


对xgboost中dump_model生成的booster进行解析
xgboost原生包中有一个dump_model方法,这个方法能帮助我们看到基分类器的决策树如何选择特征进行分裂节点的,使用的基分类器有两个特点:
- 二叉树;
- 特征可以重复选择,来切分当前节点所含的数据集.
由dump_model生成的booster格式如下:
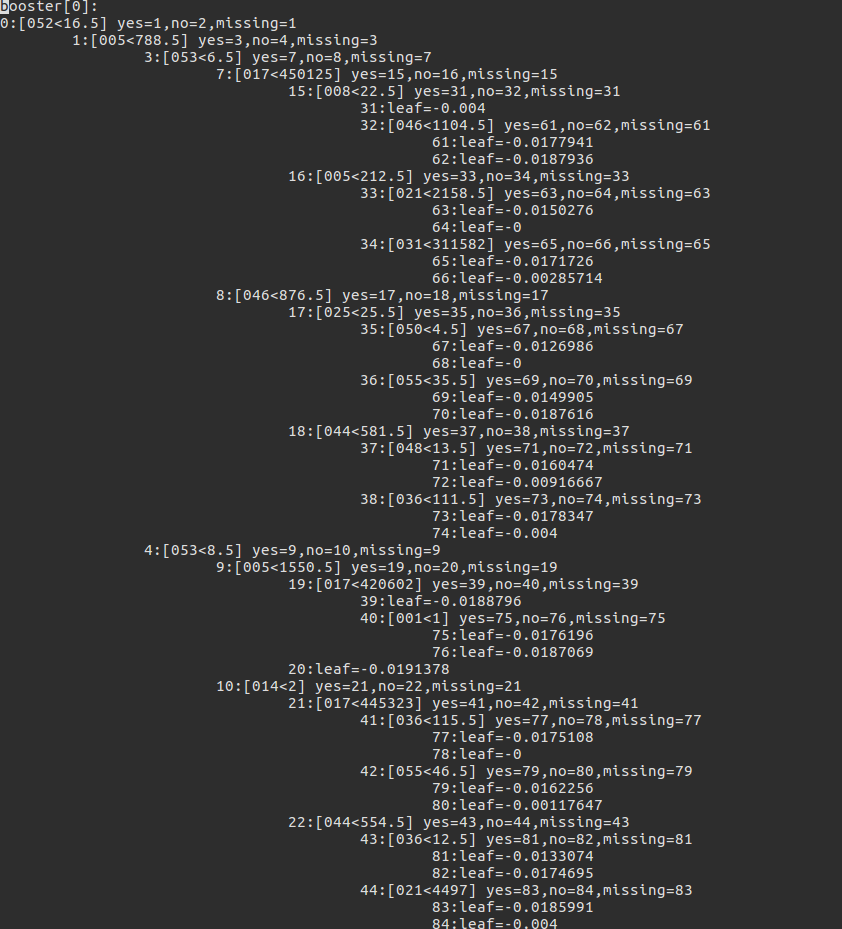
我们可以对该类型的树结构进行解析,得到这个基分类器中特征用来分裂的频率,简单的脚本如下:
# -*- coding: utf-8 -*-
import re
with open('./tree_like.txt', 'r') as f:
lines = f.readlines()
# 初步预处理
comp = []
for line in lines:
new_line = line.replace(' ', '*')
if line.find('leaf') < 0 and (line.startswith('*') or line.startswith('0')):
regular = re.sub(r'(\**)[0-9]{1,2}:\[([0-9]{3})<.*', r'\1\2', new_line).strip()
# print regular
comp.append(regular)
# 解析部分
i = 0
res = {}
for cur in comp:
cur_8 = cur.count('*')
if comp.index(cur, i, len(comp)) + 1 <= len(comp) - 1:
cur_8_next_index = comp.index(cur, i, len(comp)) + 1
cur_8_next = comp[cur_8_next_index]
if cur_8_next.count('*') > cur_8:
obj_1 = str(cur).replace("*", '') + "-" + str(cur_8_next).replace("*", '')
print obj_1
if res.has_key(obj_1):
res[obj_1] = res[obj_1] + 1
else:
res[obj_1] = 1
# print 'parent:' + str(cur) + ", left_child:" + str(cur_8_next)
for x in comp[cur_8_next_index + 1:]:
if x.count('*') < cur_8_next.count('*'):
break
if cur_8_next.count('*') == x.count('*'):
obj_2 = str(cur).replace("*", '') + "-" + str(x).replace("*", '')
print obj_2
if res.has_key(obj_2):
res[obj_2] = res[obj_2] + 1
else:
res[obj_2] = 1
# print 'parent:' + str(cur) + ", right_child:" + str(x)
break
i = i + 1
# print res
得到结果如下:
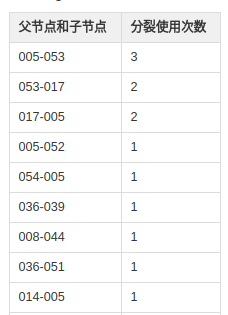
特征005-053组成子树的次数为3次,053-017组成子树的次数为2次,以此类推...
