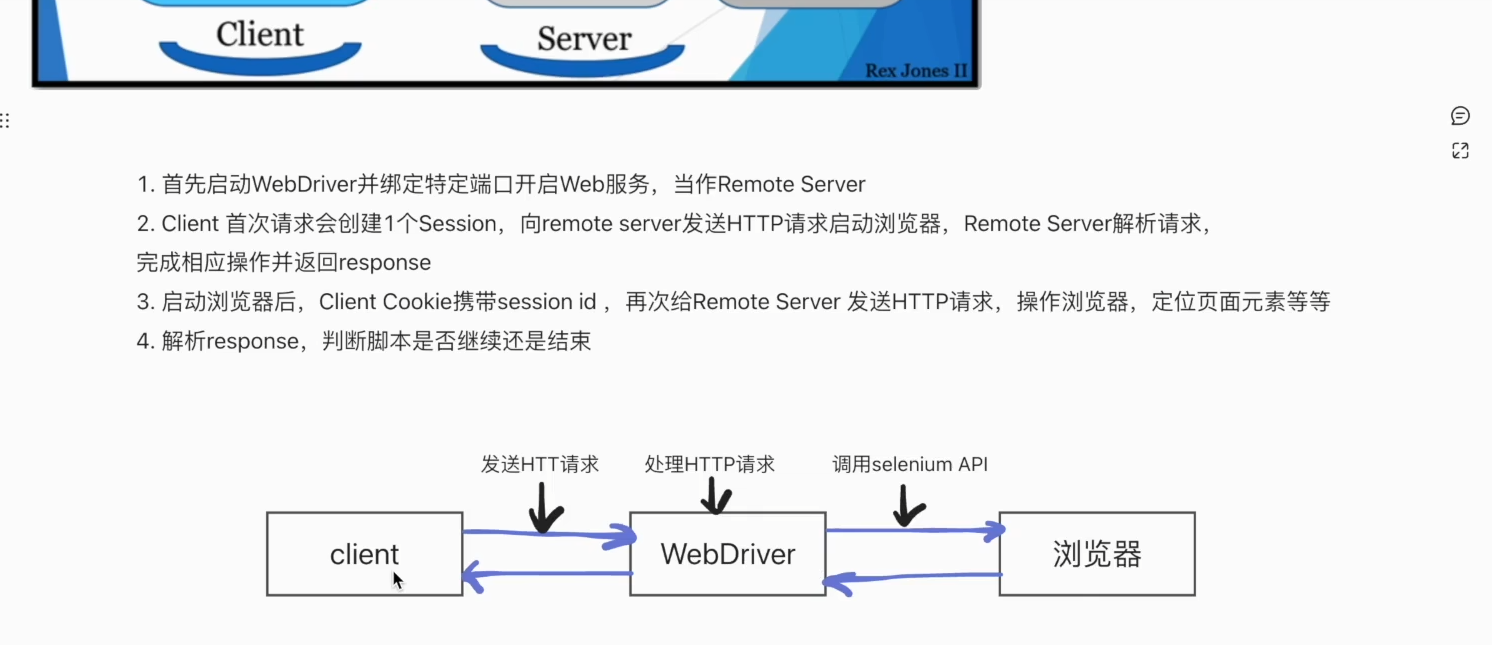
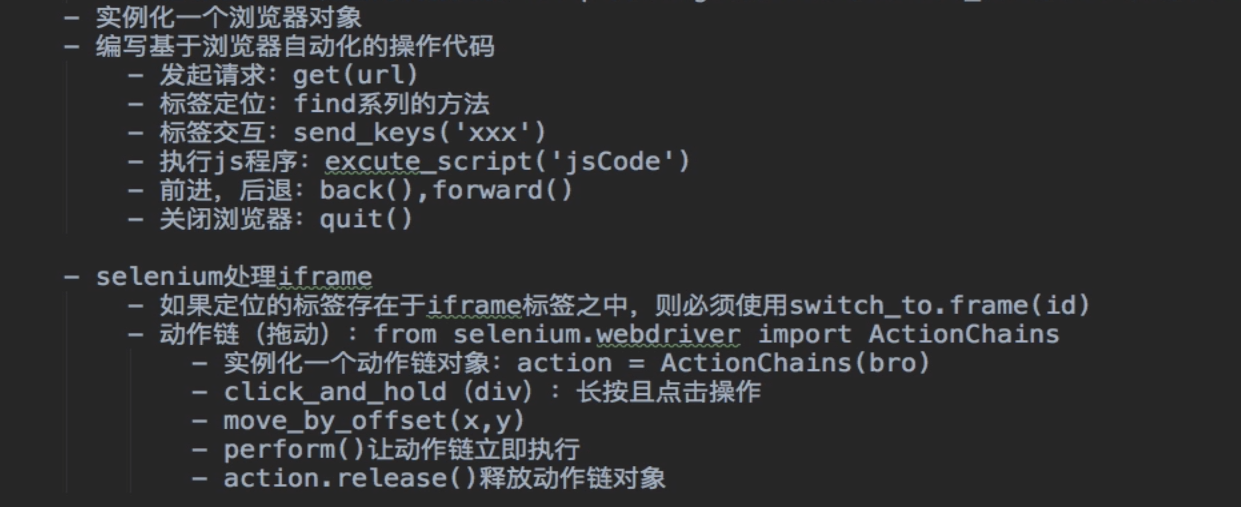
4.2 元素定位

#示例如下 from selenium.webdriver.common.by import By driver.find_element(By.ID,'元素id') driver.find_element(By.name,'元素name') driver.find_element(By.class,'元素class') # 或 driver.find_element('id','元素id') driver.find_element('name','元素name') driver.find_element('class','元素class')
五、玩转scrapy框架的具体应用
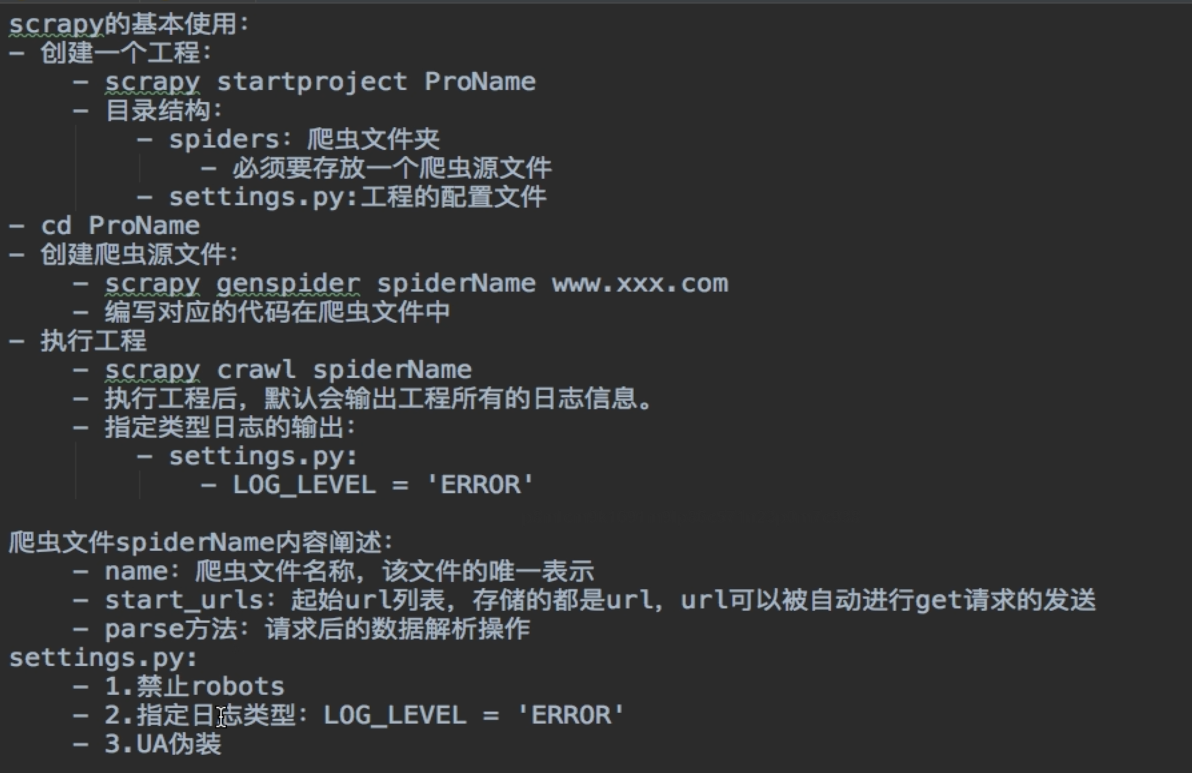
5.1 安装和基本使用(参考)
pip install scrapy
常见问题——————————————点击————————————————
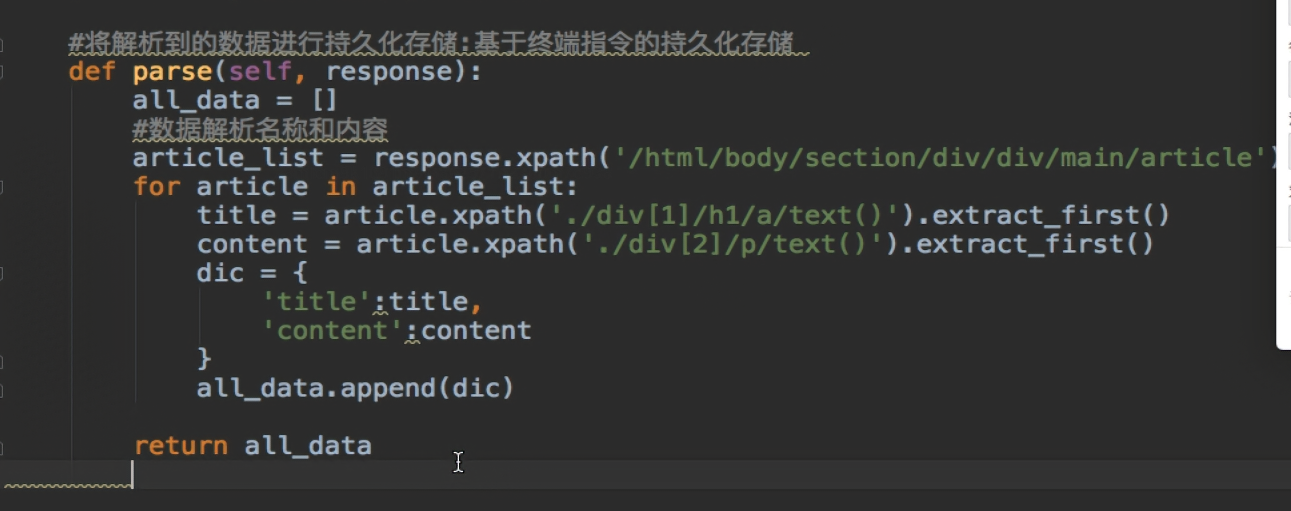
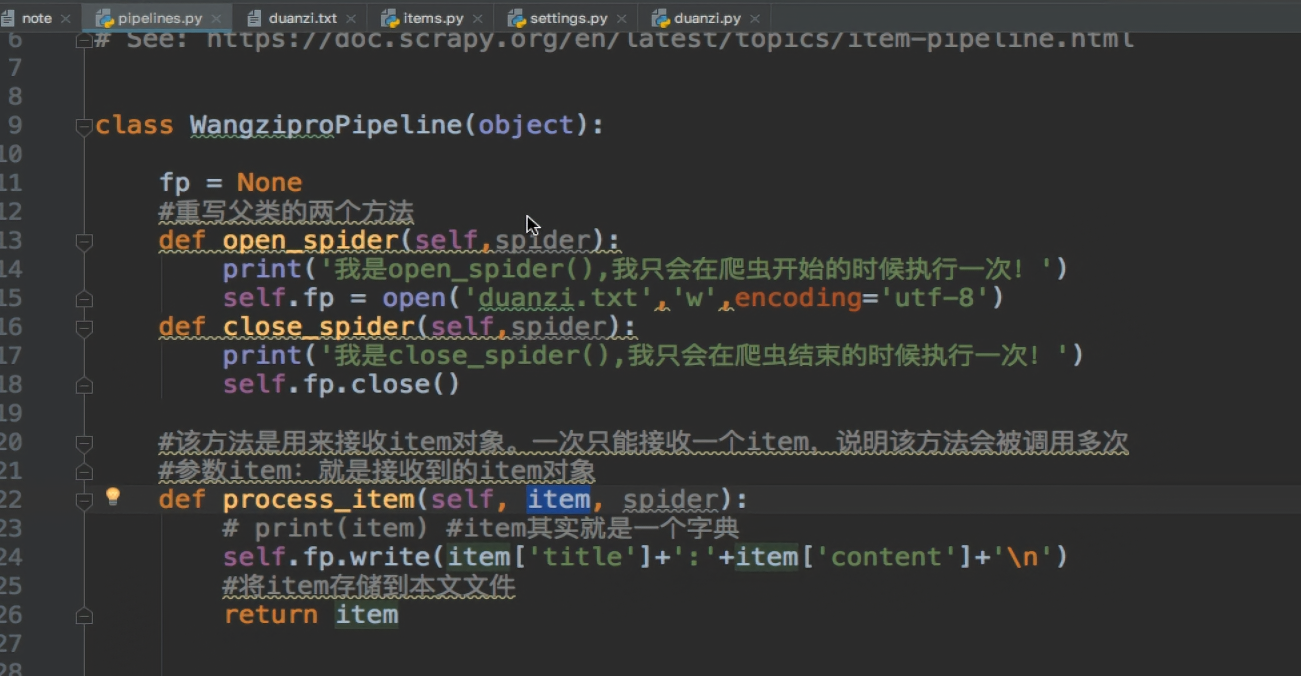
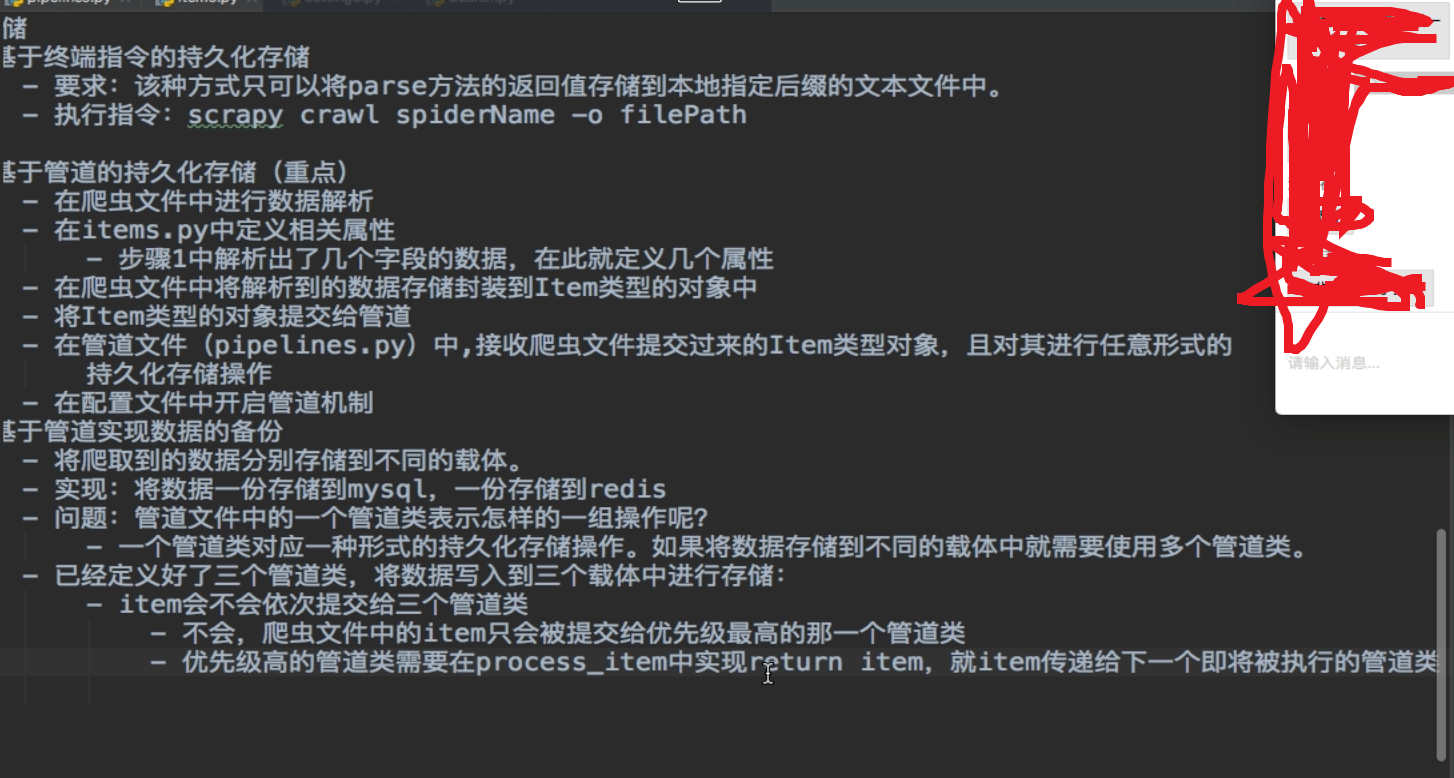
——————————————————————手动请求发送(post and get)----------------------------------------------------------------------
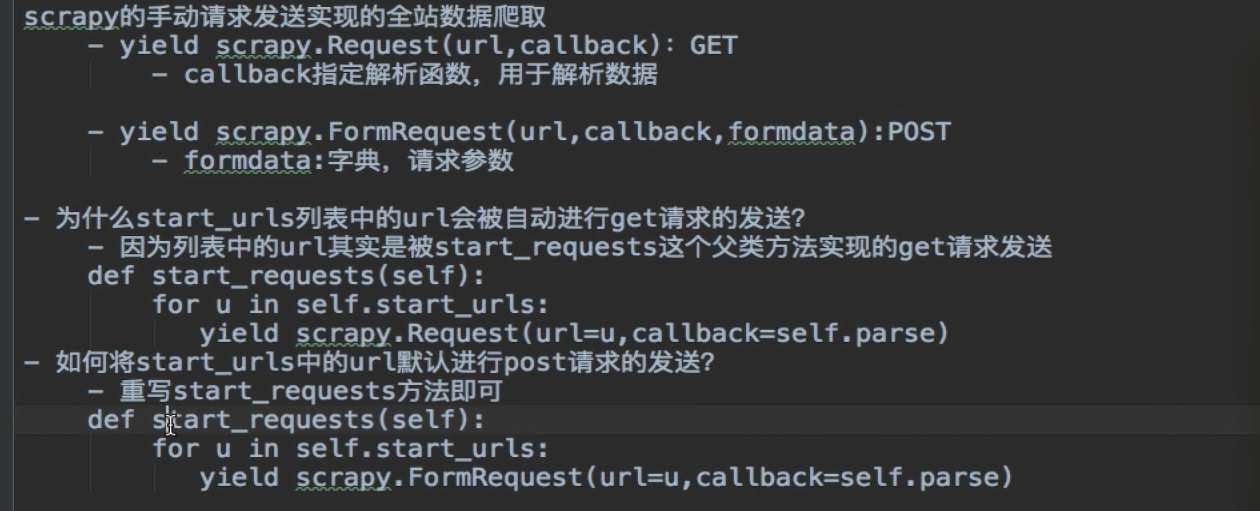
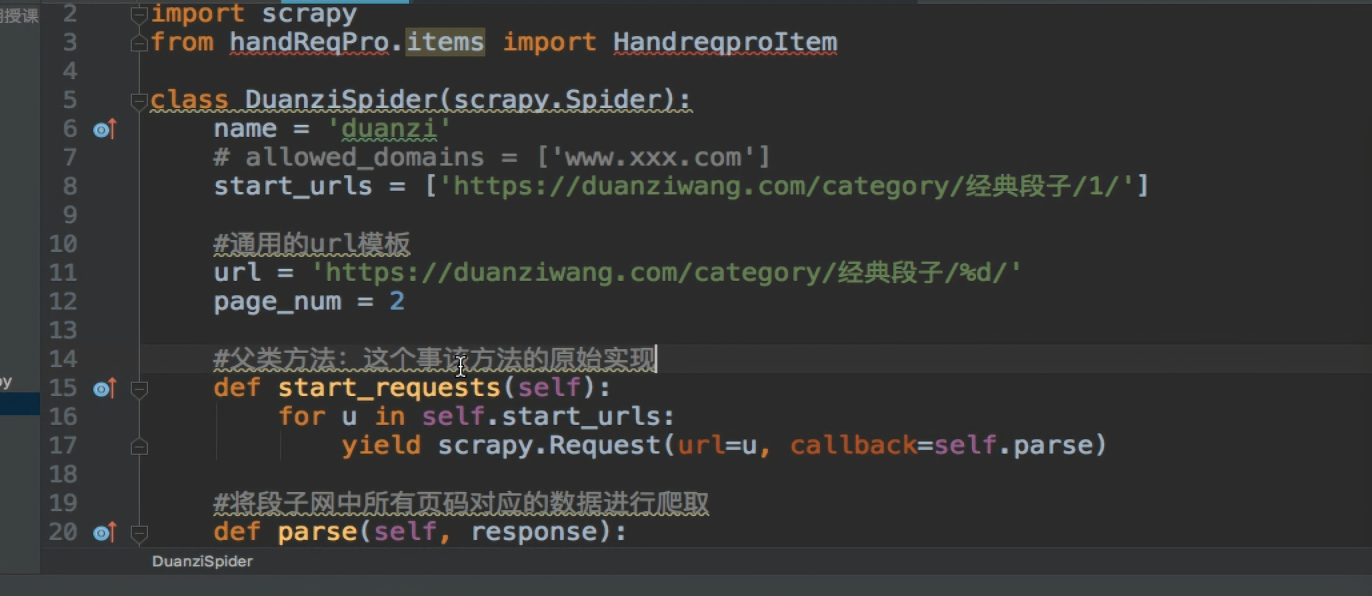
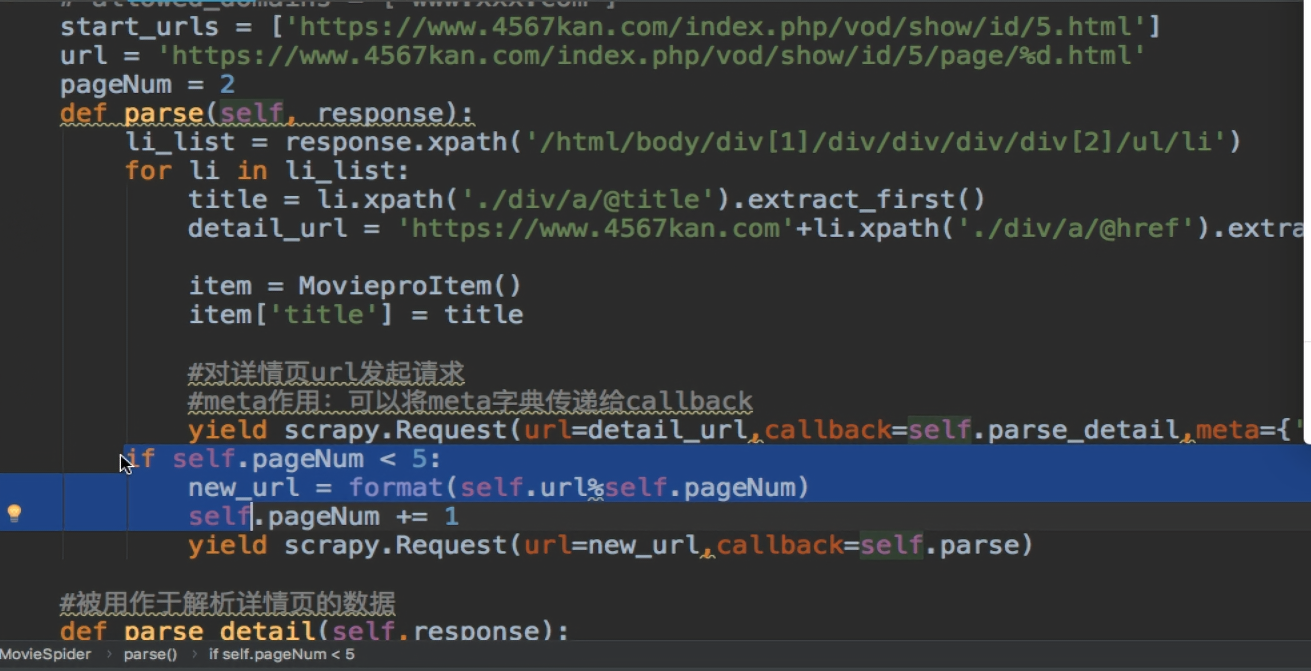
---------------------------------------------------------------请求传参(meta传递item)-------------------------------------------
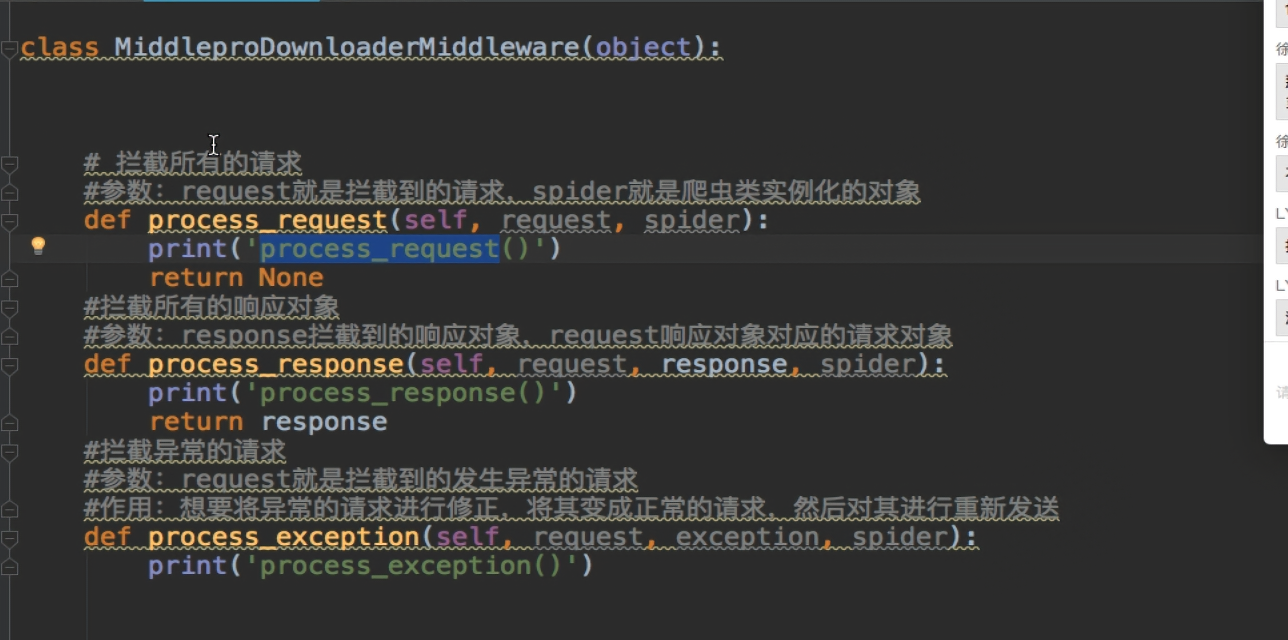
---------------------------------下载中间件-------------------------
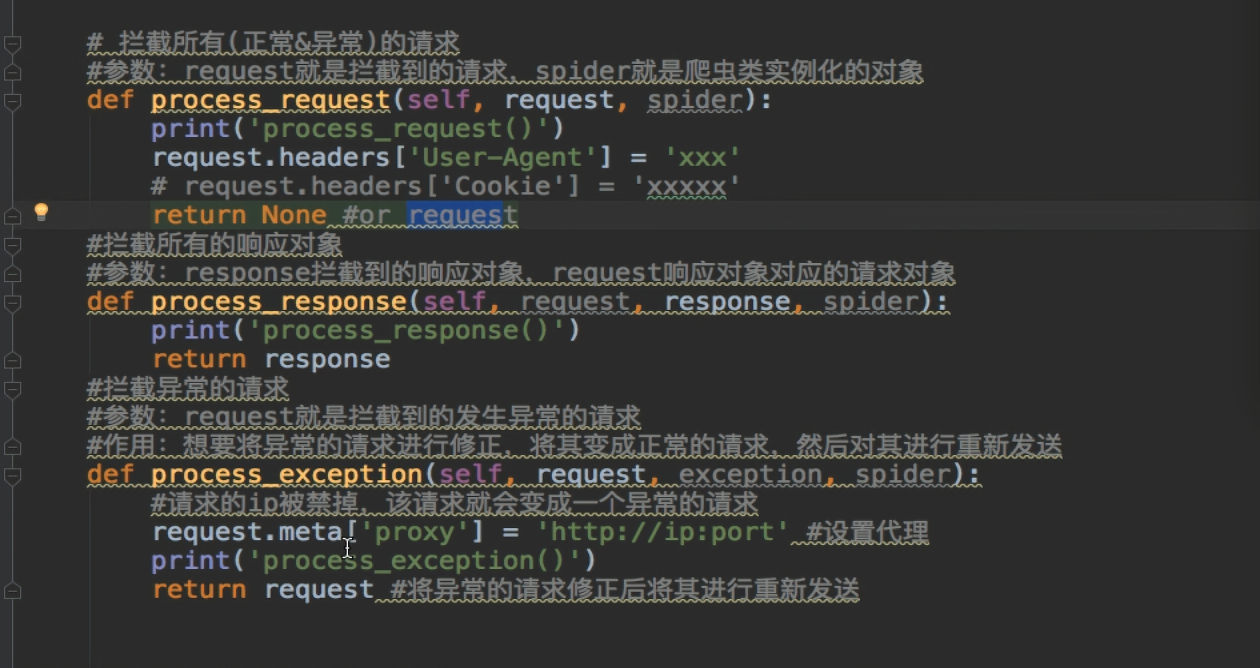
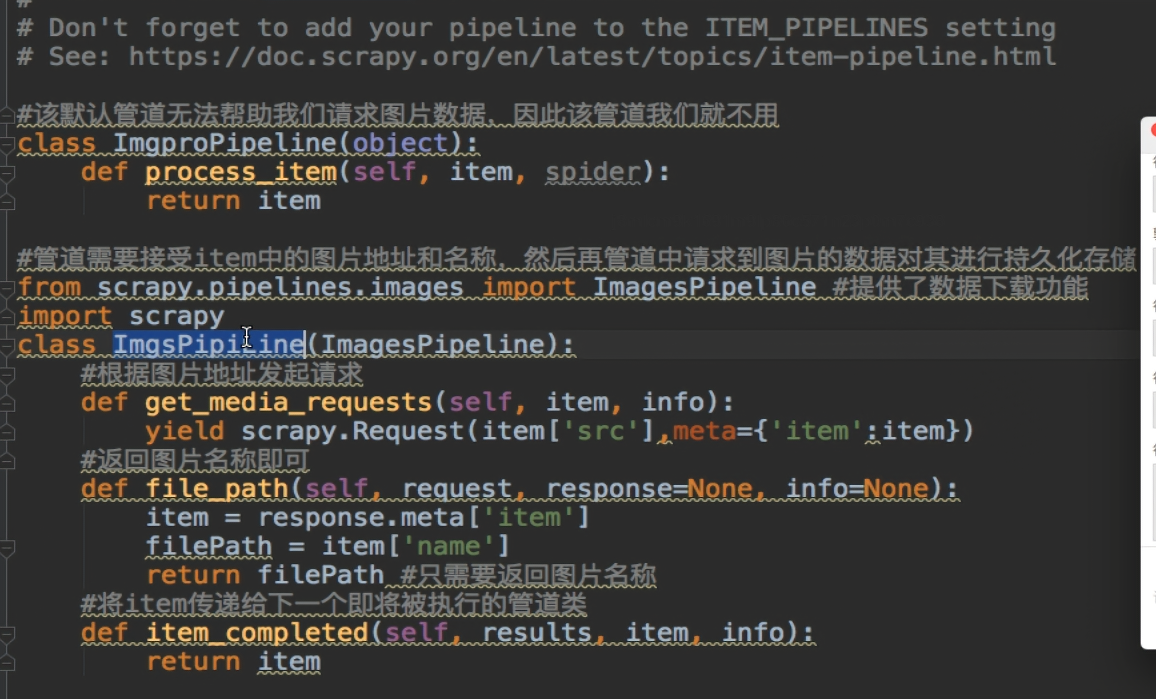
---------------------------深度爬取-------------------------

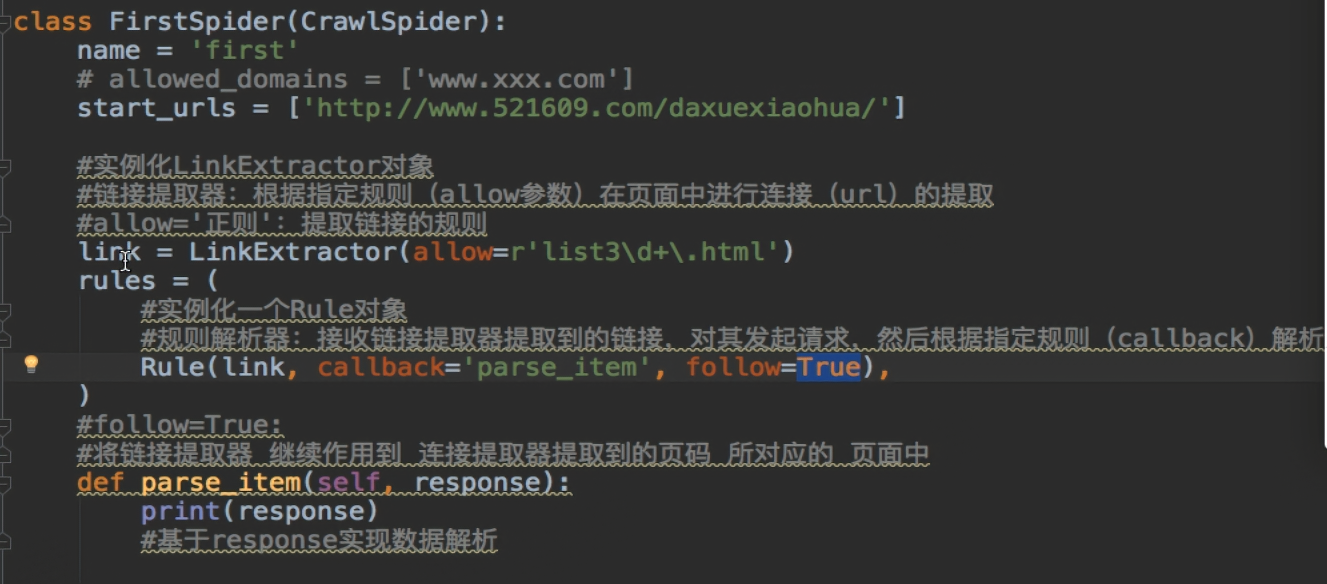
CrawlSpider实现的深度爬取
- 通用方式:CrawlSpider+Spider实现
selenium在scrapy中的使用
- https://news.163.com/
- 爬取网易新闻中的国内,国际,军事,航空,无人机这五个板块下所有的新闻数据(标题+内容)
- 分析
- 首页没有动态加载的数据
- 爬取五个板块对应的url
- 每一个板块对应的页面中的新闻标题是动态加载
- 爬取新闻标题+详情页的url(***)
- 每一条新闻详情页面中的数据不是动态加载
- 爬取的新闻内容
- selenium在scrapy中的使用流程
- 1.在爬虫类中实例化一个浏览器对象,将其作为爬虫类的一个属性
- 2.在中间件中实现浏览器自动化相关的操作
- 3.在爬虫类中重写closed(self,spider),在其内部关闭浏览器对象
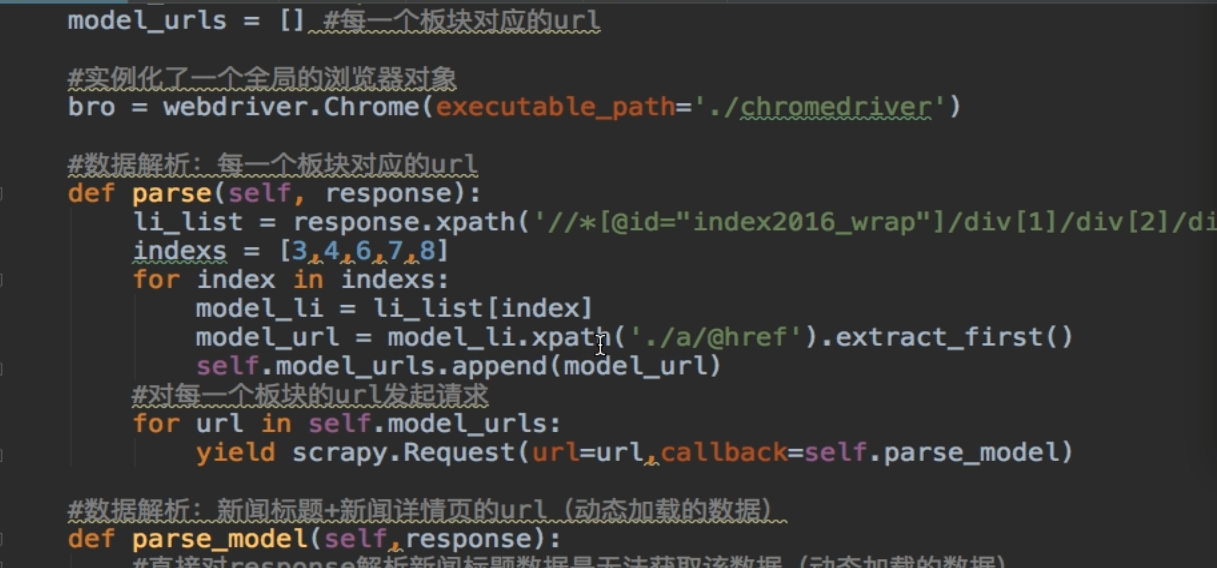
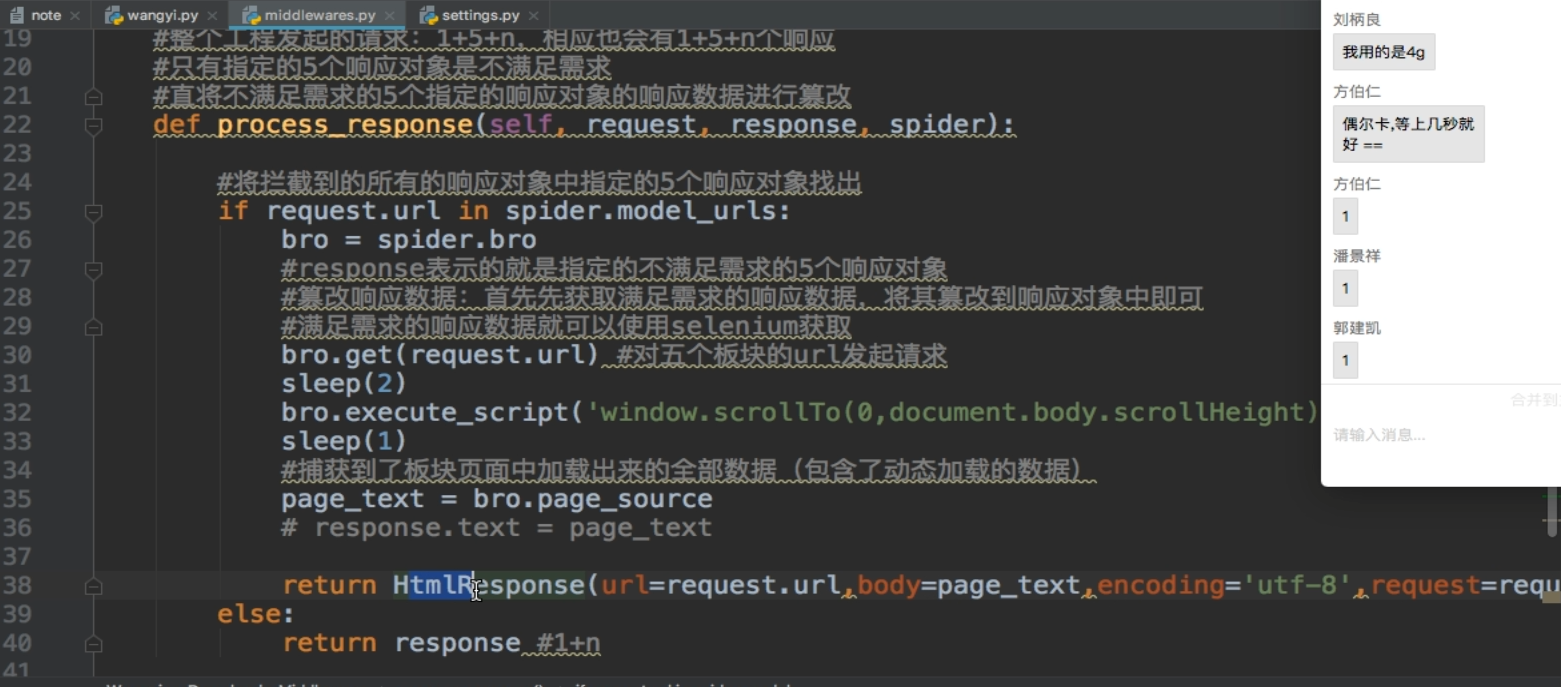
-------------------------------------分布式爬虫----------------------------
分布式
- 实现方式:scrapy+redis(scrapy结合着scrapy-redis组件)
- 原生的scrapy框架是无法实现分布式
- 什么是是分布式
- 需要搭建一个分布式的机群,让后让机群中的每一台电脑执行同一组程序,让其对同一组资源
进行联合且分布的数据爬取。
- 为什么原生的scrapy框架无法实现分布式?
- 调度器无法被分布式机群共享
- 管道无法分布式机群被共享
- 如何实现分布式:使用scrapy-redis组件即可
- scrapy-redis组件的作用:
- 可以给原生的scrapy框架提供共享的管道和调度器
- pip install scrapy-redis
- 实现流程
1.修改爬虫文件
- 1.1 导包:from scrapy_redis.spiders import RedisCrawlSpider
- 1.2 修改当前爬虫类的父类为:RedisCrawlSpider
- 1.3 将start_url替换成redis_keys的属性,属性值为任意字符串
- redis_key = 'xxx':表示的是可以被共享的调度器队列的名称,最终是需要将起始的url手动
放置到redis_key表示的队列中
- 1.4 将数据解析的补充完整即可
2.对settings.py进行配置
- 指定调度器
# 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据
SCHEDULER_PERSIST = True
- 指定管道
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
}
- 特点:该种管道只可以将item写入redis
- 指定redis
REDIS_HOST = 'redis服务的ip地址'
REDIS_PORT = 6379
3.配置redis的配置文件(redis.window.conf)
- 解除默认绑定
- 56行:#bind 127.0.0.1
- 关闭保护模式
- 75行:protected-mode no
4.启动redis服务和客户端
5.执行scrapy工程(不要在配置文件中加入LOG_LEVEL)
- 程序会停留在listening位置:等待起始的url加入
6.向redis_key表示的队列中添加起始url
- 需要在redis的客户端执行如下指令:(调度器队列是存在于redis中)
- lpush sunQueue http://wz.sun0769.com/political/index/politicsNewest?id=1&page=1
具体详情:https://www.cnblogs.com/Liu928011/p/14999692.html
增量式
- 概念:监测网站数据更新的情况,以便于爬取到最新更新出来的数据。
- 实现核心:去重
- 实战中去重的方式:记录表
- 记录表需要记录什么?记录的一定是爬取过的相关信息。
- 爬取过的相关信息:每一部电影详情页的url
- 只需要使用某一组数据,该组数据如果可以作为该部电影的唯一标识即可,刚好电影详情页的url
就可以作为电影的唯一标识。只要可以表示电影唯一标识的数据我们统称为数据指纹。
- 去重的方式对应的记录表:
- python中的set集合(不可以)
- set集合无法持久化存储
- redis中的set可以的
- 可以持久化存储
- 数据指纹一般是经过加密
- 当前案例的数据指纹没有必要加密。
- 什么情况数据指纹需要加密?
- 如果数据的唯一标识标识的内容数据量比较大,可以使用hash将数据加密成32位的密文。
- 目的是为了节省空间。

