
python爬虫基础
1 什么是爬虫
请求网站, 并提取数据的自动化程序.
2 爬虫基本流程
2.1 发起请求
请求,一般通过http库, 对目标站定进行请求,等同于自己打开浏览器,输入网址.
2.2 获取响应
服务器接受到来自客户端的请求后, 根据请求进行处理, 然后返回请求的内容, 一般为: HTML, 二进制文件(视频,音频), 文档, Json字符串等.
2.3 解析内容
解析内容: 对用户而言,就是寻找自己需要的信息. 对于爬虫而言,就是利用正则表达式或者其他库/框架提取目标信息.
2.4 保存数据
将解析的数据(可以是多种形式, 文本,音频, 视频等)保存到本地.
如下图所示:

3 请求与响应
爬虫最主要的一个环节就是发起请求(Request),然后获取服务器的响应(Response)。

3.1 Request所包含的信息
爬虫第一步就是发起请求, 请求包含如下内容:
- 请求方式: 主要有GET,POST两种类型,另外还有HEAD,PUT,DELETE,OPTIONS等。
GET特点:请求的参数全部包含在请求的网址内。
POST特点: 需要构造Form Data才能发起请求 - 请求URL:URL的全名是统一资源定位符。网络上的一切资源都是位于服务器的某一个位置,而URL就是告知浏览器去哪里获取这些资源。
- 请求头:请求头(header)就是告诉服务器你是谁,包括User-gaget,Host,Cookies等信息。添加请求头信息,保证请求合法
- 请求体:请求时包含的额外数据,如POST请求需要输入的表单数据,一般用于模拟登陆。
- 请求包含内容如下图所示:
![]()

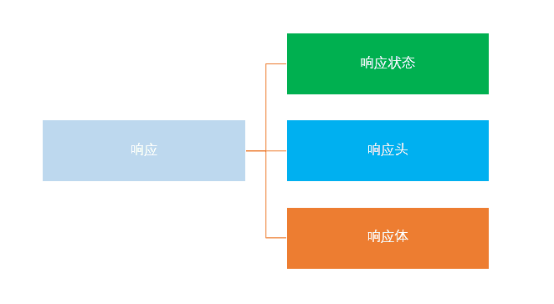
3.2 Response所包含的信息
向服务器发出请求后,不出意外,服务器就会返回一个响应(response)。包括如下内容:
- 响应状态:用于表示请求的结果,如200代表成功,404找不到页面,502服务器错误等。
- 响应头 :如内容类型,内容长度,服务器信息,设置Cookie等等
- 响应体就是网页源代码,也就是用于解析数据的部分。
访问网页遇到的第一个文件一般都是document形式,都是网页源代码。然后解析内部的超链接,继续发起请求。 - 响应内容如下所示:
3.3 一个简单的例子
# 导入请求库 import requests
# 请求网页
response = requests.get('http://www.baidu.com')
# 查看响应体内容
print(response.text)
print(response.content)
print(response.headers)
print(response.status_code)
4 能够抓取的数据
只要是网页上可以看到的内容,不出意外都是可以抓取的。但是能不能抓得到很大程度上取决于你的爬虫水平。
- 网页文本: 如HTML文档,Json格式文本等
- 图片: 获取的都是二进制文件,如果保存为图片格式
- 视频: 也是也二进制文件,保存为视频格式
- 其他 : 只要你能请求到,就能获取到

5 网页解析
网页解析有如下的几种方式:
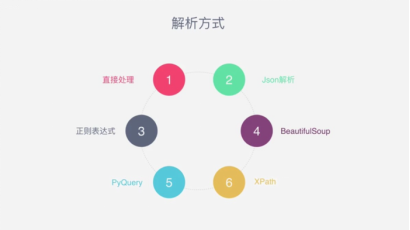
5.1解析网页会遇到的问题
抓到的数据和浏览器看到的不一样
element看到的网页的源代码已经经过修饰,数据来自后台端口
浏览器运行JS,后台请求加载,
如何解决JavaScript渲染问题
- 分析Ajax请求
- selenium/webdriver
- Splash
- PyV8、Ghost.py
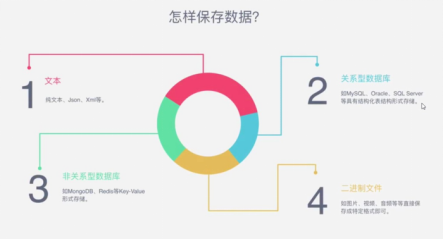
6 数据保存
抓取到的数据可以按如下几种方式保存到本地
7 python爬取网易云音乐热门50单曲实战
爬取网易云音乐 五月天 热门50单曲 :
#!usr/bin/env python
# coding:utf-8
"""
@author:Administrator
@file: wyMusic.py
@time: 2018/04/26
"""
from urllib.request import urlretrieve
from bs4 import BeautifulSoup
import requests
import json
import re
def get_html(url):
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.181 Safari/537.36',
'Referer': 'http://music.163.com/',
'Host': 'music.163.com'
}
# tencent-> referer.
try:
res = requests.get(url, headers=headers)
# with open('html.txt', 'w', encoding='utf-8') as fp:
# fp.write(res.text)
return res.text
except Exception as e:
print(e)
print('request error')
pass
def get_singer_info(html):
soup = BeautifulSoup(html, 'lxml')
links = soup.find('ul', class_='f-hide').find_all('a')
song_ids = []
song_names = []
for link in links:
song_id = link.get('href').split('=')[-1]
song_name = link.get_text()
song_ids.append(song_id)
song_names.append(song_name)
return zip(song_ids, song_names)
def get_lyric(song_id):
url = 'http://music.163.com/api/song/lyric?' + 'id=' + str(song_id) + '&lv=1&kv=1&tv=-1'
html = get_html(url)
json_obj = json.loads(html)
initial_lyric = json_obj['lrc']['lyric']
regex = re.compile(r'\[.*\]')
final_lyric = re.sub(regex, '', initial_lyric).strip()
return final_lyric
def write_lyric(song_name, lyric):
with open('lyrics\\{}.txt'.format(song_name.replace("/", '')), 'w', encoding='utf-8') as fp:
fp.write(lyric)
def download_song(song_name, song_id):
singer_url = 'http://music.163.com/song/media/outer/url?id={}.mp3'.format(song_id)
urlretrieve(singer_url, 'song\\{}.mp3'.format(song_name.replace("/", '')))
if __name__ == '__main__':
# singer_id = '13193'
singer_id = '94779'
# http://music.163.com/song/media/outer/url?id=436514312.mp3
start_url = 'http://music.163.com/artist?id={}'.format(singer_id)
html = get_html(start_url)
singer_infos = get_singer_info(html)
for song_id, song_name in singer_infos:
print("downloading......", song_id, song_name)
lyric = get_lyric(song_id)
write_lyric(song_name, lyric)
download_song(song_name, song_id)
print('done')
# download_song('believer', "523030374")

 浙公网安备 33010602011771号
浙公网安备 33010602011771号