

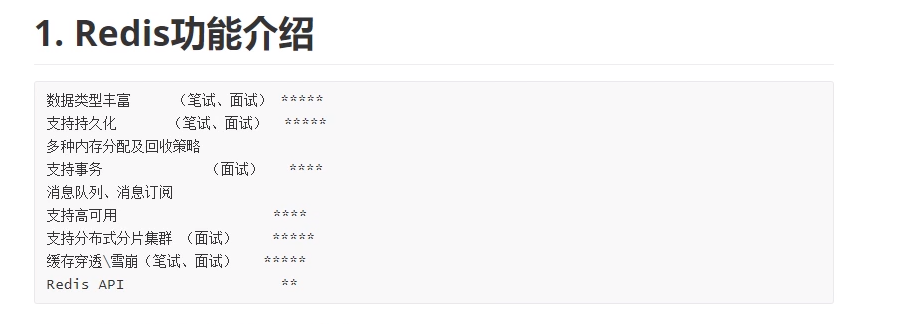
redis笔记
-----cpu调优------------

---------------内存碎片清理-------------------

------------------------------------------------redis优化总结建议------------(转载参考)---------
1.使用复杂度过高的命令
# 命令执行耗时超过 5 毫秒,记录慢日志 CONFIG SET slowlog-log-slower-than 5000 # 只保留最近 500 条慢日志 CONFIG SET slowlog-max-len 500
1)经常使用 O(N) 以上复杂度的命令,例如 SORT、SUNION、ZUNIONSTORE 聚合类命令。
2)使用 O(N) 复杂度的命令,但 N 的值非常大。
第一种情况导致变慢的原因在于,Redis 在操作内存数据时,时间复杂度过高,要花费更多的 CPU 资源。
第二种情况导致变慢的原因在于,Redis 一次需要返回给客户端的数据过多,更多时间花费在数据协议的组装和网络传输过程中。
另外,我们还可以从资源使用率层面来分析,如果你的应用程序操作 Redis 的 OPS 不是很大,但 Redis 实例的 CPU 使用率却很高,那么很有可能是使用了复杂度过高的命令导致的。
1.1慢查询优化
1)尽量不使用 O(N) 以上复杂度过高的命令,对于数据的聚合操作,放在客户端做。
2)执行 O(N) 命令,保证 N 尽量的小(推荐 N <= 300),每次获取尽量少的数据,让 Redis 可以及时处理返回。
2.操作bigkey(大的key)
如果你查询慢日志发现,并不是复杂度过高的命令导致的,而都是 SET / DEL 这种简单命令出现在慢日志中,那么你就要怀疑你的实例否写入了 bigkey。
redis-cli -h 127.0.0.1 -p 6379 --bigkeys -i 1 #i为采样的频率 -------- summary ------- Sampled 829675 keys in the keyspace! Total key length in bytes is 10059825 (avg len 12.13) Biggest string found 'key:291880' has 10 bytes Biggest list found 'mylist:004' has 40 items Biggest set found 'myset:2386' has 38 members Biggest hash found 'myhash:3574' has 37 fields Biggest zset found 'myzset:2704' has 42 members 36313 strings with 363130 bytes (04.38% of keys, avg size 10.00) 787393 lists with 896540 items (94.90% of keys, avg size 1.14) 1994 sets with 40052 members (00.24% of keys, avg size 20.09) 1990 hashs with 39632 fields (00.24% of keys, avg size 19.92) 1985 zsets with 39750 members (00.24% of keys, avg size 20.03)
这里我需要提醒你的是,当执行这个命令时,要注意 2 个问题:
1)对线上实例进行 bigkey 扫描时,Redis 的 OPS 会突增,为了降低扫描过程中对 Redis 的影响,最好控制一下扫描的频率,指定 -i 参数即可,它表示扫描过程中每次扫描后休息的时间间隔,单位是秒。
2)扫描结果中,对于容器类型(List、Hash、Set、ZSet)的 key,只能扫描出元素最多的 key。但一个 key 的元素多,不一定表示占用内存也多,你还需要根据业务情况,进一步评估内存占用情况。
3.集中过期优化
一般有两种方案来规避这个问题:
1.集中过期 key 增加一个随机过期时间,把集中过期的时间打散,降低 Redis 清理过期 key 的压力
2.如果你使用的 Redis 是 4.0 以上版本,可以开启 lazy-free 机制,当删除过期 key 时,把释放内存的操作放到后台线程中执行,避免阻塞主线程。
第一种方案,在设置 key 的过期时间时,增加一个随机时间,伪代码可以这么写:
# 在过期时间点之后的 5 分钟内随机过期掉 redis.expireat(key, expire_time + random(300))
第二种方案,Redis 4.0 以上版本,开启 lazy-free 机制:
# 释放过期 key 的内存,放到后台线程执行 lazyfree-lazy-expire yes
运维层面,你需要把 Redis 的各项运行状态数据监控起来,在 Redis 上执行 INFO 命令就可以拿到这个实例所有的运行状态数据。
在这里我们需要重点关注 expired_keys 这一项,它代表整个实例到目前为止,累计删除过期 key 的数量。
你需要把这个指标监控起来,当这个指标在很短时间内出现了突增,需要及时报警出来,然后与业务应用报慢的时间点进行对比分析,确认时间是否一致,如果一致,则可以确认确实是因为集中过期 key 导致的延迟变大。
4.实例内存达到上限优化
当我们把 Redis 当做纯缓存使用时,通常会给这个实例设置一个内存上限 maxmemory,然后设置一个数据淘汰策略。
当 Redis 内存达到 maxmemory 后,每次写入新的数据之前,Redis 必须先从实例中踢出一部分数据,让整个实例的内存维持在 maxmemory 之下,然后才能把新数据写进来。
这个踢出旧数据的逻辑也是需要消耗时间的,而具体耗时的长短,要取决于你配置的淘汰策略:
-
allkeys-lru:不管 key 是否设置了过期,淘汰最近最少访问的 key
-
volatile-lru:只淘汰最近最少访问、并设置了过期时间的 key
-
allkeys-random:不管 key 是否设置了过期,随机淘汰 key
-
volatile-random:只随机淘汰设置了过期时间的 key
-
allkeys-ttl:不管 key 是否设置了过期,淘汰即将过期的 key
-
noeviction:不淘汰任何 key,实例内存达到 maxmeory 后,再写入新数据直接返回错误
-
allkeys-lfu:不管 key 是否设置了过期,淘汰访问频率最低的 key(4.0+版本支持)
-
volatile-lfu:只淘汰访问频率最低、并设置了过期时间 key(4.0+版本支持)
一般最常使用的是 allkeys-lru / volatile-lru 淘汰策略,它们的处理逻辑是,每次从实例中随机取出一批 key(这个数量可配置),然后淘汰一个最少访问的 key,之后把剩下的 key 暂存到一个池子中,继续随机取一批 key,并与之前池子中的 key 比较,再淘汰一个最少访问的 key。以此往复,直到实例内存降到 maxmemory 之下。
需要注意的是,Redis 的淘汰数据的逻辑与删除过期 key 的一样,也是在命令真正执行之前执行的,也就是说它也会增加我们操作 Redis 的延迟,而且,写 OPS 越高,延迟也会越明显。
1)避免存储 bigkey,降低释放内存的耗时
2)淘汰策略改为随机淘汰,随机淘汰比 LRU 要快很多(视业务情况调整)
3)拆分实例,把淘汰 key 的压力分摊到多个实例上
4)如果使用的是 Redis 4.0 以上版本,开启 layz-free 机制,把淘汰 key 释放内存的操作放到后台线程中执行(配置 lazyfree-lazy-eviction = yes)
5.fork耗时严重优化
5.1 fork耗时严重
当 Redis 开启了后台 RDB 和 AOF rewrite 后,在执行时,它们都需要主进程创建出一个子进程进行数据的持久化。
主进程创建子进程,会调用操作系统提供的 fork 函数。
而 fork 在执行过程中,主进程需要拷贝自己的内存页表给子进程,如果这个实例很大,那么这个拷贝的过程也会比较耗时。
而且这个 fork 过程会消耗大量的 CPU 资源,在完成 fork 之前,整个 Redis 实例会被阻塞住,无法处理任何客户端请求。
如果此时你的 CPU 资源本来就很紧张,那么 fork 的耗时会更长,甚至达到秒级,这会严重影响 Redis 的性能。
那如何确认确实是因为 fork 耗时导致的 Redis 延迟变大呢?
你可以在 Redis 上执行 INFO 命令,查看 latest_fork_usec 项,单位微秒。
# 上一次 fork 耗时,单位微秒 latest_fork_usec:59477
这个时间就是主进程在 fork 子进程期间,整个实例阻塞无法处理客户端请求的时间。
如果你发现这个耗时很久,就要警惕起来了,这意味在这期间,你的整个 Redis 实例都处于不可用的状态。
除了数据持久化会生成 RDB 之外,当主从节点第一次建立数据同步时,主节点也创建子进程生成 RDB,然后发给从节点进行一次全量同步,所以,这个过程也会对 Redis 产生性能影响。

5.2 优化
1)控制 Redis 实例的内存:尽量在 10G 以下,执行 fork 的耗时与实例大小有关,实例越大,耗时越久。
2)合理配置数据持久化策略:在 slave 节点执行 RDB 备份,推荐在低峰期执行,而对于丢失数据不敏感的业务(例如把 Redis 当做纯缓存使用),可以关闭 AOF 和 AOF rewrite。
3)Redis 实例不要部署在虚拟机上:fork 的耗时也与系统也有关,虚拟机比物理机耗时更久。
4)降低主从库全量同步的概率:适当调大 repl-backlog-size(复制缓冲区) 参数,避免主从全量同步。
从建立同步时,优先检测是否可以尝试只同步部分数据,这种情况就是针对于之前已经建立好了复制链路,只是因为故障导致临时断开,故障恢复后重新建立同步时,为了避免全量同步的资源消耗,Redis会优先尝试部分数据同步,如果条件不符合,才会触发全量同步。
这个判断依据就是在master上维护的复制缓冲区大小,如果这个缓冲区配置的过小,很有可能在主从断开复制的这段时间内,master产生的写入导致复制缓冲区的数据被覆盖,重新建立同步时的slave需要同步的offset位置在master的缓冲区中找不到,那么此时就会触发全量同步。
如何避免这种情况?解决方案就是适当调大复制缓冲区repl-backlog-size的大小,这个缓冲区的大小默认为1MB,如果实例写入量比较大,可以针对性调大此配置。
6.查看Redis内存是否发生Swap
$ redis-cli info | grep process_id process_id: 5332
然后,进入 Redis 所在机器的 /proc 目录下的该进程目录中,最后,运行下面的命令,查看该 Redis 进程的使用情况。在这儿,我只截取了部分结果:
$ cd /proc/5332 $cat smaps | egrep '^(Swap|Size)' Size: 584 kB Swap: 0 kB Size: 4 kB Swap: 4 kB Size: 4 kB Swap: 0 kB Size: 462044 kB Swap: 462008 kB Size: 21392 kB Swap: 0 kB
一旦发生内存 swap,最直接的解决方法就是增加机器内存。如果该实例在一个 Redis 切片集群中,可以增加 Redis 集群的实例个数,来分摊每个实例服务的数据量,进而减少每个实例所需的内存量。
7.内存大页
如果采用了内存大页,那么,即使客户端请求只修改 100B 的数据,Redis 也需要拷贝 2MB 的大页。相反,如果是常规内存页机制,只用拷贝 4KB。两者相比,你可以看到,当客户端请求修改或新写入数据较多时,内存大页机制将导致大量的拷贝,这就会影响 Redis 正常的访存操作,最终导致性能变慢。
首先,我们要先排查下内存大页。方法是:在 Redis 实例运行的机器上执行如下命令:
$ cat /sys/kernel/mm/transparent_hugepage/enabled [always] madvise never
如果执行结果是 always,就表明内存大页机制被启动了;如果是 never,就表示,内存大页机制被禁止。
在实际生产环境中部署时,我建议你不要使用内存大页机制,操作也很简单,只需要执行下面的命令就可以了:
echo never /sys/kernel/mm/transparent_hugepage/enabled
其实,操作系统提供的内存大页机制,其优势是,可以在一定程序上降低应用程序申请内存的次数。
但是对于 Redis 这种对性能和延迟极其敏感的数据库来说,我们希望 Redis 在每次申请内存时,耗时尽量短,所以我不建议你在 Redis 机器上开启这个机制。
8.删除使用Lazy Free
支持版本:Redis 4.0+
1)主动删除键使用lazy free
-
UNLINK命令
127.0.0.1:7000> LLEN mylist
(integer) 2000000
127.0.0.1:7000> UNLINK mylist
(integer) 1
127.0.0.1:7000> SLOWLOG get
1) 1) (integer) 1
2) (integer) 1505465188
3) (integer) 30
4) 1) "UNLINK"
2) "mylist"
5) "127.0.0.1:17015"
6) ""
注意:DEL命令,还是并发阻塞的删除操作
-
FLUSHALL/FLUSHDB ASYNC
127.0.0.1:7000> DBSIZE
(integer) 1812295
127.0.0.1:7000> flushall //同步清理实例数据,180万个key耗时1020毫秒
OK
(1.02s)
127.0.0.1:7000> DBSIZE
(integer) 1812637
127.0.0.1:7000> flushall async //异步清理实例数据,180万个key耗时约9毫秒
OK
127.0.0.1:7000> SLOWLOG get
1) 1) (integer) 2996109
2) (integer) 1505465989
3) (integer) 9274 //指令运行耗时9.2毫秒
4) 1) "flushall"
2) "async"
5) "127.0.0.1:20110"
6) ""
2)被动删除键使用lazy free
lazy free应用于被动删除中,目前有4种场景,每种场景对应一个配置参数;默认都是关闭。
lazyfree-lazy-eviction no lazyfree-lazy-expire no lazyfree-lazy-server-del no slave-lazy-flush no
-
lazyfree-lazy-eviction
针对redis内存使用达到maxmeory,并设置有淘汰策略时;在被动淘汰键时,是否采用lazy free机制;因为此场景开启lazy free, 可能使用淘汰键的内存释放不及时,导致redis内存超用,超过maxmemory的限制。此场景使用时,请结合业务测试。(生产环境不建议设置yes)
-
lazyfree-lazy-expire
针对设置有TTL的键,达到过期后,被redis清理删除时是否采用lazy free机制;此场景建议开启,因TTL本身是自适应调整的速度。
-
lazyfree-lazy-server-del
针对有些指令在处理已存在的键时,会带有一个隐式的DEL键的操作。如rename命令,当目标键已存在,redis会先删除目标键,如果这些目标键是一个big key,那就会引入阻塞删除的性能问题。此参数设置就是解决这类问题,建议可开启。
-
slave-lazy-flush
针对slave进行全量数据同步,slave在加载master的RDB文件前,会运行flushall来清理自己的数据场景, 参数设置决定是否采用异常flush机制。如果内存变动不大,建议可开启。可减少全量同步耗时,从而减少主库因输出缓冲区爆涨引起的内存使用增长。
3)lazy free的监控
lazy free能监控的数据指标,只有一个值:lazyfree_pending_objects,表示redis执行lazy free操作,在等待被实际回收内容的键个数。并不能体现单个大键的元素个数或等待lazy free回收的内存大小。所以此值有一定参考值,可监测redis lazy free的效率或堆积键数量;比如在flushall async场景下会有少量的堆积。
# info memory # Memory lazyfree_pending_objects:0
注意事项:unlink命令入口函数unlinkCommand()和del调用相同函数delGenericCommand()进行删除KEY操作,使用lazy标识是否为lazyfree调用。如果是lazyfree,则调用dbAsyncDelete()函数。
但并非每次unlink命令就一定启用lazy free,redis会先判断释放KEY的代价(cost),当cost大于LAZYFREE_THRESHOLD(64)才进行lazy free.
释放key代价计算函数lazyfreeGetFreeEffort(),集合类型键,且满足对应编码,cost就是集合键的元数个数,否则cost就是1。
举例:
-
一个包含100元素的list key, 它的free cost就是100
-
一个512MB的string key, 它的free cost是1 所以可以看出,redis的lazy free的cost计算主要时间复杂度相关。
9.AOF优化
Redis 提供了一个配置项,当子进程在 AOF rewrite 期间,可以让后台子线程不执行刷盘(不触发 fsync 系统调用)操作。
这相当于在 AOF rewrite 期间,临时把 appendfsync 设置为了 none,配置如下:
# AOF rewrite 期间,AOF 后台子线程不进行刷盘操作 # 相当于在这期间,临时把 appendfsync 设置为了 none no-appendfsync-on-rewrite yes
当然,开启这个配置项,在 AOF rewrite 期间,如果实例发生宕机,那么此时会丢失更多的数据,性能和数据安全性,你需要权衡后进行选择。
如果占用磁盘资源的是其他应用程序,那就比较简单了,你需要定位到是哪个应用程序在大量写磁盘,然后把这个应用程序迁移到其他机器上执行就好了,避免对 Redis 产生影响。
当然,如果你对 Redis 的性能和数据安全都有很高的要求,那么建议从硬件层面来优化,更换为 SSD 磁盘,提高磁盘的 IO 能力,保证 AOF 期间有充足的磁盘资源可以使用。同时尽可能让Redis运行在独立的机器上。
10.Swap优化
1)增加机器的内存,让 Redis 有足够的内存可以使用
2)整理内存空间,释放出足够的内存供 Redis 使用,然后释放 Redis 的 Swap,让 Redis 重新使用内存
释放 Redis 的 Swap 过程通常要重启实例,为了避免重启实例对业务的影响,一般会先进行主从切换,然后释放旧主节点的 Swap,重启旧主节点实例,待从库数据同步完成后,再进行主从切换即可。
预防的办法就是,你需要对 Redis 机器的内存和 Swap 使用情况进行监控,在内存不足或使用到 Swap 时报警出来,及时处理。
1.redis安装教程
https://www.cnblogs.com/alenblue/p/12893194.html
yum -y install gcc-c++ cd /opt tar -zxvf redis-7.0.15.tar.gz make && make install
2.Redis基本管理操作
2.1基础配置文件介绍:
mkdir /data/6379
vim /data/6379/redis.conf daemonize yes port 6379 logfile /data/6379/redis.log dir /data/6379 dbfilename dump.rdb
redis-cli shutdown redis-server /data/6379/redis.conf netstat -lnp|grep 63 +++++++++++配置文件说明++++++++++++++ redis.conf 是否后台运行: daemonize yes 默认端口: port 6379 日志文件位置 logfile /var/log/redis.log 持久化文件存储位置 dir /data/6379 RDB持久化数据文件: dbfilename dump.rdb redis-cli 127.0.0.1:6379> set name zhangsan OK 127.0.0.1:6379> get name "zhangsan"
2.2redis安全配置
(1)Bind :指定IP进行监听
vim /data/6379/redis.conf
bind 10.0.0.51 127.0.0.1
(2)增加requirepass {password}
vim /data/6379/redis.conf
requirepass 123456
----------验证-----
方法一:
[root@db03 ~]# redis-cli -a 123456
127.0.0.1:6379> set name zhangsan
OK
127.0.0.1:6379> exit
方法二:
[root@db03 ~]# redis-cli
127.0.0.1:6379> auth 123456
OK
127.0.0.1:6379> set a b
2.3redis持久化
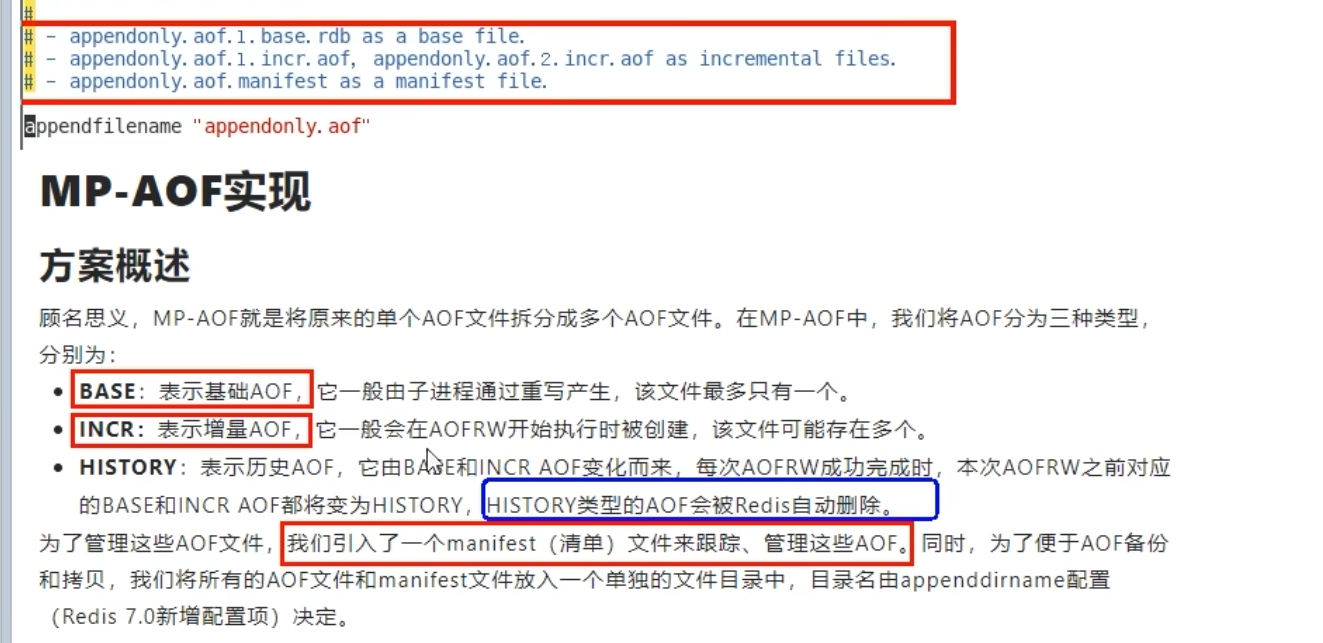
# 介绍 将内存数据保存到磁盘。redis默认没有开启持久化功能,需要认为设定。可以支持两种持久化功能:RDB、 AOF。 # 区别 redis 持久化方式有哪些?有什么区别? rdb:基于快照的持久化,速度更快,一般用作备份,主从复制也是依赖于rdb持久化功能 aof:以追加的方式记录redis操作日志的文件。可以最大程度的保证redis数据安全,类似于mysql的 binlog # RDB 持久化 vim /data/6379/redis.conf dir /data/6379 dbfilename dump.rdb stop-writes-on-bgsave-error yes #复制一致性,请求失败就终止复制。 rdbcompression yes #对rdb文件进行压缩,如果不想消耗cpu性能的话可以关闭。 rdbchecksum yes #对rdb进行校验(使用CRC64算法),会消耗cpu10%的性能。 rdb-del-sync-files no #在没有持久性的情况下删除复制中使用的RDB文件,默认关闭状态。 save 900 1 save 300 10 save 60 10000 配置分别表示: 900秒(15分钟)内有1个更改 300秒(5分钟)内有10个更改 60秒内有10000个更改 手动保存 bgsave #不要用save,会堵塞redis。 ------数据恢复------ redis-check-rdb dump.rdb #修复文件 # AOF 持久化(append-only log file) AOF持久化配置 appendonly yes appendfsync always #同步写入,每有一条写入命令就写入文件。 appendfsync everysec #操作系统控制写回,每个写命令执行完,只是把日志写到AOF文件的缓冲区由操作系统决定何时将缓冲区内容写入磁盘。 appenddirname "appendonlydir" #设置aof文件夹,redis7的rdb和aof文件不是在一个文件夹了,6之前是一起的,这个配置redis7才有。 appendfilename "appendonly.aof"
# appendonly参数开启AOF持久化 appendonly no # AOF持久化的文件名,默认是appendonly.aof appendfilename "appendonly.aof" # AOF文件的保存位置和RDB文件的位置相同,都是通过dir参数设置的 dir ./ # 同步策略 # appendfsync always appendfsync everysec # appendfsync no # aof重写期间是否同步 no-appendfsync-on-rewrite no # 重写触发配置 auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb # 加载aof出错如何处理 aof-load-truncated yes # 文件重写策略 aof-rewrite-incremental-fsync yes
-----------------------redis7的新特性-------------------------------



3.redis数据类型及应用场景
3.1 strings

应用场景 常规计数: 微博数,粉丝数等。 订阅、礼物、页游 基础应用例子: (1) set name zhangsan (2) MSET id 101 name zhangsan age 20 gender m 等价于以下操作: SET id 101 set name zhangsan set age 20 set gender m (3)计数器 每点一次关注,都执行以下命令一次 127.0.0.1:6379> incr num 显示粉丝数量: 127.0.0.1:6379> get num 暗箱操作: 127.0.0.1:6379> INCRBY num 10000 (integer) 10006 127.0.0.1:6379> get num "10006" 127.0.0.1:6379> DECRBY num 10000 (integer) 6 127.0.0.1:6379> get num "6 增: set mykey "test" 为键设置新值,并覆盖原有值 getset mycounter 0 设置值,取值同时进行 setex mykey 10 "hello" 设置指定 Key 的过期时间为10秒,在存活时间可以获取value setnx mykey "hello" 若该键不存在,则为键设置新值 mset key3 "zyx" key4 "xyz" 批量设置键 删: del mykey 删除已有键 改: append mykey "hello" 若该键并不存在,返回当前 Value 的长度 该键已经存在,返回追加后 Value的长度 incr mykey 值增加1,若该key不存在,创建key,初始值设为0,增加后结果为1 decrby mykey 5 值减少5 setrange mykey 20 dd 把第21和22个字节,替换为dd, 超过value长度,自动补0 查: exists mykey 判断该键是否存在,存在返回 1,否则返回0 get mykey 获取Key对应的value strlen mykey 获取指定 Key 的字符长度 ttl mykey 查看一下指定 Key 的剩余存活时间(秒数) getrange mykey 1 20 获取第2到第20个字节,若20超过value长度,则截取第2个和后面所有的 mget key3 key4 批量获取键

3.2 hash类型(字典类型)
应用场景:
存储部分变更的数据,如用户信息等。
最接近mysql表结构的一种类型
基础例子:
存数据:
hmset stu id 101 name zhangsan age 20 gender m
hmset stu1 id 102 name zhangsan1 age 21 gender f
取数据:
HMGET stu id name age gender
HMGET stu1 id name age gender
select concat("hmset city_",id," id ",id," name ",name," countrycode
",countrycode," district ",district," population ",population) from city limit
10 into outfile '/tmp/hmset.txt'
更多的例子:
增
hset myhash field1 "s"
若字段field1不存在,创建该键及与其关联的Hashes, Hashes中,key为field1 ,并设value为s ,若存在会覆盖原value
hsetnx myhash field1 s
若字段field1不存在,创建该键及与其关联的Hashes, Hashes中,key为field1 ,并设value为s, 若字段field1存在,则无效
hmset myhash field1 "hello" field2 "world 一次性设置多个字段
删
hdel myhash field1 删除 myhash 键中字段名为 field1 的字段
del myhash 删除键
改
hincrby/hincrbyfloat myhash field 1 给field的值加1,float可加小数点类型,例如增加0.5.
查
hget myhash field1 获取键值为 myhash,字段为 field1 的值
hlen myhash 获取myhash键的字段数量
hexists myhash field1 判断 myhash 键中是否存在字段名为 field1 的字段
hmget myhash field1 field2 field3 一次性获取多个字段
hgetall myhash 返回 myhash 键的所有字段及其值
hkeys myhash 获取myhash 键中所有字段的名字
hvals myhash 获取 myhash 键中所有字段的值
3.3 LIST(列表)
应用场景 消息队列系统 比如sina微博:在Redis中我们的最新微博ID使用了常驻缓存,这是一直更新的。 但是做了限制不能超过5000个ID,因此获取ID的函数会一直询问Redis。 只有在start/count参数超出了这个范围的时候,才需要去访问数据库。 系统不会像传统方式那样“刷新”缓存,Redis实例中的信息永远是一致的。 SQL数据库(或是硬盘上的其他类型数据库)只是在用户需要获取“很远”的数据时才会被触发,而主页或第一个评论页是不会麻烦到硬盘上的数据库了。 微信朋友圈: 127.0.0.1:6379> LPUSH wechat "today is nice day !" 127.0.0.1:6379> LPUSH wechat "today is bad day !" 127.0.0.1:6379> LPUSH wechat "today is good day !" 127.0.0.1:6379> LPUSH wechat "today is rainy day !" 127.0.0.1:6379> LPUSH wechat "today is friday !" [5,4,3,2,1] 0 1 2 3 4 [e,d,c,b,a] 0 1 2 3 4 127.0.0.1:6379> lrange wechat 0 0 1) "today is friday !" 127.0.0.1:6379> lrange wechat 0 1 1) "today is friday !" 2) "today is rainy day !" 127.0.0.1:6379> lrange wechat 0 2 1) "today is friday !" 2) "today is rainy day !" 3) "today is good day !" 127.0.0.1:6379> lrange wechat 0 3 127.0.0.1:6379> lrange wechat -2 -1 1) "today is bad day !" 2) "today is nice day !"

linsert key before/after vlaue1 vlaue 2 #在对应元素前面或后面插入新元素
lset key index value #修改对应下标的元素
3.4 SortedSet(有序集合)
应用场景: 排行榜应用,取TOP N操作【排行榜的操作】 这个需求与上面需求的不同之处在于,前面操作以时间为权重,这个是以某个条件为权重,比如按顶的次数排序, 这时候就需要我们的sorted set出马了,将你要排序的值设置成sorted set的score,将具体的数据设置成相应的value, 每次只需要执行一条ZADD命令即可。 -------------- 127.0.0.1:6379> zadd topN 0 smlt 0 fskl 0 fshkl 0 lzlsfs 0 wdhbx 0 wxg (integer) 6 127.0.0.1:6379> ZINCRBY topN 100000 smlt "100000" 127.0.0.1:6379> ZINCRBY topN 10000 fskl "10000" 127.0.0.1:6379> ZINCRBY topN 1000000 fshkl "1000000" 127.0.0.1:6379> ZINCRBY topN 100 lzlsfs "100" 127.0.0.1:6379> ZINCRBY topN 10 wdhbx "10" 127.0.0.1:6379> ZINCRBY topN 100000000 wxg "100000000" 127.0.0.1:6379> ZREVRANGE topN 0 2 1) "wxg" 2) "fshkl" 3) "smlt" 127.0.0.1:6379> ZREVRANGE topN 0 2 withscores 1) "wxg" 2) "100000000" 3) "fshkl" 4) "1000000" 5) "smlt" 6) "100000" 127.0.0.1:6379>
zrange topN 0 -1 withscores #把分数也显示出来 zrangebyscore topN min max withscores limit 值 #按照分数范围查找元素,limit限制显示元素个数。
zmpop 1 topN min/max count 1 #前面的1为key的个数,后面的1为元素个数,剔除最大或最小分数的元素。

3.5 set集合




3.6 位图(bitmap)

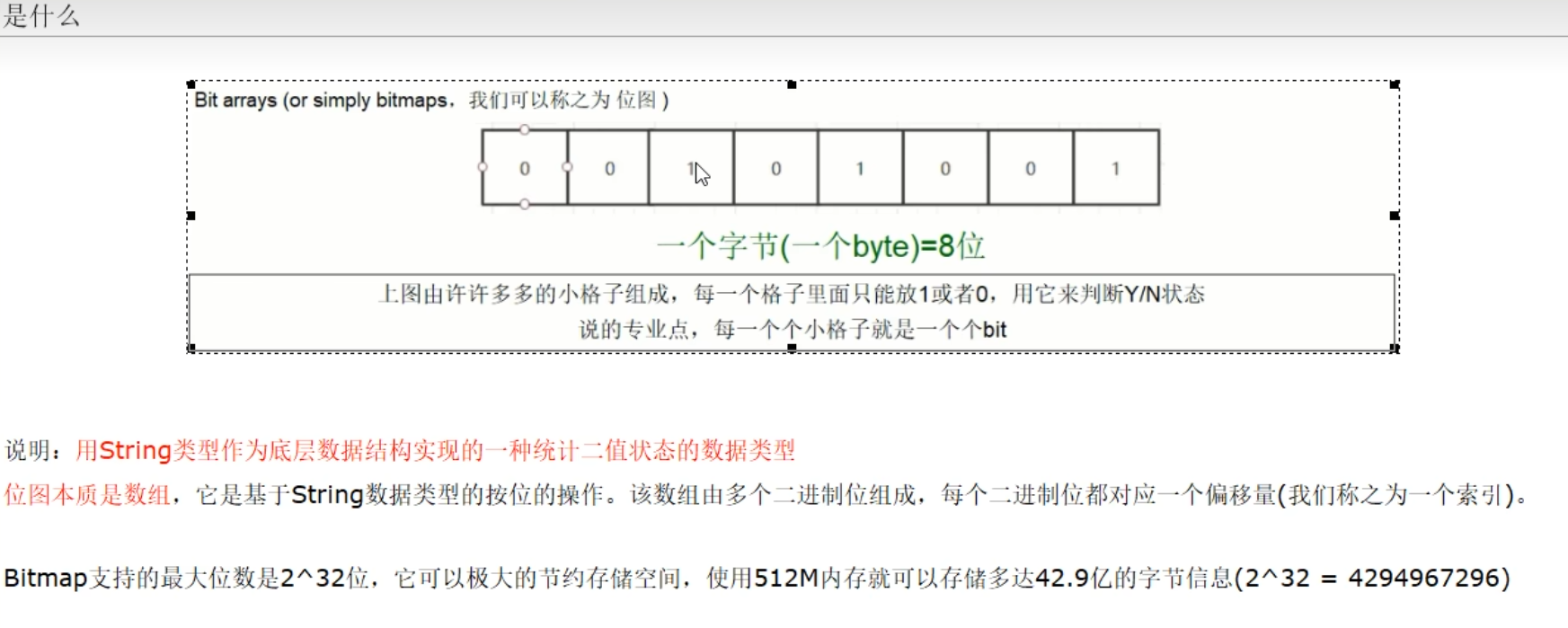
setbit k1 1 1 #设置值,下标依旧以0开始。 getbit k1 1 #获取对应下标元素值。 strlen k1 #获取大小,返回的是字节值,一个字节8位 bitcount k1 #统计key中等于1的个数。

bitop 是做两个bitmap的集合运算,并将交集或并集统计个数放在第三个key中,使用命令bitcount查看统计的结果即可。具体如下图


3.7 基数统计(HyperLogLog)




3.8 地理空间(GEO)


3.9 流(stream)【redis版消息中间件】

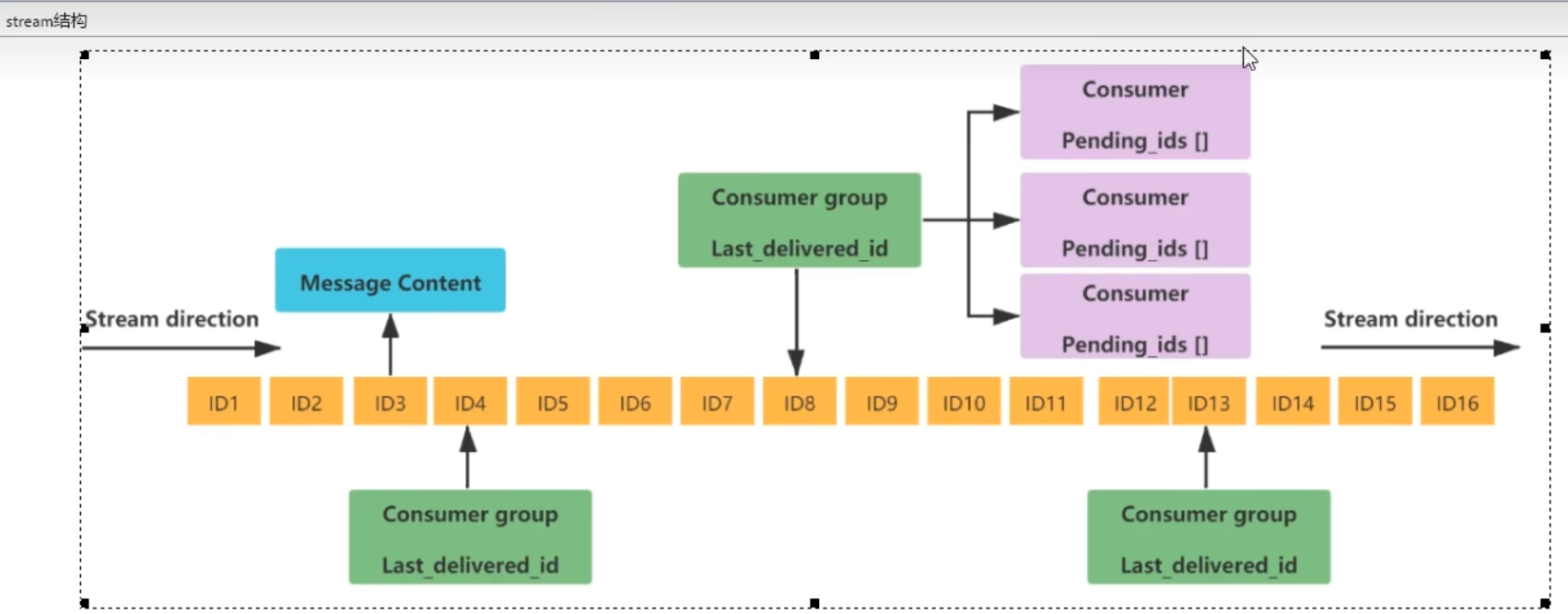

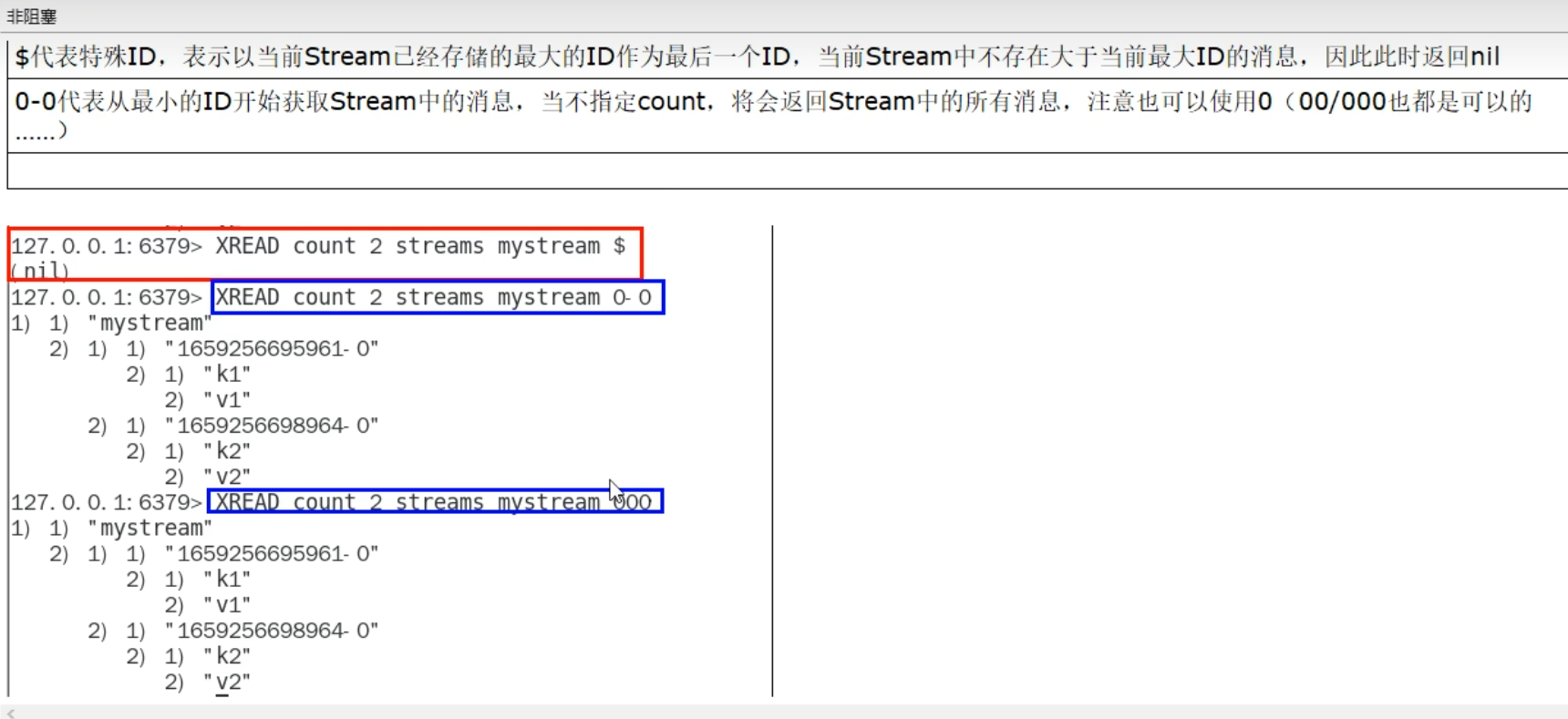
xadd mystream * id 11 cname z3

xrevrange mystream + - #降序输出元素

xdel 删除元素

xlen mystream #获取元素个数 xtrim mystream maxlen/minid










4、redis(master-replicaset)
4.1 原理:
1. 副本库通过slaveof 10.0.0.51 6379命令,连接主库,并发送SYNC给主库 2. 主库收到SYNC,会立即触发BGSAVE,后台保存RDB,发送给副本库 3. 副本库接收后会应用RDB快照 4. 主库会陆续将中间产生的新的操作,保存并发送给副本库 5. 到此,我们主复制集就正常工作了 6. 再此以后,主库只要发生新的操作,都会以命令传播的形式自动发送给副本库. 7. 所有复制相关信息,从info信息中都可以查到.即使重启任何节点,他的主从关系依然都在. 8. 如果发生主从关系临时,从库数据没有任何损坏,在下次重连之后,从库发送PSYN给主库 9. 主库只会将从库缺失部分的数据同步给从库应用,达到快速恢复主从的目的
4.2 主从复制实现
1、环境:
准备两个或两个以上redis实例
mkdir /data/638{0..2}
配置文件示例:
cat >> /data/6380/redis.conf <<EOF
port 6380
daemonize yes
pidfile /data/6380/redis.pid
loglevel notice
logfile "/data/6380/redis.log"
dbfilename dump.rdb
dir /data/6380
requirepass 123
masterauth 123
EOF
cat >> /data/6381/redis.conf <<EOF
port 6381
daemonize yes
pidfile /data/6381/redis.pid
loglevel notice
logfile "/data/6381/redis.log"
dbfilename dump.rdb
dir /data/6381
requirepass 123
replicaof <masterip> <masterport>
masterauth 123
EOF
cat >> /data/6382/redis.conf <<EOF
port 6382
daemonize yes
pidfile /data/6382/redis.pid
loglevel notice
logfile "/data/6382/redis.log"
dbfilename dump.rdb
dir /data/6382
requirepass 123
replicaof <masterip> <masterport>
masterauth 123
EOF
启动:
redis-server /data/6380/redis.conf
redis-server /data/6381/redis.conf
redis-server /data/6382/redis.conf
主节点:6380
从节点:6381、6382
2、开启主从:
6381/6382命令行:
redis-cli -p 6381 -a 123 SLAVEOF 127.0.0.1 6380
redis-cli -p 6382 -a 123 SLAVEOF 127.0.0.1 6380
3、查询主从状态
redis-cli -p 6380 -a 123 info replication
redis-cli -p 6381 -a 123 info replication
redis-cli -p 6382 -a 123 info replication
4、从库切为主库
模拟主库故障
redis-cli -p 6380 -a 123 shutdown
redis-cli -p 6381 -a 123 info replication
slaveof no one 【解除主从关系】
6382连接到6381:
[root@db03 ~]# redis-cli -p 6382 -a 123
127.0.0.1:6382> SLAVEOF no one
127.0.0.1:6382> SLAVEOF 127.0.0.1 6381

5.redis-sentinel(哨兵)
5.1功能及原理介绍
1、监控、和负载均衡 2、自动选主,切换(6381 slaveof no one) 3、2号从库(6382)指向新主库(6381) 4、应用透明 5、多sentinel防止脑裂
5.2 sentinel搭建过程
mkdir /data/26380 cd /data/26380 vim sentinel.conf port 26380 dir "/data/26380" port 26379 daemonize no pidfile /var/run/redis-sentinel.pid logfile "" sentinel monitor mymaster 127.0.0.1 6381 1 # 最后一个的值表示多少个哨兵节点算投票通过的值 sentinel down-after-milliseconds mymaster 5000 # 5000是毫米,等同于5秒,表示心跳检查超时时间,过了该时间表示客观下线。 sentinel auth-pass mymaster 123 启动: redis-sentinel /data/26380/sentinel.conf & 如果有问题: 1、重新准备1主2从环境 2、kill掉sentinel进程 3、删除sentinel目录下的所有文件 4、重新搭建sentinel

6.redis cluster(高可用集群)
6.1 原理及分片原理
https://blog.csdn.net/weixin_39815456/article/details/111172917



高性能: 1、在多分片节点中,将16384个槽位,均匀分布到多个分片节点中 2、存数据时,将key做crc16(key),然后和16384进行取模,得出槽位值(0-16383之间) 3、根据计算得出的槽位值,找到相对应的分片节点的主节点,存储到相应槽位上 4、如果客户端当时连接的节点不是将来要存储的分片节点,分片集群会将客户端连接切换至真正存储节点进 行数据存储 高可用: 在搭建集群时,会为每一个分片的主节点,对应一个从节点,实现slaveof的功能,同时当主节点down,实 现类似于sentinel的自动failover的功能。 1、redis会有多组分片构成(3组) 2、redis cluster 使用固定个数的slot存储数据(一共16384slot) 3、每组分片分得1/3 slot个数(0-5500 5501-11000 11001-16383) 4、基于CRC16(key) % 16384 ====》值 (槽位号)。
6.2规划、搭建过程
1、集群节点准备
mkdir /data/700{0..5}
cat > /data/7000/redis.conf <<EOF
port 7000
daemonize yes
pidfile /data/7000/redis.pid
loglevel notice
logfile "/data/7000/redis.log"
dbfilename dump.rdb
dir /data/7000
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
cat >> /data/7001/redis.conf <<EOF
port 7001
daemonize yes
pidfile /data/7001/redis.pid
loglevel notice
logfile "/data/7001/redis.log"
dbfilename dump.rdb
dir /data/7001
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
cat >> /data/7002/redis.conf <<EOF
port 7002
daemonize yes
pidfile /data/7002/redis.pid
loglevel notice
logfile "/data/7002/redis.log"
dbfilename dump.rdb
dir /data/7002
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
cat >> /data/7003/redis.conf <<EOF
port 7003
daemonize yes
pidfile /data/7003/redis.pid
loglevel notice
logfile "/data/7003/redis.log"
dbfilename dump.rdb
dir /data/7003
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
cat >> /data/7004/redis.conf <<EOF
port 7004
daemonize yes
pidfile /data/7004/redis.pid
loglevel notice
logfile "/data/7004/redis.log"
dbfilename dump.rdb
dir /data/7004
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
cat >> /data/7005/redis.conf <<EOF
port 7005
daemonize yes
pidfile /data/7005/redis.pid
loglevel notice
logfile "/data/7005/redis.log"
dbfilename dump.rdb
dir /data/7005
protected-mode no
cluster-enabled yes
cluster-config-file nodes.conf
cluster-node-timeout 5000
appendonly yes
EOF
启动节点:
redis-server /data/7000/redis.conf
redis-server /data/7001/redis.conf
redis-server /data/7002/redis.conf
redis-server /data/7003/redis.conf
redis-server /data/7004/redis.conf
redis-server /data/7005/redis.conf
2、将节点加入集群管理
redis-cli --cluster create 127.0.0.1:7000 127.0.0.1:7001 127.0.0.1:7002 127.0.0.1:7003 127.0.0.1:7004 127.0.0.1:7005 --cluster-replicas 1
3、集群状态查看
集群主节点状态
redis-cli -p 7000 cluster nodes | grep master
集群从节点状态
redis-cli -p 7000 cluster nodes | grep slave
6.3 集群节点管理
1. 添加主节点: redis-cli --cluster add-node 127.0.0.1:7006 127.0.0.1:7000 2. 转移slot(重新分片) redis-cli --cluster reshard 127.0.0.1:7000 3. 添加一个从节点 redis-cli --cluster add-node --slave --master-id 49257f251824dd815bc7f31e1118b670365e861a 127.0.0.1:7007 127.0.0.1:7000 4. 删除节点 将需要删除节点slot移动走 redis-cli --cluster reshard 127.0.0.1:7000 5. 删除一个节点 删除master节点之前首先要使用reshard移除master的全部slot,然后再删除当前节点
redis-cli --cluster del-node 127.0.0.1:7006 49257f251824dd815bc7f31e1118b670365e861a redis-cli --cluster del-node 127.0.0.1:7007 733ca5fe229aca0c8a1d88bead46298e71d9be82
cluster failover #主从节点切换

