MySQL表操作
一:增
# 创建表 create table student( id int primary key auto_increment, name varchar(20) unique, text varchar(100), age int,
score int )engine=InnoDB default charset=utf8; --------------------------------分割线--------------------------- #插入数据: insert into student(id, name, text, age) values (1, 'Tom', '让子弹飞', 25) insert into student values(2, 'jack', '滴滴打车', 22) # 选择性插入 insert into student(id, name) values (3, 'Smit') # 批量插入 insert into student values (4, 'zhangsan', '刺客五六七', 23),(5,'lisi','梅花十三',21)......... #set插入: insert into student set id=5,name='肌肉鸡';
#如果突然插入id为5,下次作为主键的增长会以5开始
二:改
格式:update 表 set 字段1=value,字段2=value..... where 条件
update student set name='alice' where name='tom'; # 将name为'tom'的列修改成 'alice'
update student set age+=1 where name='alice'; # 将age增加1
三:删除
格式:delete from 表 [where 条件]
delete from student where name= 'jack'; #将 值为 'jack' 的数据删掉
delete from student;# 删除所有数据,但不是删除表
truncate table student #删除所有数据,不是删除表
四:查
#查询语法格式
select [distinct] *|字段1|字段2|字段3... from 表 where 条件
group by 分组
having 筛选
order by 排序
select 的英文意思是 挑选,挑选字段
from 的意思是 来自,数据的来源(数据来源于哪些表)
distinct 的意思是 独特,特别的。不重复的的数据,用来剔除重复行
* 表示查询所有信息
---------------------------------------分割线-----------------------------------------------------
# 创建测试表
create table student(
id int primary key auto_increment,
name varchar(20) unique,
text varchar(100),
age int,
score int,
hight int
)engine=InnoDB default charset=utf8;
---------------------------------------分割线-----------------------------------------------------
#插入测试数据
insert into student values
(1,'五六七', '刺客五六七',22,88,165),
(2,'tom', '滴滴滴滴',25,70,165),
(3,'梅花十三', '阿珍爱上了阿强',22,70,163),
(4,'许var强', '强人锁男',28,59,169),
(5,'面筋哥', '真正的实惠',28,73,170),
(6,'面筋弟', '辣辣的感觉', 23, 60, 174);
---------------------------------------分割线-----------------------------------------------------
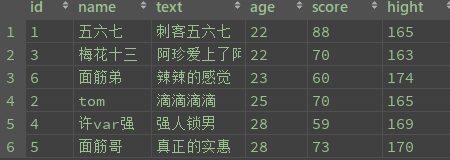
select * from student
结果:
1.where
比较运算符:>、<、>=、<=、 <> 、 != 、
between 20 and 30 值在20到30之间
in (10,30,40) 值是10或者30或者40
like '%' %匹配任意字符,并且不限次数
like '_' 匹配单个字符,一个 _ 只能匹配一次
逻辑运算符:and,or,not
----------------------------------------分割线---------------------------------------
select * from student where name='tom'

select name,score from student where score >70 #搜索分数大于70的学生
![]()
select name,hight from student where hight>165 and hight<170 #搜索身高大于165但又小于170的学生
![]()
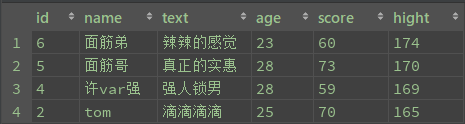
select * from student where name like '面%'
![]()
select * from student where name like '五六_'
![]()
select name,age from student where age between 23 and 28 #搜索年龄在23 - 28的学生
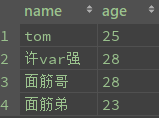
select name,age from student where age in(22,28) #搜索年龄22,28岁的学生
2.Order by (排序)
格式:select *|字段1|字段2 .. from 表 order by [Asc|Desc] # Asc表示升序,Desc表示降序。默认为asc
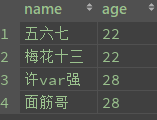
select * from student order by age Asc # 升序
select * from student order by age desc #降序

select * from student where age >22 order by hight desc # 搜索年龄大于22岁的学生,并以身高进行排序
3. group by 分组
#去重
#创建测试表
create table divide(
id int primary key auto_increment,
goods varchar(20),
price int,
ddate DATE,
class varchar(10)
)engine=InnoDB default charset=utf8;
#写入测试数据
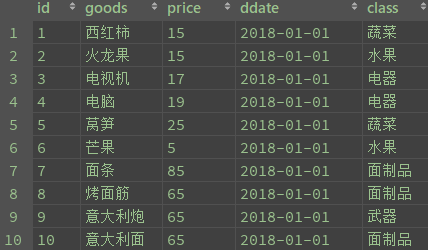
insert into divide values(1,'西红柿', 15,20180101,'蔬菜'),
(2,'火龙果', 15,20180101,'水果'),
(3,'电视机', 17,20180101,'电器'),
(4,'电脑', 19,20180101,'电器'),
(5,'莴笋', 25,20180101,'蔬菜'),
(6,'芒果', 5,20180101,'水果'),
(7,'面条', 85,20180101,'面制品'),
(8,'烤面筋', 65,20180101,'面制品'),
(9,'意大利炮',65,20180101,'武器'),
(10,'意大利面',65, 20180101,'面制品'),
(11,'面包',65,20180101,'面制品');
---------------------------------------------
-------------------------------------------
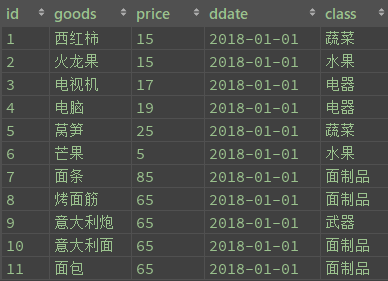
select goods,class from divide group by calss,goods # 将商品按种类进行区分
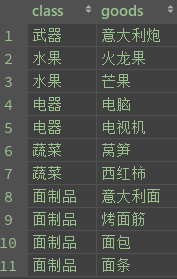
select class, sum(price) from divide group by class # 将每个种类的商品价格进行累加
select class, goods,price from divide group by class, goods,price having price > 25
#将商品按种类分组,然后 having 筛选每组价格大于25的商品

注意:where 与 having都可以对查询结果进行更进一步的过滤。区别在:
1.where 只能在分组之前筛选,having可以在分组之后筛选
2.使用where语句的地方可以用having进行替换
3.聚合函数计算的结果可以当条件来使用,因为它无法放在where里,只能通过having这种方式来解决。
4.聚合函数
#聚合函数是对 根据要求查询得到的数据内容 再进行加工(多数情况下和分组查询配合使用)
#测试数据表:divide
#测试数据:与group by的测试表一样
--------------------------------分割线-----------------------------------------------
1.count(字段):# count不会统计null值
select count(*) from divide #统计值表里的数据有多少行
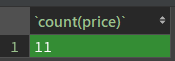
select count(price) from divide where price<25 # 统计价格低于25的商品总数
![]()
select count(class) from divide group by class having sum(price) > 100 #统计同一种类商品的总价超过100的商品数量
![]()
---------------------------------------------分割线----------------------------------------------
2.sum(字段) :将经过筛选后的数据进行累加
select sum(price) from divide # 计算所有商品总价
![]()
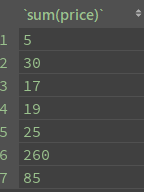
select sum(price) from divide group by price # 计算每个种类的商品总价
select sum(price)/count(*) from divide #计算平均
![]()
----------------------------------------------分割线----------------------------------------------
3.AVG(列名) :计算平均
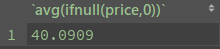
select avg(ifnull(price,0)) from divide #计算每个商品的平均价
4.Max/Min :最大值和最小值
select Max(price) from divide #求最大值
select min(price) from divide #求最小值
5.limit
#避免全表扫描,提高查询效率
#初始偏移量是从0开始的
select * from divide limit 0,10
6.正则
select * from divide where goods regexp '^面' #匹配面字开头
select * from divide where goods regexp '面$' #匹配面字结尾

注意:
select from where group by having order by 的执行顺序
from --> where --> select -- group by --> having --> order by
