欢迎来到K8S
1|0欢迎来到K8S
1|1一、学习目标
- 看k8s系统架构图. 知道集群有哪些组件, master和node上有什么组件, 什么职责.
- pod有哪些状态, 这些状态如何流转.
- 如果pod计划对外提供服务, 怎么办?
- pod间是如何联网的, underlay和overlay的差异.
- pause容器的用途.
1|2二、k8s概念
什么是k8s
kubernetes,简称K8s,是用8代替名字中间的8个字符“ubernete”而成的缩写。是一个开源的,用于管理云平台中多个主机上的容器化的应用,Kubernetes的目标是让部署容器化的应用简单并且高效(powerful),Kubernetes提供了应用部署,规划,更新,维护的一种机制。
k8s资源关系
k8s资源类型主要有Deployment、Service、Pod、ReplicaSet,它们的关系如图:
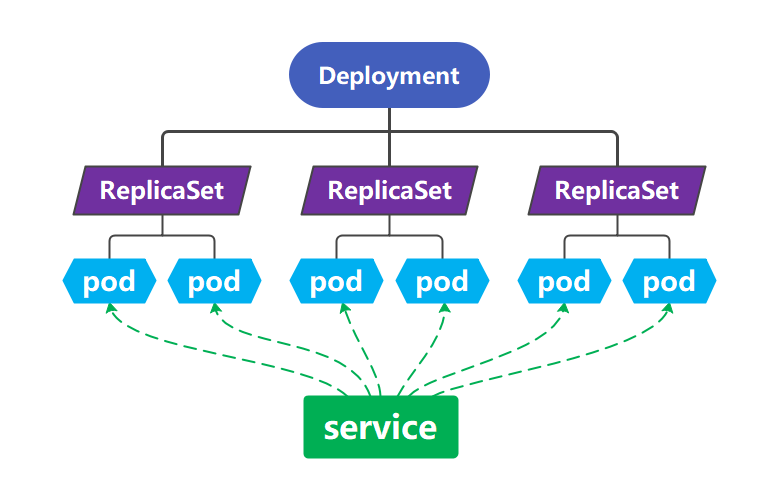
即Deployment管理ReplicaSet,ReplicaSet管理pod,service请求转发,由一个或多个pod组成一个服务,统一对外提供服务。
| 名称 | 描述 |
|---|---|
| pod | k8s 集群的最小单元,一个 pod 可以包含一个或者多个容器。 |
| Namespace | 命名空间,用于将一个 k8s 集群隔离成不同的空间,pod, service, rc, volume 都可以在创建的时候指定其 namespace。 |
| ReplicaSet | ReplicaSet是Replication Controller升级版,确保Pod以指定的副本个数运行。 |
| Deployment | Deployment用于管理Pod、ReplicaSet,可实现滚动升级和回滚应用、扩容和缩容。 |
| Service | k8s的Service定义了一个服务的访问入口地址,前端的应用通过这个入口地址访问其背后的一组由Pod副本组成的集群实例,来自外部的访问请求被负载均衡到后端的各个容器应用上,Service与其后端Pod副本集群之间则是通过Label Selector实现关联。 |
| NordPort | 将外部请求转发到到k8s集群内部访问的node节点端口,外部请求通过nodeIP:nodePort到服务器,系统通过nodePort->service端口的映射,将请求转发到对应service。 |
| Label | 标签(Label)是附在kubernetes 对象(如pod,deployment等)上的键值对(key-value),可以在创建时指定,也可以在创建后指定,一个资源拥有多个标签,可以实现不同维度的管理,通过 selector 进行集群内标签选择对象概念,并进行后续操作。 |
1|3四、k8s组件
组件介绍
k8s集群由Master控制节点和Node(Worker)工作节点组成,每个节点上都会安装不同的组件。
Master节点(管理)
Master节点指的是集群控制节点,管理和控制整个集群,基本上k8s的所有控制命令都发给它,它负责具体的执行过程。在Master上主要运行着:
-
ApiServer
-
Scheduler
-
Controller-Manager
-
Etcd
-
add-ons
Node节点(工作)
除了master以外的节点被称为Node或者Worker节点,可以在master中使用命令 kubectl get nodes查看集群中的node节点。每个Node都会被Master分配一些工作负载(Docker容器),当某个Node宕机时,该节点上的工作负载就会被Master自动转移到其它节点上。在Node上主要运行着:
-
kubelet
-
kube-proxy
-
Docker
组件职责
- ApiServer:集群中所有资源的统一访问入口,接收用户输入的命令,提供认证、授权、API注册和发现等机制;
- Scheduler:负责集群资源调度,将新创建的pod根据策略调度到合适的节点上;
- Controller-Manager:负责维护集群的状态,集群中所有资源对象的自动化控制中心,比如程序部署安排、故障检测、自动扩展、滚动更新等;
- Etcd:负责存储集群中各种资源对象的信息,保存集群中的所有资源对象的数据;
- Kubelet:负责pod对应的容器的创建、启动、停止、更新等任务,同时与Master节点密切协作,实现集群管理的基本功能;
- Kube-proxy:负责提供集群内部的服务发现和负载均衡,将对service的访问转发到后端的一组pod上;
- Docker:负责节点上容器的各种操作,Docker本身并不是容器,它是创建容器的工具,是应用容器引擎。Docker技术的三大核心概念,分别是镜像(Image)、容器(Container)、仓库(Repository),k8s是一个开源的容器集群管理系统,常用的就是用来编排调度Docker引擎。
1|4五、k8s基本工作流程
从kubectl开始,看一下K8s的基本工作流程:
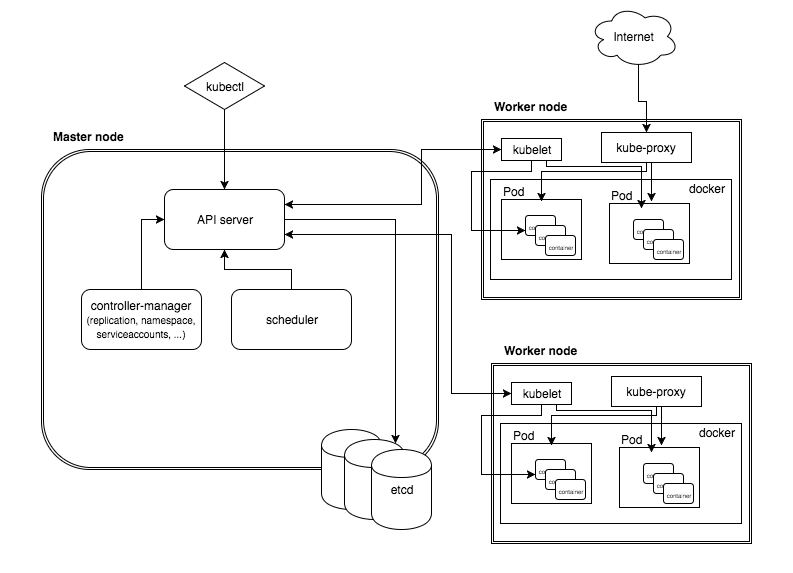
- kubectl 客户端首先将
CLI命令(命令行界面)转化为RESTful(一种网络应用程序的设计风格和开发方式)的API调用,然后发送到kube-apiserver。 - kube-apiserver 在验证这些 API 调用后,将任务元信息并存储到etcd,接着调用 kube-scheduler 开始决策一个用于作业的Node节点。
- 一旦 kube-scheduler 返回一个适合调度的目标节点后,kube-apiserver 就把任务的节点信息存入etcd,并创建任务。
- 此时目标节点中的 kubelet正监听apiserver,当监听到有新任务需要调度到本节点后,kubelet通过本地runtime创建任务容器,执行作业。
- 接着kubelet将任务状态等信息返回给apiserver存储到etcd。
- 这样我们的任务已经在运行了,此时control-manager发挥作用保证任务一直是我们期望的状态。
通过deployment部署pod的常规流程:
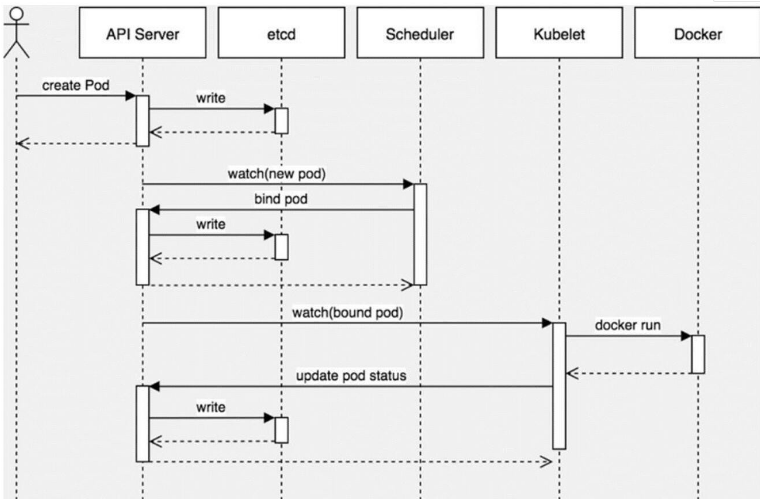
-
运维人员通过kubectl向apiserver发送部署请求
-
apiserver将 Deployment 持久化到etcd;etcd与apiserver进行一次http通信,创建Deployment资源并初始化(期望状态);
-
controller-manager通过list-watch机制,监听apiserver,deployment controller看到了一个新创建的deplayment对象后,将其从队列中拉出,根据Deployment的描述创建一个ReplicaSet并将 ReplicaSet 对象返回apiserver并持久化回etcd;
以此类推,当replicaset控制器看到新创建的replicaset对象,将其从队列中拉出,根据描述创建pod对象。
- list-watch:监视列表,K8S 统一的异步消息处理机制,保证了消息的实时性,可靠性,顺序性,性能。
- Deployment:通过管理replicaset来间接管理pod,即:deployment管理replicaset,replicaset管理pod。
- replicaset:简称RS,取代 ReplicationController,确保Pod以你指定的副本数运行,即如果有容器异常退出,会自动创建新的 Pod 来替代;而异常多出来的容器也会自动回收,实现了集群的高可用性。
- controller:集群上管理和运行容器的对象
-
接着scheduler调度器看到未调度的pod对象,根据调度规则选择一个可调度的节点,加载到pod描述中nodeName字段,并将pod对象返回apiserver并写入etcd;
-
scheduler通过list-watch机制,监测发现新的pod,经过主机过滤、主机打分规则,将pod绑定(binding)到合适的主机;
-
将绑定结果存储到etcd;
-
-
kubelet每隔 20s(可以自定义)向apiserver通过NodeName 获取自身Node上所要运行的pod清单.通过与自己的内部缓存进行比较,新增加pod;
-
kube-proxy为新创建的pod注册动态DNS到CoreOS。给pod的service添加iptables/ipvs规则,用于服务发现和负载均衡;
-
Controller-Manager通过
control loop(控制循环)将当前pod状态与用户所期望的状态做对比,如果当前状态与用户期望状态不同,则controller会将pod修改为用户期望状态,实在不行会将此pod删掉,然后重新创建pod。
pod的生产
- 用户提交创建POD请求
- API Server 处理用户请求,存储Pod数据到Etcd
- Schedule通过和 API Server的监听机制,查看到新的pod,尝试为Pod绑定Node
- 过滤主机:调度器用一组规则过滤掉不符合要求的主机,比如Pod指定了所需要的资源,那么就要过滤掉资源不够的主机
- 主机打分:对第一步筛选出的符合要求的主机进行打分,在此阶段,调度器会考虑一些整体优化策略,比如把一个Replication Controller的副本分布到不同的主机上,使用最低负载的主机等
- 选择主机:选择得分最高的主机,进行
binding(绑定)操作,结果存储到Etcd中 - kubelet根据调度结果执行Pod创建操作:绑定成功后,会启动container, Docker run, scheduler会调用API Server的API在etcd中创建一个bound pod对象,描述在一个工作节点上绑定运行的所有pod信息。运行在每个工作节点上的kubelet也会定期与etcd同步bound pod信息,一旦发现应该在该工作节点上运行的bound pod对象没有更新,则调用Docker API创建并启动pod内的容器
- POD创建完成
1|5六、Pod生命周期
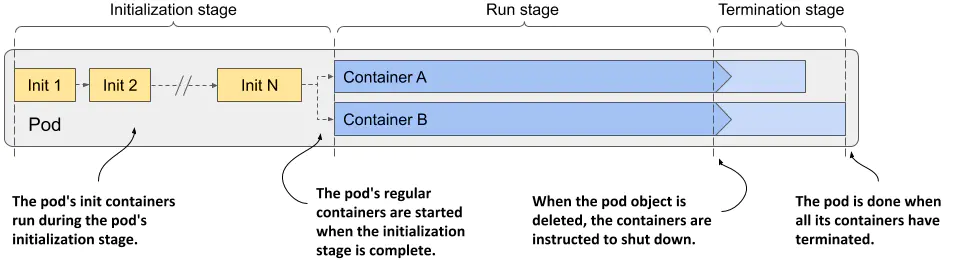
如图展示了Pod的生命周期,分为三个阶段
- initialization-初始化阶段
在此期间 pod 的 init 容器运行 - run-运行阶段
Pod 的常规容器在其中运行 - termination-终止阶段
在该阶段终止 pod 的容器
pod状态
Kubernetes pod 的阶段
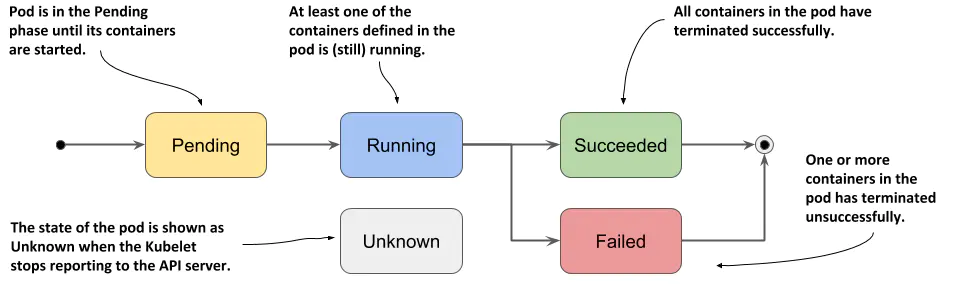
- 用户发起创建pod请求到apiserver,apiserver存储pod信息到etcd中。pod还未调度,pod的nodeName是空的,此时pod处于Pending状态。
- scheduler监听到 pending状态的pod,经过调度策略(资源请求,tolerations,亲和度等)选择一个节点,调度后此时pod处于ContainerCreating状态。
- node上的kublet调用CRI,CNI,CSI接口启动容器,启动后pod处于Running状态。
- 用户删除pod时,pod立即处于Terminating状态。停止容器进程,删除网络,卸载目录挂载,删除finalizer。即删除所有和pod有关的对象(gone)。
- 假如pod中的所有容器进程都异常退出了,或者至少有一个容器进程exit非0,且重启策略为Never,那么pod处于Failed状态。
- 假如node由于网络原因,无法上报状态,那么pod处于Unknown状态。
- 假如pod中的所有容器进程都正常退出了,且重启策略为Never,那么pod处于Successd状态。
- 假如pod被kubelet驱逐了,那么pod处于Evicted状态。
pod状态表
| 状态值 | 描述 |
|---|---|
| Pending | 创建 Pod 对象后,在 pod 被调度到一个节点并且它的容器的镜像被拉取和启动之前,它一直处于这个阶段。 |
| Running | Pod内所有容器均已创建,且至少有一个容器处于运行状态,正在启动状态或正在重启状态。 |
| Succeeded | Pod内所有容器均成功执行后退出,且不会再重启。 |
| Failed | Pod内所有容器均以退出,但至少有一个容器为退出失败状态。 |
| Unknown | 由于某种原因无法获取该Pod的状态,可能由于网络通信不畅导致。 |
显示pod状态
Pod状况(Condition)
简介
可以通过查看Pod的Condition列表了解更多信息,pod的Condition指示pod是否已达到某个状态,以及为什么会这样,与状态相反,一个Pod同时具有多个Conditions
Pod条件表
| Pod Condition | 描述 |
|---|---|
| PodScheduled | 表示pod是否已调度到节点 |
| Initialized | Pod的 init容器都已成功完成 |
| ContainersReady | Pod 中所有容器都已就绪 |
| Ready | Pod 可以为请求提供服务,并且应该被添加到对应服务的负载均衡池中 |
显示pod状况
容器状态
容器状态最重要的部分是它的 state,容器可以处于下图所示的状态之一
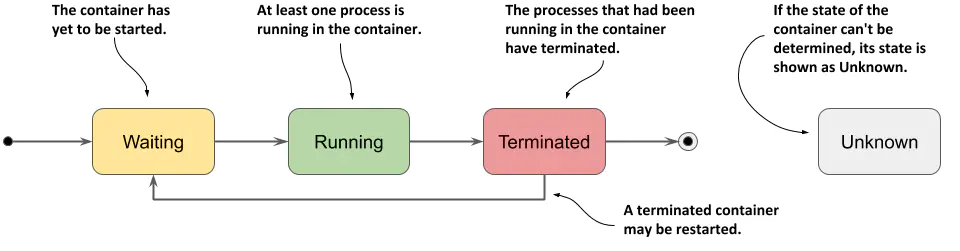
容器状态表
| Container State | 描述 |
|---|---|
| Waiting | 容器正在等待启动 |
| Running | 容器已创建并且进程正在其中运行,startAt字段指示此容器启动的时间 |
| Terminated | 已在容器中运行的进程已终止,finishedAt 字段指示容器何时终止,主进程终止的退出代码位于exitCode字段中 |
| Unknown | 无法确定容器的状态 |
显示pod容器状态
1|6七、pod对外提供服务
k8s集群的三种IP
- Node IP:Node节点的IP地址,即物理网卡的IP地址。
- Pod IP:Pod的IP地址,即docker容器的IP地址,此为虚拟IP地址。
- Cluster IP:Service的IP地址,此为虚拟IP地址。
Service资源
Service是服务的访问入口地址,是一组由pod副本组成的集群实例,service和pod通过标签选择器Lbel Selector实现关联。
暴露服务的方式
1、port-forward 映射服务到端口
通过命令的方式把pod端口映射到本地的端口上
2、HostNetwork
HostNetwork设置对象是pod,当hostnetwork为true时,pod中的容器直接暴露再宿主机的网络环境中,可以直接通过宿主机的网络访问pod中的应用程序,即pod的ip就是node的ip,该模式下,每一个node只能启动一个同deployment的pod。
可以直接通过宿主机的IP+端口来访问这个pod
3、HostPort
HostPost设置对象是容器,将容器的端口通过hostIP:hostPort的方式暴露出来。
访问方式如下:
4、NodePort
NodePort的设置对象是service,默认情况下service只能在集群内部通过ClusterIP访问。首先定义pod如下:
创建NodePort service时,用户可以指定范围为30000-32767的端口,对该端口的访问就能通过 kube-proxy 代理到service后端的pod中。NodePort service的配置如下:
NodePort 访问方式,集群内任意node的ip+NodePort端口号,即可访问,如下:
该方式集群内pod已实现负载均衡;
5、LoadBalane 云服务器场景
Service利用load balancer (服务或设备)对外提供服务,LB负责将流量导向service,适用于云平台。
6、Ingress
Ingress 生产环境建议使用,作用于nginx类似,需要部署一个ingress-controller的服务,该服务使用以上几种方式提供集群外的访问;再根据业务配置路由规则,访问集群内的其它服务。
可以理解为就是一个nginx的服务器,本质就是一个nginx和许多配置文件
__EOF__

本文链接:https://www.cnblogs.com/leixixi/p/17027774.html
关于博主:努力学习Linux的小萌新,希望从今天开始慢慢提高,一步步走向技术的高峰!
版权声明:本博客所有文章除特别声明外,均采用 BY-NC-SA 许可协议。转载请注明出处!
声援博主:如果您觉得文章对您有帮助,可以点击文章右下角【推荐】一下。您的鼓励是博主的最大动力!


【推荐】国内首个AI IDE,深度理解中文开发场景,立即下载体验Trae
【推荐】编程新体验,更懂你的AI,立即体验豆包MarsCode编程助手
【推荐】抖音旗下AI助手豆包,你的智能百科全书,全免费不限次数
【推荐】轻量又高性能的 SSH 工具 IShell:AI 加持,快人一步
· 10年+ .NET Coder 心语 ── 封装的思维:从隐藏、稳定开始理解其本质意义
· 地球OL攻略 —— 某应届生求职总结
· 提示词工程——AI应用必不可少的技术
· Open-Sora 2.0 重磅开源!
· 周边上新:园子的第一款马克杯温暖上架