
程序员五年小结
我可能是个假程序员,居然喜欢写文档。。。
这篇总结要追溯到刚毕业参加工作时的首位导师我光哥,除带我上手工作之外还一直灌输、强调阶段总结的重要性;虽然当时没有有效地进行过几次总结,潜移默化也有了有必要进行一下总结的意识。四年后终于用个把月的空闲时间凑了篇不太像样的总结出来。从2013年毕业转眼工作接近5年,在小整年的时间节点做个小结,就当为日复一日的工作加点仪式感吧。很多给新入职程序员的建议中都提到构建自己的知识体系; 具体怎么构建,工作中有哪些提升个人以及团队效率的方法,总结中都有小部分涉及。如果能对新入坑的程序员同行们有点帮助,也算这篇小结有点额外价值了。
1.怎样看代码
代码并不是像小说一样从头到尾顺序写下来的,小说也有倒叙、插叙,但是你从第一个页看到最后一页总能看懂;但是多数代码并不是从第一行看到最后一行就一定能啃下来的,以现在的软件规模也不现实。此外,上下文的衔接也是一个令人头疼的问题:工作中你所要负责的代码通常要耗费一周或者几周的时间才能初步有所理解。如果没有一种很好的方法记录下分析代码的进展,每次分析都从头开始就会重复阅读开始的一部分代码而进展缓慢;在代码分析过程中还涉及到大量相互关联、错综复杂的数据结构:如一些变量的初始化和真正使用并不在一个阶段里面,真正使用的时候早已忘了这个变量被初始化成什么值,这时候再去翻初始化的代码非常耗时,还有可能翻到了初始化的部分又忘记了当前进展。
根据上面两段提出的问题也就知道了高效阅读代码的两个关键点:一是理清逻辑框架;二是做好代码记录。
理清逻辑框架首先要了解代码和处理逻辑分为几个阶段,再把每个阶段的入口拎出来。完成这两步对于负责的模块就了解了一半;剩下的无非就是了解每个阶段的实现细节,理解有快有慢但总有一天会熟悉。像考古一样阅读代码——先用铁锹挖去周边的泥土露出文物的轮廓,再用铲子清理露出文物的表面,最后用毛刷去除尘土露出文物的纹理。对于逻辑框架的理解可以通过老员工讲解、模块文档、芯片手册、概要设计等方式获取,对于驱动软件开发一般的芯片手册会有对芯片使用场景的介绍或者demo代码,可以了解大致的流程。
做好代码记录建议建立两个图,一个是代码执行顺序/调用关系图,一个是数据结构组织图。相信不少人对记录代码执行顺序/调用关系做过尝试,如下图(仅用作示意,看不清内容不必纠结)是以前采用的一种方式,优点是能够清晰的展现出一些流程分支等逻辑细节,缺点是这种方式画图每粘贴一次函数就需要添加一个方框和连接线,非常耗时,信息密度(一个作图页面能记录的内容)也很低。

个人习惯用libreoffice draw记录代码执行顺序/调用关系:自上而下表示顺序执行,通过缩进表示调用关系,缩进层次过深时在右边另起一个区域。遇到函数指针时,在同一级缩进下用注释符号”//”记录实际执行的函数,如下图红色矩形框标注的部分。
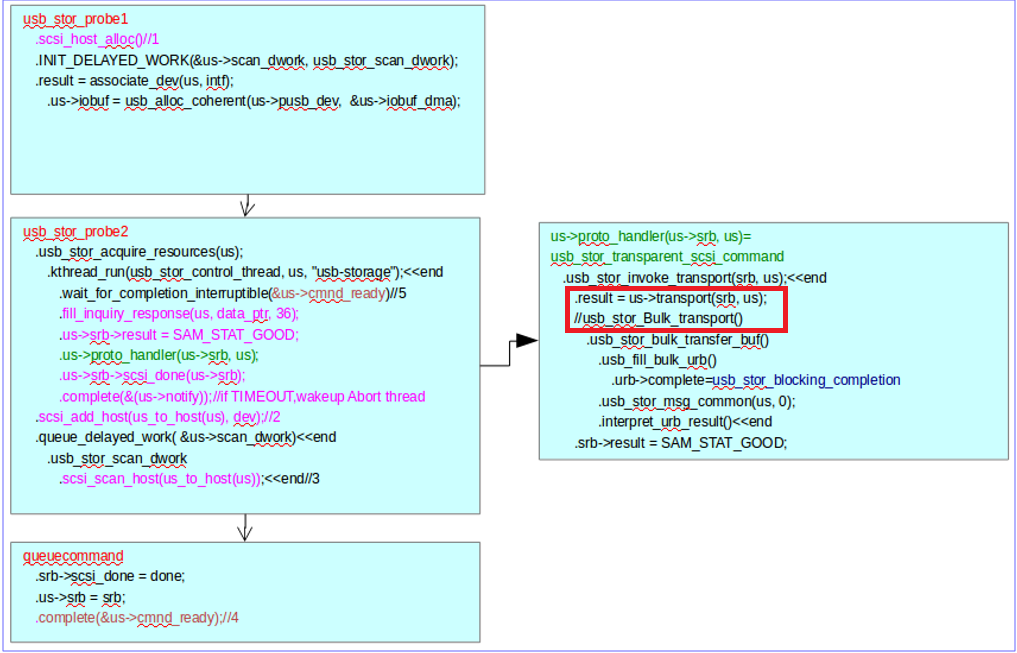
这种方式可以将代码的框架结构、阶段划分、调用关系以及变量(如函数指针等)取值都能清晰的表现出来;其次信息密度较高,通常一个模块仅包含几个主要流程,每个流程用一个框图就能将关键信息展示出来,且可以随时添加关键信息,显著提升阅读代码效率。此外,在团队分享中,可以以此作为代码逻辑地图向其他团队成员介绍你所了解的模块的处理逻辑,同事既能够了解大致流程、又可以根据图中等关键入口函数自己深入分析,可以极大提高团队内知识传递的效率。
C语言代码阅读的一大难点是存在各种各样的函数指针。比如初始化流程中为某个结构体中的函数指针赋值,很有可能在后续在另起的线程中将结构体当做任务节点进行处理时才会通过函数指针调用具体的函数。如果对代码不熟又缺乏相应文档,只通过正向分析很难将初始化和函数的具体使用两个流程关联起来。
这种情况下可以以函数指针为切入点,一方面通过函数调用关系图逐级记录函数的反向调用关系,追溯代码流程,另一方面继续分析函数的实现细节。通过反向分析找到这个函数被谁使用,通过具体函数的实现正向分析分析这个函数干什么用,快速穿起整个流程,对于新模块快速上手、分析不熟悉的问题很有帮助。
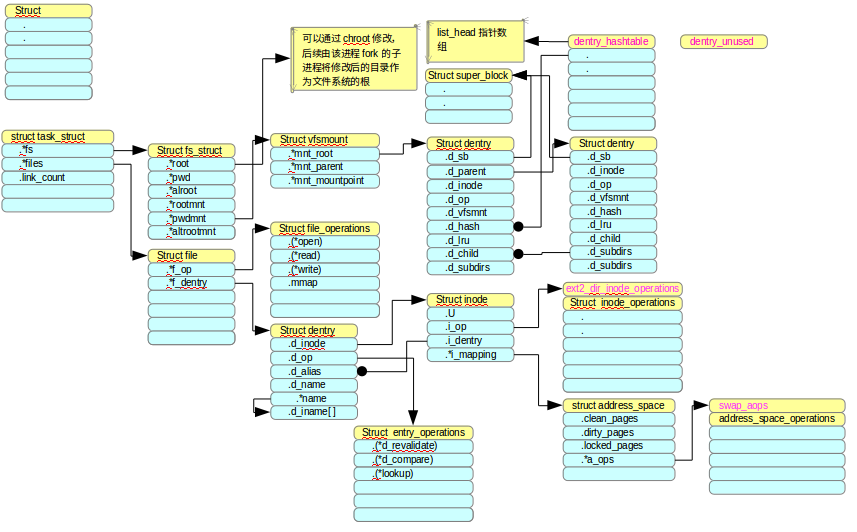
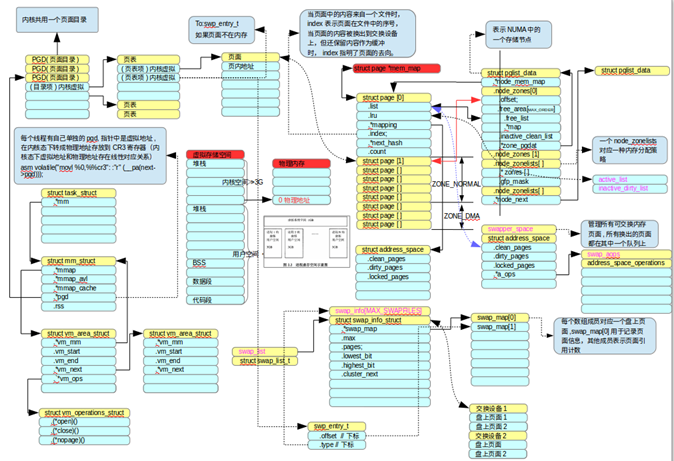
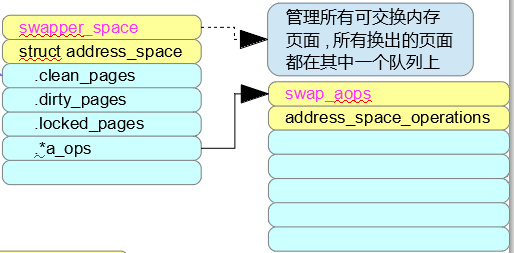
阅读代码时通常遇到函数一层层调用,参数一次次传递;在分析最内层函数时早已忘记函数参数的指代对象是什么。数据组织结构图可以快速帮助找到函数参数的指代对象,并形成整个软件结构的整体认识。一个数据组织结构图示例如下图所示,一些重要的数据成员可以添加注释,一些全局变量可以重点标注,帮助理解。
数据组织结构图示例1----文件系统:
数据组织结构图示例2----内存管理:
2.效率提升(个人部分)
工欲善其事必先利其器,好的工具可以起到事半功倍的效果,个人常用的能够显著提高效率的工具主要有git、libreoffice draw、tasksteper、notepad++、正则表达式、有道云、快速验证方法(7-ZIP、环境变量控制分支等)等,以下是个人的使用心得:
2.1利用git构建自己的知识库
生活中利用视频APP追剧,再次打开时自动从上次看到的地方开始播放;利用kindle看书,再次打开kindle可以接着上次的章节继续阅读,这些不起眼的小特性给我们带来了很大便利。有没有一种工具可以保存手头的工作(比如文档撰写),在下次打开以后能够继续上次未完成的地方继续呢?答案是:有的!Git!!
Git是一个开源的分布式版本控制系统,设计之初是为了管理linux的源代码。除源代码外日常的一些文档资料、技术书籍等也可以使用git来保存管理,逐步完善自己的知识库;因此Git的使用受众已经大大超出了程序员的范畴,在其他一些行业的从业者中也广受欢迎。
比如可以用git来管理随手记。可能很多人每隔一段时间都想好好总结一下,但是通常要么一直在构思,没有落到纸面上;要么开始写了但是一鼓作气没完成,后面就会不知道丢到哪去再也找不回来了。Git的优点在于记录当前进展和多台设备同步,这样有灵感的时候记录的一些琐碎的事务、杂乱无章的随手记,心血来潮的时候整理一点,随手push一下;到另外一台设备上pull一下就是上次终结的地方,修改完后再随手push一下。慢慢会形成一篇像模像样的东西。比如这篇个人总结就是用了很长的时间,利用git靠一些零零散散的东西堆出来的。
再比如可以用git来管理浏览器书签。为了方便,工作中一些常用的网站通常会保存到浏览器书签中。每次重装电脑、更换电脑、创建新的虚拟机时怎样找回这些网站是一个令人头疼的问题----很多浏览器都提供了账号登录后的书签保存和同步功能。但chrome等浏览器的账号登录在国内不可用,此时就可以定期导出书签备份到github中,重装、更换电脑后从github下载最新的书签文件导入浏览器即可。从个人使用经验来看几周才需要利用git备份一次,并不会耗费太多时间。
最好创建一个自己的小项目并使用git进行维护,尝试一下git push、git pull、git log、git merge、创建分支、版本回退等常用功能。
Git相关教程可以自行搜索“git 廖雪峰”,这是我目前发现的最好的git零基础入门教程,详细地址为:
https://www.liaoxuefeng.com/wiki/0013739516305929606dd18361248578c67b8067c8c017b000
2.2利用 Libreoffice draw帮助加速理解代码流程和数据结构组织
上文展示的两张图——代码执行顺序/调用关系图和是数据结构组织图——都是利用libreoffice draw画的。
代码执行顺序/调用关系图中主要用到的就是一个大矩形,在常用的画图工具(visio,libreoffice draw等)都有现成的组件。在矩形中粘贴关键代码进行记录即可,粘帖的代码遵循一些规则:
1)通过3个空格的缩进表示调用关系,同一级缩进自上而下的代码表示顺序执行。缩进时利用“.”表示正向调用,“-”表示反向调用;缩进层次过深时在右边另起一个矩形区域。反向调用关系在根据日志记录的错误追溯问题源头的时候非常好用,特别是对模块的处理逻辑还不熟悉的时候。
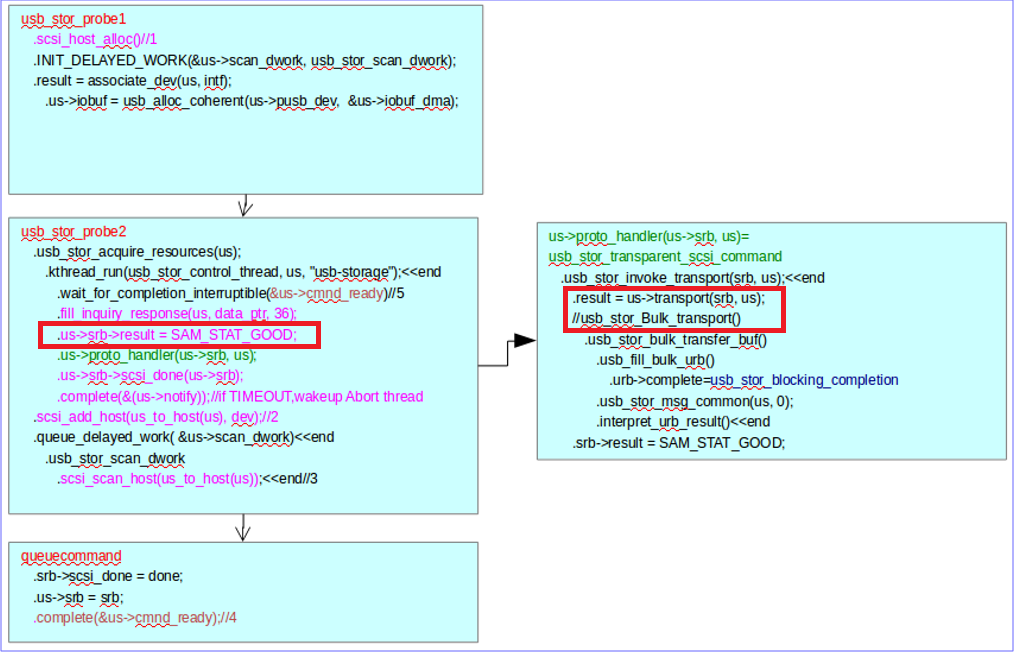
2)一些重要成员的赋值记录下来,比如状态机状态赋值;再比如下图中的usb->srb->result;这样在用到这些变量等时候可以清晰的看出这些关键变量在什么地方被置为什么值,不用再返回去到处翻代码。
3)利用“//”表示对函数指针的解释,比如下图中的us->transport(srb,us)实际调用的函数是usb_stor_Bulk_transport()
4)重要的部分(下图方框所示)可以用颜色标注、或者添加注释等,长时间之后再次阅读代码时方便理解。
数据结构组织图使用多个矩形或者圆角矩形组成结构体,结构体内部通过缩进表示结构体成员的包含关系,多个结构体之间用连接线(也是Visio、libreoffice draw等工具的现有组件)连接,表示关联关系。利用结构体定义的全局变量名可以放在结构体头部,用紫色字体表示。此外还可以添加注释,表明结构体的作用等。
还可以利用这种结构来画有限状态机:用一组圆角矩形表示一个状态,顶部的黄色矩形表示状态名称,底部表示触发条件。连接线指向触发后的下个状态,利用这种方法展示有限状态机再也不会因为版面上触发条件相互重叠导致状态机看起来一团糟了。

2.3利用 Libreoffice draw模板快速画流程图、组网图
工作中经常需要画各种流程图、组网图等,用于加深理解代码逻辑,帮助分析问题以及向别人表明自己给出的问题处理方案等。以流程图为例,通常利用visio/Libreoffice draw等工具画流程图通常需要寻找适合的组件(流程起始、过程、判断等)、调整背景颜色、字体大小、添加文本并放置到合适的位置(如下图的Y/N)等,通常画完一个稍微简单的流程图需耗费15—30分钟。
但如果保存一个visio/libreoffice draw文件作为画图模板,在画流程图的分支时只需要复制粘贴下图中红框部分,对判断条件略加修改即可。利用这些拼凑流程图,基本一个简单的流程图可以在3分钟左右完成。

分析客户问题或者给出解决方案时,通常需要利用组网图来帮助描述客户现场的设备连接情况。常见的设备无非整机、控制器、卡、端口、连线等;把这些保存到组网图的画图模板中,画新的组网图的时候直接复制黏贴需要的组件,可以极大提高效率。下面四幅图中,以图1为模板,另外三幅图可以在几分钟内快速完成。




2.4开发过程中的快速测试
2.4.1 利用7-ZIP替换设备压缩包中的文件进行快速测试
开发过程中新功能、修改的问题都需要自测,而一些测试需要的前期准备过多,可能造成修改一行代码花费一天测试。不排除有些修改的确需要大量时间验证,有些则不需要——如果你的修改是嵌入到某个流程中,并且影响只影响流程的一个环节,则完全可以想办法进行局部验证。
以硬件的固件升级为例,业界惯用的方法是发布的软件包中放置版本号记录文件(记录期望版本号)和二进制固件文件,在系统启动初期从硬件中读取实际版本号,并与记录文件中的期望版本号进行对比,若二者不一致则利用二进制固件文件对硬件进行升级。
如果发布了新的固件,通常的验证方法是:
-
修改源码中版本号记录文件中的期望版本号为新固件版本号;
-
更新源码中的二进制固件文件;
-
将源码编译、打包成系统软件包;
-
将系统软件包安装到设备上,等设备启动后验证固件版本是否已更新、硬件是否工作正常。
作为开发人员,如果了解升级流程,完全可以通过在设备上修改版本号记录文件、更换二进制固件文件,然后重启设备的方式进行验证。如果要替换的一些文件在压缩包中,则可以先将设备上的压缩包取出,利用7-zip压缩/解压软件进行替换,再将替换后的压缩包上传到设备。
2.4.2 利用环境变量控制代码分支进行快速测试
当前较复杂的软件系统在设计实现时,除了正常的处理逻辑,还需要有大量的错误异常处理需要考虑;实现完成后,针对所有分支的完备覆盖测试是保证软件质量、保证系统在网稳定运行的重要环节。
一些用于异常处理的分支只有当故障等异常发生时才会运行,才能验证异常处理是否有效;但在测试验证过程中许多错误却难以注入。
常用的故障注入手段主要有以下两种:
1.注入真实故障
如在驱动软件的测试过程中,可能需要对驱动相关的硬件进行焊接飞线等操作注入故障;一方面操作复杂、耗时长效率低,另一方面容易损毁研发物料,导致浪费。
2.通过修改代码进行打桩,模拟故障
每次打桩后需要重新编译再安装系统进行测试,且打桩代码写死后就无法进入正常分支;测试完成后需要修改回原来的代码并重新编译以及安装系统,效率低下且容易出错。
如对于以下条件处理分支:
if (pcie_error_condition) //条件判断
{
process_pcie_error(); //逻辑处理
}
要验证代码中的处理逻辑,要么构造出验证条件,对硬件注入pcie错误;要么代码打桩,直接将pcie_error_condition改为TRUE,验证完成后需要再改回去,开发过程中如果有多个条件需要频繁的修改为TRUE/FALSE这种方法就需要多次代码修改、系统构建、系统安装。
这种情况下可以利用环境变量控制代码分支提高验证效率。环境变量是计算机系统中能够影响系统运行方式的一组命名变量。环境变量可以在软件模块外部通过系统的命令行进行修改,软件实现时可以根据环境变量取值进入相应的分支。以下是使用环境变量控制是否进入分支的一个实例:
将上述代码修改为:
if ((pcie_error_condition || getenv(“env_var1”)) && getenv(“env_var2”)) //条件判断
{
process_pcie_error(); //逻辑处理
}
则可以通过命令行修改env_var1,env_var2这两个环境变量的值来控制是否进入这个分支执行process_pcie_error()处理,变量取值和控制关系如下表所示:
|
env_var2 env_var1 |
FASE |
TRUE |
|
FASLE |
不进入 |
维持原逻辑,即 根据pcie_error_condition判断 |
|
TRUE |
不进入 |
进入 |
如要观察调试process_pcie_error()的处理逻辑,只需要执行将env_var1、env_var2两个环境变量都改为”TRUE”即可。调试完成后将将env_var1、env_var2两个环境变量分别改为”FALSE”、”TRUE”即可恢复原来的处理逻辑,不影响代码的正常运行。
注:由于getenv获取到的只是一个字符串,上述代码仅作为示例使用并不能直接运行。要运行需要进行简单处理——如判断通过环境变量的获取的字符串与给定的字符串”TRUE” 是否相等,将环境变量字符串转换为布尔真假。
2.5 利用notepad++提高分析问题效率
1. 全目录搜索/替换
Notepad++是一款强大的文本编辑工具,当知道大概的关键词但不知道在哪个日志时可以使用notepad++的文件搜索功能,在整个目录及其子目录的文件中尝试搜索。
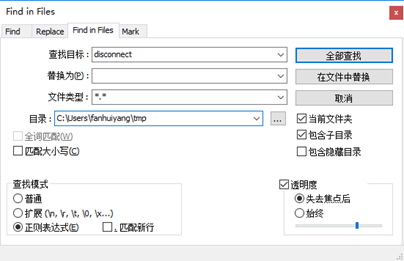
如某客户机房出现FC网络不稳定,需要分析交换机日志排查出问题的端口;但是交换机是其他厂商的设备,日志解压后有上百个文件。我们并不清楚每个文件的内容,此时就可以利用文件搜索功能在整个目录下搜索link up,link down,connect,disconnect等疑似关键词,根据查找结果进一步分析。
具体方法如下:点击“搜索>在文件中查找”,在弹出的对话框中填入关键词、搜索目录、文件类型*.*(全部文件类型),勾选当前文件夹、包含子目录,点击全部查找即可。
2.多个关键词同时查找
分析日志时通常需要搜索多个关键词,再在搜到的文本行前添加“///”等标识符将日志标记出来,标记完成后再搜索标识符列出问题相关日志进行分析。
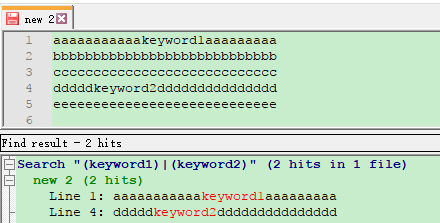
利用notepad++的正则表达式搜索功能可以同时搜索多个关键词,使用方法与上图相同,只需要在“查找模式”中勾选正则表达式,“查找目标”中填入要搜索的多个关键词“(keyword1)|(keyword2)”,点击搜索即可搜出文本中包含keyword1或者keyword2的文本行。
示例文本及搜索结果如下所示:
正则表达式的进一步了解可参照:http://blog.jobbole.com/63398/。
3.notepad++配合git快速查找某处修改对应的提交记录
开发过程中经常需要了解某个特定的变量历史上做了哪些改动,以及改动的原因、时间、修改人等信息。但是查看git log的最小粒度为文件,如果变量所在的文件的其他内容修改次数较多,就需要每次执行一条“git show <commit_id>”命令,再到命令结果输出中查看是否有我们关注的变量。利用notepad++配合git,即使有上千次提交也可以快速查找修改记录。
示例如下:
1.执行命令” git log <path/file> >gitlogresult”将某个文件的commit log重定向到文件gitlogresult中;
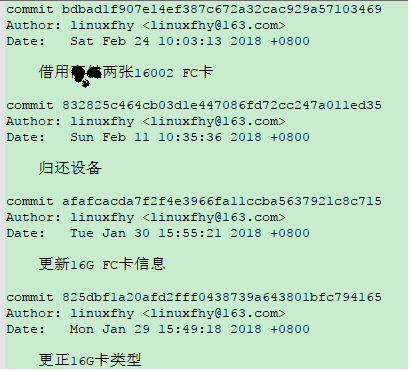
2.利用正则表达式”^commit”搜索,过滤出以commit开头的包含commit id的行;

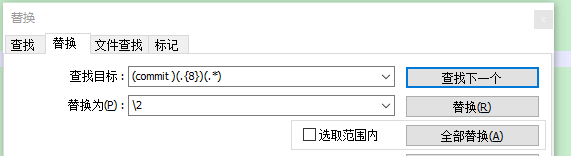
3.利用正则表达式进行替换,”()”表示捕获。
将上图中的每一行分为三部分:第一部分 “commit ”,第二部分为commit id的前8个字符(.表示任意字符,{8}表示重复8次),第三部分为commit id的剩余部分(*表示任意个字符)。
替换为“\2”表示替换为第二次捕获,即commit id的前8个字符。
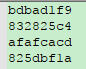
替换结果为:
4.再次利用正则表达式处理上图,将(.*)替换为echo "git show \1” >>borrowinglog\ngit show \1 >>borrowinglog
替换后的结果如下图所示:
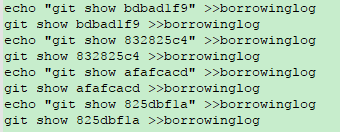
5.步骤4的处理结果中,每两行命令的含义分别为:将要执行的命令重定向到borrowinglog文件中和将命令的执行结果重定向到borrowinglog文件中。也就是说在borrowinglog文件中包含了所有执行的命令以及命令的执行结果,再利用多关键词匹配正则表达式”(git show)|(变量名)”搜索就可以快速找到变量修改历史及对应的commit log信息。
4.notepad++列编辑功能
2.6其他--材料归档等
另外一个容易被忽略但是稍加用心就可以很大程度提高工作效率的方面是材料的归档。刚开始工作时没有归档的意识,平时涉及的工作内容较多,经常需要查询一些历史问题、材料时花费大量时间。后来被迫在找文档的痛苦中养成了良好的归档习惯。需要文档时能够快速找到,手头工作不卡壳比公司配备一部顶配流畅不卡的办公电脑更加令人心情舒畅。
归档没有固定的方法,只需要养成自己的习惯,按照习惯划分层级。比如首先按照是否跟代码业务逻辑相关划分两个目录,每个目录下再按类别划分子目录。

处理问题归档时,建议以“时间+问题反馈人+设备型号+简短问题描述”的格式归档处理的问题,目录中存档好原日志、分析标注的日志、用文档保存问题答复邮件等。
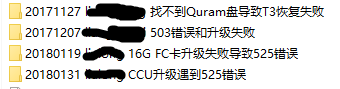
另外对于频繁访问的目录,可以在Excel中以超链接的形式平面的展示出来,点击超链接可以直接跳到对应目录或者打开文件。例如需要画一个客户设备组网图,可以直接点击下图中的“draw画图模板”,打开模板后利用2.3部分介绍的组网图模板画新的组网图,非常方便。
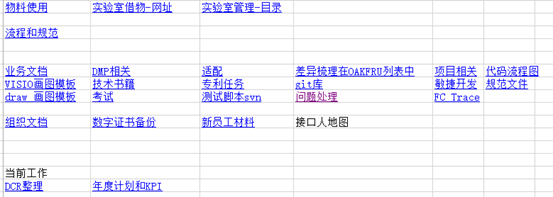
对于一些常用操作命令,比如git、MySql、shell的常用命令可以利用有道云笔记进行记录。
3.效率提升(团队部分)
3.1 团队日常工作的标准化运作
现规模的软件开发离不开分工、合作,分工让专业的人干专业的事,合作将多人的工作成果组织整合,达成团队目标。但是分工多了工作难免杂乱,事务的分发、记录跟踪、上下游环节的交接沟通都要耗费较高的时间成本。分工合作的最典型的例子是开发过程中遇到的测试问题处理:
测试工程师测出问题提报bug > 测试经理确认bug > 开发接口人分发bug > 模块开发责任人分析、解决bug > 模块开发Leader审核修改 > 测试工程师回归测试 > 问题关闭归档
一个bug从提出到解决归档涉及多个环节,每个环节的负责人向下个环节交接时都需要提供大量信息,比如测试人员提报bug时需要提供测试环境、触发问题的操作等信息;开发人员则需要提供详尽的问题根因流程图、详细修改方案、代码库提交ID、代码静态检查记录等信息。
而以上所提到的只是主要流程,实际工作中还要考虑各个环节被打回怎样处理,问题归档后是否便于后续查找、问题是否属于一类典型问题,并将避免此类问题作为后续开发的基本要求等。在整个问题处理流程中,不排除测试、开发人员是刚毕业或者刚加入公司的新员工,难免会在上下游交接时缺失一些信息导致下游同事无法继续处理,需要联系上个环节的同事补充信息,带来较高的沟通成本。
因此大多数公司在处理bug时都会采用专门的bug跟踪工具,如Mantis、Jira、DTS等。首先将流程固化下来,然后将一些必要信息作为各个环节的必填信息,只有必填信息完善后才能转交给下个环节处理人。这样就利用专门的工具既保证每个问题都能够最终关闭归档,避免遗漏处理了一半的问题;又保证上下游环节处理人交接问题时必要信息的完整性,避免各个环节处理人之间高昂的沟通成本。
上文提到的测试问题解决仅仅是工作中的一个事项,日常工作包含众多事项,每件事项具有多个环节,每个环节需要不同的角色来处理。怎样将事项、环节、 员工角色三者系统地组织起来,既能有效的跟踪每项事务落地,又能最大程度降低沟通交流成本?
Bug跟踪系统给我们提供了一个很好的方案:可以将事务梳理成一个个流程,每个流程划分好环节和环节责任人,像处理bug单一样处理各项事务,实现标准化运作。
几个可以流程化的日常工作例子:
1) Bug处理:
Bug提报 > bug确认 > 分析修改 > 审核修改 > 回归测试 > bug关闭归档
2) 需求跟踪
需求提报 > 需求价值评审 > 需求实现 > 功能验证 > 需求落地关闭
3) 负向改进
发现痛点 > 提报改进 > 改进价值评审 > 改进实施 > 实施结果审核 > 改进落地关闭
4) 客诉问题处理
客户反馈问题 > 提报问题 > 问题分析 > 问题解决及客户满意度维护 > 负向改进审视 > 问题关闭
5) 待办事项处理等
事项提报 > 事项处理 > 关闭
并且可以将这些独立的流程相互关联起来,利用统一的工具搭建集成的团队电子工作平台。举例来说,在“4)客诉问题处理”流程中如果走到“负向改进审视”环节,发现通过该问题暴露出来的一些问题的确需要改善,则可以以此为痛点在“3)负向改进”流程中提报改进,并将改进单的超链接地址附到客诉问题处理单中;同时将客诉问题处理单的地址附到改进单当中。
客诉问题完成关闭归档后,无论过多长时间再打开问题单就知道针对这类问题进行过什么改进;打开负向改进单也能了解执行此次改进的背景是什么。可以节省大量追溯问题相关信息的时间精力。
此外一些文档、版本发布记录也可以用Bug跟踪工具进行管理。以版本发布为例,以一个问题单记录一次版本发布信息。可以在问题单中填写任何需要的信息,如代码仓库提交id、发布日期、构建参数信息、代码修改信息、解决的问题单号等等。设备经过一到两年网上运行,出现问题进行排查回退版本时,这些信息会非常有用,且如果没有做好记录将会很难获取。如下所示:
版本发布记录:

具体一个版本的详细信息:

此外如果对web开发比较熟悉可以自己写一个流程引擎用于跟踪自己的工作生活中的各事项。以下例子是自己利用django框架开发的一个工作流引擎,并基于其搭建的个人电子工作平台。目前已部署到阿里云虚拟机,网址为http://www.tasksteper.com:8099/flow/home/,可下载右侧的”帮助文档”进一步了解。
个人电子工作平台主要包含以下内容:
1. 多个项目组成的平台界面:
一些工作内容、待办事项,以及平时的爱好——骑行的一些目的地和美食推荐都可以利用平台上的一个项目进行管理。每个项目可以定义自己的流程和字段,可以灵活的跟踪很多事情。
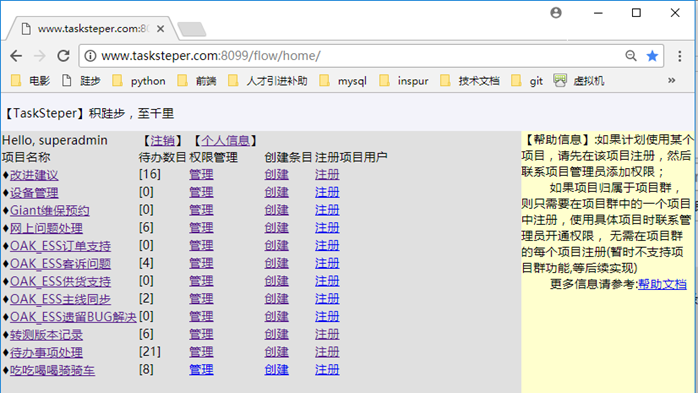
2.其中一个项目,“网上问题处理”项目中的待办问题列表。

3. “网上问题处理”项目中具体一个待办问题的示例:
当前状态处于“维护代表审核”阶段的问题单只能通过“转SE分析改进”或“打回补充信息”按钮转向各自对应的下一环节,将问题处理限定在特定流程中,实现问题处理的标准化。

3.2 公共系统效率提升
团队使用的公共系统极大影响整个团队的效率,这些系统需要尽可能的快速高效,对于100人团队每人节约1小时就是100人时,对于团队来说是可观的效率提升和成本节约;对于员工来说是工作软环境很大程度的改善,可以使员工专注于处理业务,避免了因工具耗费过多时间带来的不必要加班。
以版本构建系统为例,多个开发者向同一个代码库提交代码,进行构建时需要先将最新代码同步到构建机的各用户的构建目录,然后再启动编译。编译分为增量编译和全量编译,增量编译只需要将构建目录下和代码库上的代码差异拉取到构建目录,使得构建目录下的代码与代码库代码一致,然后编译修改过的代码即可。全量编译则需要清空用户构建目录,然后通过网络将代码库上的整个代码目录拷贝到构建目录下重新构建。
日常工作中全量编译又不可避免,以git作为版本工具为例,开发过程中通常需要拉取新的临时分支进行修改验证,验证通过后再将分支上的修改合入到开发主干分支。这些临时分支只能采用全量构建的形式进行编译。在代码规模较大且网络质量不是很好时,通常会耗费1.5小时以上的时间用于从构建机向代码库拷贝代码,整个构建过程耗费接近3小时。

大规模的系统软件源代码规模动辄上几个GB,每次全量构建都通过网络拷贝会浪费大量时间。这种情况下可以在构建机上创建一个临时代码目录,该目录与代码库每周定时同步一次。启动全量编译时,先利用脚本将临时代码目录下的代码拷贝到用户构建目录,然后将至多一周的差异(几MB的规模)从代码库同步到用户构建目录,启动构建。
参照上图,改进前后的方案分别为:
改进前:
直接从代码库拷贝全部代码(git clone)到用户构建目录,如蓝色箭头所示,耗时1.5小时以上。
改进后:
1.从构建机本地的临时代码目录拷贝代码(cp)到用户构建目录,如橙色箭头所示,耗时5分钟内。
2.从代码库同步(git pull)至多一周的差异到用户构建目录,耗时5分钟内;
3.每周执行一次从代码库到临时代码目录的同步(git pull),耗时5分钟内。
通过这种改进能将获取代码库最新代码到构建目录下所需的时间由1.5小时缩短到10分钟内。成本是初次从代码库拷贝代码到构建机的临时代码目录(git clone)会耗费1.5小时以上的时间,以及构建机上会耗费几个G左右的空间用于放置临时代码目录。相对于为整个团队节约的时间成本,这些成本可以忽略不计了。
4.一些小技巧
4.1快速找到上级调用函数
软件架构设计中,通常设计有公共框架以及各个子模块。公共框架提供逻辑接口供各子模块调用。这种结构保证了业务处理逻辑的统一、简洁,很大程度上降低了开发难度。但是这种架构在遇到问题,尤其是问题出现在框架中时,由于可能几十个模块都在使用框架提供的接口,很难判断问题到底是由哪个模块引入,给定位带来困难。
如在以下伪代码中,框架代码提供了一个公共接口,两个子模块都使用框架提供的接口来处理本模块的逻辑:

如果 frame_function_public执行过程中遇到了问题,且确定问题是调用者引入;最容易想到的方法是先分析可能引入问题的模块,然后在模块内部添加调试信息进行确认。如在模块1和模块2调用框架接口 frame_function_public的地方的前后添加日志打印,这种方法耗时较多,对于模块数量级达到十级及以上的系统很难分析。
对于定位这种问题,可以利用宏对框架提供的公共函数进行封装,将调用公共函数的模块的函数名和行号直接导出到日志文件中,具体方法如下:
1.将要封装的函数进行重命名,仍以上述代码为例;
可以将函数名frame_function_public修改为frame_function_public_actual
2.利用宏重新对重命名后的函数进行封装,宏的名字与函数重命名前保持一致。这样模块1和模块2原来调用的函数frame_function_public就变成了宏,宏的名字和参数都和原来的函数保持一致。编译器编译代码时,会将frame_function_public(para1, para2)替换成下文伪代码中从do到while(0)的部分,其中的frame_function_public_actual(para1, para2)负责执行修改前的 frame_function_public (para1, para2)的逻辑处理。这样就可以不用修改各模块代码的情况下,将调用公共接口frame_function_public的各模块的函数名、行号等信息输出到日志文件/tmp/logfile.log中。


5.持续积累--碎片时间利用
无论上班期间还是下班后总有一些碎片时间被白白浪费掉,比如上班期间工作需要对设备进行重启、升级等操作,可能需要等待5-10分钟,这时如果着手下一项工作,来回切换成本太高,通常就顺便休息一下,刷一下手机就过去了。但如果一天中需要多次重启、升级验证,所有等待时间积累起来很长,白白浪费掉还是很可惜的。
如果能将这些碎片时间利用起来,既能按时完成工作避免过多加班,又能轻轻松松积累技能、经验,何乐而不为?相比同时参加工作的一些同事,个人的成长的确算不上快,但是在尽量不牺牲个人太多娱乐时间不那么痛苦的前提下,几年下来也利用零零散散的时间有了一些积累。比如北京出差时,在酒店出门前用手机拍《linux内核与实现》,每次地铁上看个两三页,在出差期间几乎看完了整本书,虽然现在忘差不多了。。。。
由短到长的碎片时间可以用来做不同的事情:
3-10分钟:大概设备开机、升级、回退所需的时间;这种情况下不必盯着设备,可以设置定时器10分钟左右再去观察。利用这10分钟可以在git目录下写写技术文档、个人总结、翻翻技术论坛短贴等。比如利用这些时间慢慢积累起一个所负责模块的详尽技术文档,后续周边模块同事有问题需要了解时直接将文档抛出来又可以节约大段沟通交流讲解的时间。再次安利git,绝对是帮助利用碎片时间写文档的利器!
30分钟:可以将一台新电脑修改成自己习惯的配置;安装顺手的工具,搭建好git环境,导入网络书签等,保证自己用着顺手;也可以阅读技术论坛的长贴、技术书籍;调试功能示例代码;下班后可以看纪录片练听力,或者看一集短电视剧等,总之尽量不要漫无目的的浏览、刷屏。
1小时+:构思架构,完成比较复杂的配置,持续维护一个项目编码等,一部电影等;
5小时+,出去玩吧~~~
只要有利用时间的意识,在时间上并不必锱铢必较;可以拿时间来玩,发呆,看电影;只要利用一些本来被浪费的时间的一部分基本就够了,而且养成习惯后会发现浪费的时间越来越少,有空闲时间很自然的就想起要干点什么。
利用碎片时间的看得见的成果:
2017年用了5个月左右,每日半小时左右零基础自学了python简单语法、django web框架、mysql基本操作、nginx部署,购买了一台阿里云服务器搭建了上文提到的个人电子工作平台--事务跟踪系统;2018年用一个多月完成了这篇总结。把零散的时间利用起来还是比较有效果的。

