
聊聊字节序
字节序问题的产生:人的习惯的差异。
首先了解不变的两点:
1.计算机使用内存通常都是从低地址开始使用,向高地址生长(函数局部变量使用的栈内存从高地址向低地址生长,但是在不考虑编译器优化的场景下同一个结构体的各成员还是按照代码的定义顺序从低地址向高地址依次占用内存;同样具有MAX个成员的数组arrary[ MAX ],也是arrary[0]占用低地址内存,arrary[ MAX -1 ]占用高地址内存);
2.如果一块内存占用多个字节,无论何种字节序的机器,都使用最低地址表示这个内存块的地址;比如下图定义一个uint32类型的占四个字节的变量,计算机通常用0x7ffe82259fb0而不是0x7ffe82259fb3表示这个变量的地址。

图1 unit32类型0x01020304在各字节序设备中的内存排布
大端序的产生:
大端序的产生源于人们的书写规则,如对于4字节的数值0x01020304,我们在书写这个数值时从高字节向低字节依次书写;注意到上述提到的第1点——计算机都是从低地址向高地址使用内存,很自然地在计算机中从低地址向高地址按书写顺序依次保存数值的高字节到低字节,如下图所示。
Tips:网络字节序采用大端序。
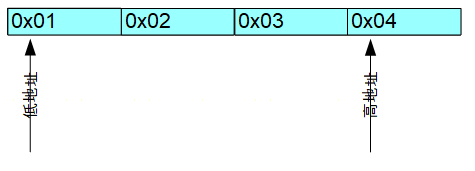
图2 unit32类型0x01020304在大端序设备中的内存排布
小端序的产生:
小端序源于“数位”与内存排布的一致,对于十进制数我们称其不同的“数位”为个位、十位、百位等;常用的十六进制表示中,虽无数位的概念,但有高低字节的区分;数值的高低字节与内存的高低地址分别对应也是很自然的数据保存方法,如图1右半部分。
为什么叫大端序/小端序:
现在我们知道了有“大端序”和“小端序”两个概念,也知道了有按书写顺序保存和按“数位”与内存排布一致保存两种方式;但是很长时间以后这两个概念和两种保存方式的对应关系很容易混淆。
有没有好的助记方法能保证两者不混淆呢?只要弄清了大端序和小端序名称的由来自然不会混淆。本文开始的第2点提到所有机器都是使用变量占用的最低字节地址表示变量的地址,可以看出变量地址保存了变量最高字节(大端)的方式叫作大端序,变量地址保存变量最低字节(小端)的方式叫作小端序;因此只要看变量地址保存的是变量的大端还是小端就知道是大端序还是小端序了。
字节序使用场景示例:
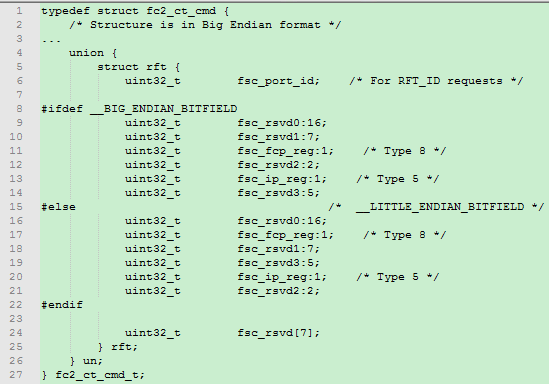
图3和图4分别是FC协议中一种帧类型RFT_ID的payload部分的结构体定义(省略preamble部分的4个word)以及结构体成员的内存排布,每行表示4个字节的32 bit的word,地址增长方向如图所示(注意:单个字节内bit0在右,bit7在左)。
通常的X86系统采用小端序,在图3中采用16—21行的位域定义。图3的line6对应图4中的第5个word;line16定义的预留字段fsc_rsvd0占16个bit,刚好占用两个字节;
line17定义的fsc_fcp_reg占用下个字节的bit0,line18定义的预留字段fsc_rsvd1占7个bit,占同个字节的bit1—bit7。
line19定义的预留字段fsc_rsvd3占5bit,占用下个字节的bit0—bit4;line20定义的fsc_ip_reg占同字节的bit5,line21定义的fsc_rsvd2占同字节的bit6—bit7。
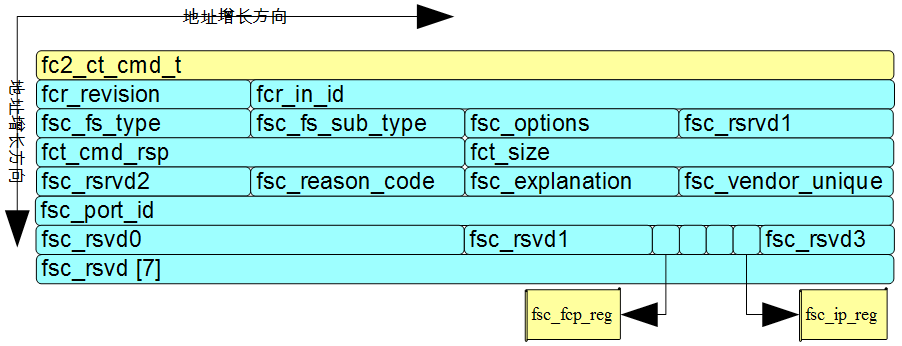

对比图4和图5,可以清晰的看出图5的line891所填充的结构体成员fsc_fcp_reg位于payload的什么位置:fsc_fcp_reg位于倒数第二个word的bit8处,置1表示支持TYPE 8(SCSI FCP)。
图5中的line890用于将iop->iop_nport_id的值转换为大端序后保存到payload结构体的成员fcs_port_id中;如果iop->iop_nport_id的值为0x010203,则字节序转换后,被赋值的payload结构体成员fcs_port_id的值为0x03020100,但没关系:该成员并非供x86系统使用。
我们关心的是结构体成员fcs_port_id的值0x03020100在内存中的排布而非值本身。由于x86系统采用小端序,因此图4中倒数第3个word的从左(低)到右(高)的4个字节分别保存0x00,0x01,0x02,0x03。该内存空间将被用于DMA传输,芯片从内存低地址向高地址依次取数据,依次发送0x00,0x01,0x02,0x03四个字节,按网络字节序解析传输的值就是0x010203,即将图5中line 890右侧iop->iop_nport_id的值正确的传输出去。

