

第二次作业-使用Fiddler与python进行爬虫抓取信息
| 这个作业属于哪个课程 | https://edu.cnblogs.com/campus/fzzcxy/ZhichengSoftengineeringPracticeFclass |
|---|---|
| 这个作业要求在哪里 | https://edu.cnblogs.com/campus/fzzcxy/ZhichengSoftengineeringPracticeFclass/homework/12532 |
| 这个作业的目标 | 学会使用fiddler工具、git的使用、以及python下requests包的使用 |
| Gitee 地址 | https://gitee.com/leiwjie/lwj212106766/tree/master/demo1 |
一、使用 fiddler 抓包工具+代码,实时监控朴朴上某产品的详细价格信息
(1)解题思路
-
1、安装Fiddler
-
3、通过各种尝试后决定用mac端微信打开朴朴小程序

-
4、启动Fiddler对朴朴商品进行抓包
-
5、解析包数据拿到想要的json内容

- 6、找到目标地址使用python爬虫进行抓取和数据清洗
(2)设计实现过程
- 1.尝试使用目标地址进行访问连接失败
- 2.去csdn寻找原因最后添加了请求头user-agent连接成功

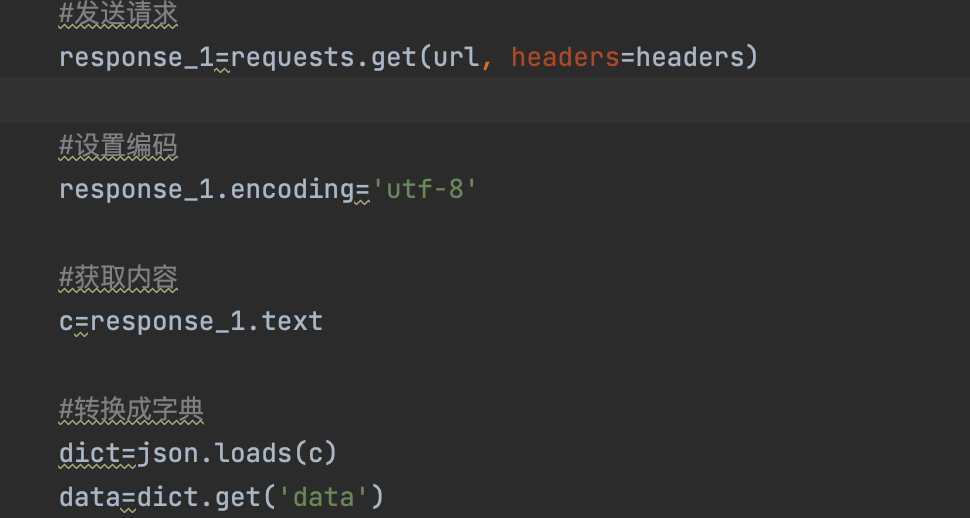
- 3.使用requests包请求数据,将放回的json数据转为字典方便数据提取
- 4.使用time.sleep随机每1分钟抓取一次
- 5.进行数据展示处理
- 6.将请求json数据代码快和延时执行抓取价格分别写进函数
#请求网页
def t1():
#发送请求
response_1=requests.get(url, headers=headers)
#设置编码
response_1.encoding='utf-8'
#获取内容
c=response_1.text
#转换成字典
dict=json.loads(c)
data=dict.get('data')
#商品名
name=data.get('name')
#商品价格
price=int_to_float(data.get('price'))
#规格
spec=data.get('spec')
#原价
market_price=int_to_float(data.get('market_price'))
#详情内容
share_content=data.get('share_content')
#标题
sub_title=data.get('sub_title')
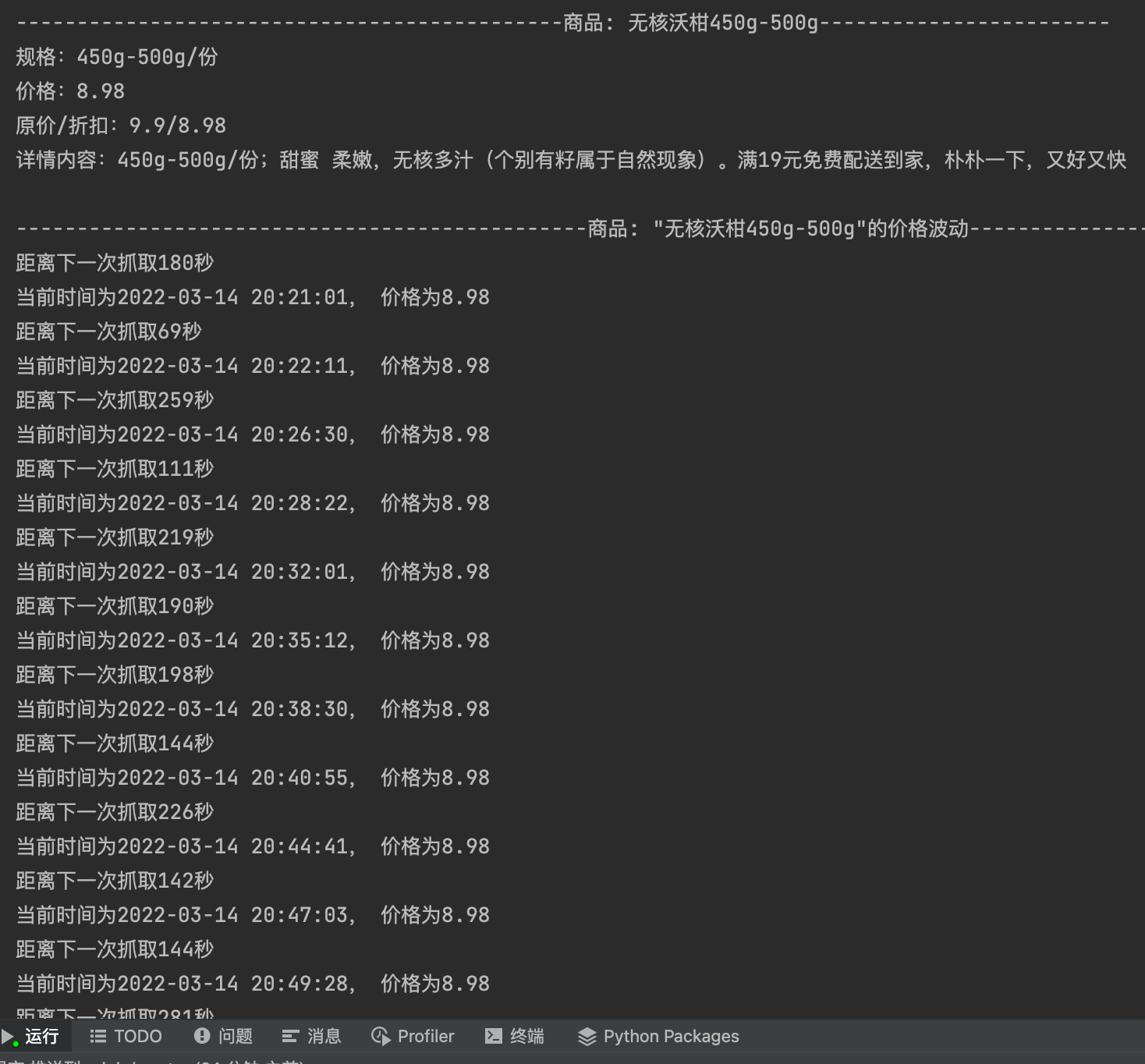
print('---------------------------------------------商品: '+name+'------------------------')
print('规格:'+spec)
print('价格:'+ str(price))
print('原价/折扣:'+str(market_price)+'/'+str(price))
print('详情内容:'+share_content)
print()
print('-----------------------------------------------商品: "'+name+'"的价格波动------------------------')
def t2():
#延时执行
while(1):
t=random.randint(60,300)
print('距离下一次抓取'+str(t)+'秒')
time.sleep(t)
#发送请求
response_1=requests.get(url, headers=headers)
#设置编码
response_1.encoding='utf-8'
#获取内容
c=response_1.text
#转换成字典
dict=json.loads(c)
data=dict.get('data')
#商品价格
price=int_to_float(data.get('price'))
#输出当前价格
print('当前时间为'+time.strftime('%Y-%m-%d %H:%M:%S', time.localtime())+', 价格为'+str(price))
-
7.考虑到会被判定为机器人将间隔时间改为1~5分钟随机抓取
-
8.gitee推送
(3)代码改进
- 1 一开始使用re正则表达式发现繁琐并且抓取的数据有遗漏后来改用json转字典的方法更加方便准确
- 2 自定义随机延时函数来避免被判定为机器人
二、知乎收藏夹的爬取
(1)解题思路
- 1、经过朴朴爬虫的实战让我找到更加熟悉抓取流程,先抓到收藏首页地址经过清洗拿到每个收藏夹的地址
- 2、然后再逐个抓取每个收藏夹下的json数据解析出子目录以及地址
- 3、最后经过处理更美观的展示
(2)设计实现过程
- 1、用Fiddler抓取目标地址
- 2、还是先拿到请求头并且加入了cookies
- 3、设计了请求函数
#发送请求模块
def req(url_):
res = requests.get(url=url_, cookies=data, headers=headers)
res.encoding='utf-8'
c=res.content
soup=BeautifulSoup(c,'lxml')
return soup
- 4、抓取收藏夹模块
#抓取收藏夹
def collect():
collect=req(url).find_all(attrs={'class': 'SelfCollectionItem-title'})
dict_collect={}
for c in collect:
#收藏夹地址id
pattern1=re.compile(r'\d+')
result=pattern1.findall(str(c))
# collectionUrl='https://www.zhihu.com/collection/'+result[0]
collectionUrl='https://www.zhihu.com/api/v4/collections/'+result[0]+'/items?'
#收藏夹名
pattern2=re.compile(r'>.*<')
result2=pattern2.findall(str(c))
strr= result2[0]
lenth=len(strr)
collectName=strr[1:lenth-1]
dict_collect[collectName]=[collectionUrl]
return dict_collect
- 5、抓取收藏夹子目录模块
#抓取收藏夹子目录
def spider_colect(dict):
dict_collect_listt={}
for d in dict :
url1=dict[d][0]
print('-------------------------------name--》'+d+'正在抓取'+'---收藏夹地址:'+url1)
reqst=req(url1).text
js=json.loads(reqst)
result=js['data']
for r in result:
try:
print('=》标题'+r['content']['question']['title'])
print(r['content']['url'])
dict_collect_listt[r['content']['question']['title']]=[r['content']['url']]
except:
print('=》标题'+r['content']['title'])
print(r['content']['url'])
dict_collect_listt[r['content']['title']]=[r['content']['url']]
return dict_collect_listt
-
6、gitee推送

-
7、运行结果展示

(3)代码优化
-
1、本次实验话费最多的时间花费在json数据的解析上查找资料并且学习了python的正则表达式上。
https://blog.csdn.net/weixin_46737755/article/details/113426735?utm_source=app&app_version=5.1.1(正则参考资料)但是其实发现还是用json转字典更容易解决于是又遇到了字典内的titie键有的在外层有的在嵌套字典里于是又重洗查找python字典的详细用法,最后采用了分层拆解的办法得到title的value。最终思路用try except else,代码将在try尝试取值如果出错就进入else进行拆解取值成功。
三、使用 fiddler 抓包工具+代码,抓取拉勾网岗位信息
(1)解题思路
- 1、利用fiddler抓包发现找不到想要的json数据
- 2、改变思路直接抓取html页面
- 3、通过对比发现网址上带有一些信息如城市、岗位名称、页码等,让后利用这个规则构造请求链接
url='https://www.lagou.com/wn/jobs?&gm='+peple_num+'%E4%BA%BA&kd='+job_name+'&city='+city+'&pn='+page
- 4、将抓取的html页面进行正则分每一块都包含一条招聘信息的完整记录
- 5、进行第二轮清洗将数据存入字典
- 6、把字典里的数据迭代写入xls表格
在这里接触到了一个新的python包xlwt(python表格操作包)于是参考了以下链接学习xlwt的基本使用
https://blog.csdn.net/Tulaimes/article/details/71172778?ops_request_misc=%257B%2522request%255Fid%2522%253A%2522164744988216780255285169%2522%252C%2522scm%2522%253A%252220140713.130102334..%2522%257D&request_id=164744988216780255285169&biz_id=0&utm_medium=distribute.pc_search_result.none-task-blog-2
(2)设计实现过程
- 1、构造请求头和cookies
head={
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/99.0.4844.74 Safari/537.36'
}
data={'user_trace_token':'20220316184137-7e2191a5-bdcd-4d99-9d9e-593a312df9f9',
' Hm_lvt_4233e74dff0ae5bd0a3d81c6ccf756e6':'1647427299',
' _ga':'GA1.2.314814173.1647427299',
' LGSID':'20220316184139-482d4935-1bdb-457f-913d-204ebf655b27',
' PRE_UTM':'m_cf_cpt_baidu_pcbt',
' PRE_HOST':'www.baidu.com',
' PRE_SITE':'https%3A%2F%2Fwww.baidu.com%2Fother.php%3Fsc.K00000jKkk4BUEVK7Jnma2u%5F4LTL8IEzeQEQtJbLWN1r-x4hD9n1bNIVC-vkTG-rptNe2a4dmBnbGfnMG22Hmn94tQWJelSAuO83NNpORsZADblTEwwoh77V-kRTHbY0pbEVmNMasfzbHhyJYGnnV26R7mrqqSmu8zSmfuvqz2uWcUTp-GZI8j2OBR3mtiIn9pcTQPxVpFEO98vsAz3KQ%5FWZu8xV.7Y%5FNR2Ar5Od663rj6tJQrGvKD77h24SU5WudF6ksswGuh9J4qt7jHzk8sHfGmYt%5FrE-9kYryqM764TTPqKi%5FnYQZHuukL0.TLFWgv-b5HDkrfK1ThPGujYknHb0THY0IAYqs2v4VnL30ZN1ugFxIZ-suHYs0A7bgLw4TARqnsKLULFb5TaV8UHPS0KzmLmqnfKdThkxpyfqnHR1n1mYPjc3r0KVINqGujYkPjmzPWnknfKVgv-b5HDkn1c1nj6d0AdYTAkxpyfqnHczP1n0TZuxpyfqn0KGuAnqiD4a0ZKGujYd0APGujY3nfKWThnqPHm3%26ck%3D2743.1.116.297.155.276.150.402%26dt%3D1647427292%26wd%3D%25E6%258B%2589%25E5%258B%25BE%25E7%25BD%2591%26tpl%3Dtpl%5F12273%5F25897%5F22126%26l%3D1533644288%26us%3DlinkName%253D%2525E6%2525A0%252587%2525E9%2525A2%252598-%2525E4%2525B8%2525BB%2525E6%2525A0%252587%2525E9%2525A2%252598%2526linkText%253D%2525E3%252580%252590%2525E6%25258B%252589%2525E5%25258B%2525BE%2525E6%25258B%25259B%2525E8%252581%252598%2525E3%252580%252591%2525E5%2525AE%252598%2525E6%252596%2525B9%2525E7%2525BD%252591%2525E7%2525AB%252599%252520-%252520%2525E4%2525BA%252592%2525E8%252581%252594%2525E7%2525BD%252591%2525E9%2525AB%252598%2525E8%252596%2525AA%2525E5%2525A5%2525BD%2525E5%2525B7%2525A5%2525E4%2525BD%25259C%2525EF%2525BC%25258C%2525E4%2525B8%25258A%2525E6%25258B%252589%2525E5%25258B%2525BE%21%2526linkType%253D; PRE_LAND=https%3A%2F%2Fwww.lagou.com%2Flanding-page%2Fpc%2Fsearch.html%3Futm%5Fsource%3Dm%5Fcf%5Fcpt%5Fbaidu%5Fpcbt; LGUID=20220316184139-e6e5080c-e420-4df8-92f4-942d3b9b946c; gate_login_token=58774caede3acc16b832c73b85d4e05d24365577f5526d4008c2bb9412f5bada; LG_HAS_LOGIN=1; _putrc=56B90E54AF51838F123F89F2B170EADC; JSESSIONID=ABAAAECABIEACCAA67549DE5F161F2B8C75812BF3C79350; login=true; hasDeliver=0; privacyPolicyPopup=false; WEBTJ-ID=20220316184221-17f92524d2037c-054e030a41bb48-133a645d-1024000-17f92524d21636; sajssdk_2015_cross_new_user=1; sensorsdata2015session=%7B%7D; unick=%E9%9B%B7%E6%96%87%E5%80%9F; RECOMMEND_TIP=true; X_HTTP_TOKEN=6b4be9b874e5d4336057247461903bbf6b0a117cf0; _gid=GA1.2.485582894.1647427507; Hm_lpvt_4233e74dff0ae5bd0a3d81c6ccf756e6=1647427507; __SAFETY_CLOSE_TIME__24085628=1; TG-TRACK-CODE=index_navigation; LGRID=20220316184511-d4561436-ee26-4eec-95c0-83119d3af5ef; __lg_stoken__=ccc62399cc29a776c7d7a874bb4350736bdc3d6c8e3409692978f5ae85315148b7725b924ec6c44bdac2b6aa84fcdab13be9ab320ec4eff7b498313e6cc527f6fb43a7a73fdb; sensorsdata2015jssdkcross=%7B%22distinct_id%22%3A%2224085628%22%2C%22first_id%22%3A%2217f92524e0f6ea-000aca07f2b8ba-133a645d-1024000-17f92524e10c6d%22%2C%22props%22%3A%7B%22%24latest_traffic_source_type%22%3A%22%E7%9B%B4%E6%8E%A5%E6%B5%81%E9%87%8F%22%2C%22%24latest_search_keyword%22%3A%22%E6%9C%AA%E5%8F%96%E5%88%B0%E5%80%BC_%E7%9B%B4%E6%8E%A5%E6%89%93%E5%BC%80%22%2C%22%24latest_referrer%22%3A%22%22%2C%22%24os%22%3A%22MacOS%22%2C%22%24browser%22%3A%22Chrome%22%2C%22%24browser_version%22%3A%2299.0.4844.74%22%7D%2C%22%24device_id%22%3A%2217f92524e0f6ea-000aca07f2b8ba-133a645d-1024000-17f92524e10c6d%22%7D'
}
- 2、请求数据模块
#发送请求
def post_value(city,job_name,peple_num,page):
url='https://www.lagou.com/wn/jobs?&gm='+peple_num+'%E4%BA%BA&kd='+job_name+'&city='+city+'&pn='+page
req=requests.post(url,cookies=data,headers=head)
req.encoding='utf-8'
c=req.content
soup=BeautifulSoup(c,'lxml')
return soup
- 3、数据清洗模块
#清洗数据
def data_clear(city,job,num,page):
dict={}
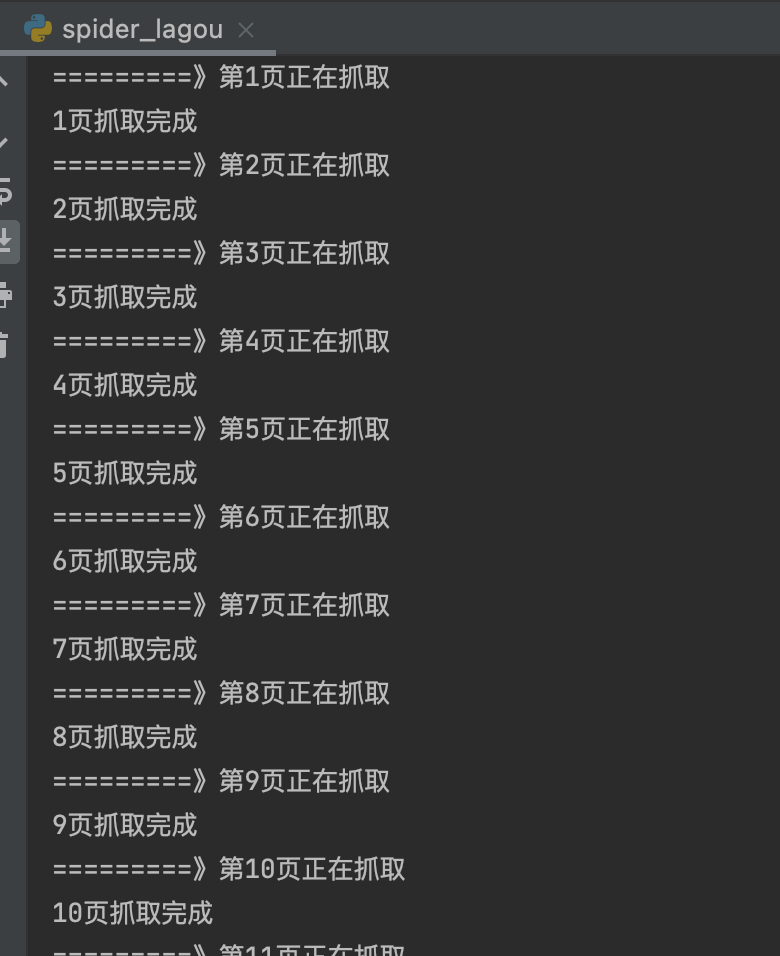
for i in range(1,page+1):
data=post_value(city,job,num,str(i))
print('=========》第'+str(i)+'页正在抓取')
regex='排序方式.*推荐公司'
regex2='p-top__1F7CL.*?p-top__1F7CL'
pattern=re.compile(regex)
result=pattern.findall(str(data))
pattern=re.compile(regex2)
result=pattern.findall(str(result))
for l in result:
li=[]
regex_name_city_company='<a>.*?</a>'
regex_money='money__3Lkgq.*?</div>'
regex='>.*?<'
pattern=re.compile(regex_name_city_company)
resul_name_city_company=pattern.findall(str(l))
# print(resul_name_city_company)
pattern2=re.compile(regex_money)
resul_money=pattern2.findall(str(l))
#价格
money=str(resul_money)[16:23]
regex_money2='\d.*-\d.*k'
pattern3=re.compile(regex_money2)
money=pattern3.findall(money)[0]
# print(money)
#职位\区域\公司名称
pattern=re.compile(regex)
resul=pattern.findall(str(resul_name_city_company))
for k in range(5):
if(k==0):
li.append(resul[0][1:len(str(resul[0]))-1])
elif (k==1):
li.append(resul[1][1:len(str(resul[1]))-1])
elif (k==3):
li.append(resul[3][1:len(str(resul[3]))-1])
li.append(city)
li.append(job)
li.append(num)
dict[money]=li
print(str(i)+'页抓取完成')
time.sleep(random.randint(5,10))
return dict
- 4、xls写入模块
def io_xls(dict: object):
# 创建一个workbook对象
book = xlwt.Workbook(encoding='utf-8',style_compression=0)
# 创建一个sheet对象,相当于创建一个sheet页
sheet = book.add_sheet('test_sheet',cell_overwrite_ok=True)
d=0
sheet.write(0,0,'城市')
sheet.write(0,1,'岗位类型')
sheet.write(0,2,'公司人数')
sheet.write(0,3,'公司名称')
sheet.write(0,4,'公司招收岗位')
sheet.write(0,5,'薪资范畴')
sheet.write(0,6,'城区')
for a in dict:
sheet.write(d+1,1,dict[a][4])
sheet.write(d+1,0,dict[a][3])
sheet.write(d+1,2,dict[a][5])
sheet.write(d+1,3,dict[a][2])
sheet.write(d+1,4,dict[a][0])
sheet.write(d+1,5,str(a))
sheet.write(d+1,6,dict[a][1])
d=d+1
book.save('data.xls')
- 4、git推送

- 5、运行演示抓取后的数据在当前文件夹下生成xls表格保存

(3)代码优化
- 1、请求的url由手动复制改成自动生成
- 2、正则的提取总是经常匹配多余内容,后来添加了非贪婪匹配
