word2vec
一、词向量
1、最简单的词向量:one-hot编码形式。
2、分布式词向量:将词表示成一个定长的连续稠密向量。
word embedding 将词转化为一种分布式表示。生成分布式词向量的方法有很多,这些方法依照一个思想:任一词的含义可以用它的周边词来表示。又分为:基于统计的方法和基于语言模型的方法。
2.1基于统计的方法
2.1.1 共现矩阵

我们使用一个size=1的窗口,对每句话依次进行滑动,相当于只统计紧邻的词。这样就可以得到一个共现矩阵。
共现矩阵的每一列,自然可以当做这个词的一个向量表示。这样的表示明显优于one-hot表示,因为它的每一维都有含义——共现次数,因此这样的向量表示可以求词语之间的相似度。
然后这样表示还有有一些问题:
维度=词汇量大小,还是太大了;
还是太过于稀疏,在做下游任务的时候依然不够方便。
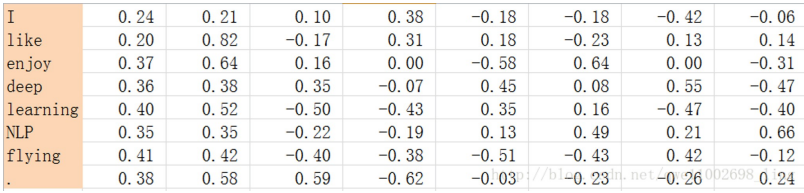
2.1.2 SVD矩阵分解
对上图进行SVD矩阵分解,得到矩阵U,对U进行归一化,得到如下矩阵
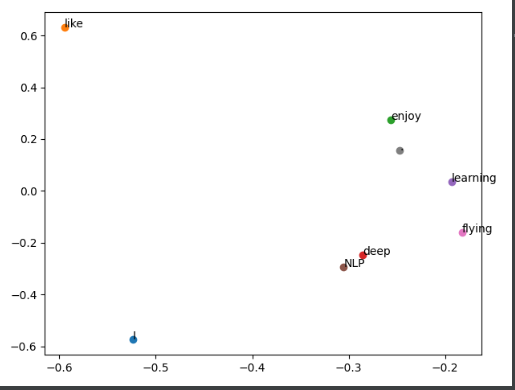
import numpy as np
from matplotlib import pyplot as plt
la = np.linalg
words = ["I","like","enjoy","deep","learning","NLP","flying","."]
x = np.array([[0,2,1,0,0,0,0,0],
[2,0,0,1,0,1,0,0],
[1,0,0,0,0,0,1,0],
[0,1,0,0,1,0,0,0],
[0,0,0,1,0,0,0,1],
[0,1,0,0,0,0,0,1],
[0,0,1,0,0,0,0,1],
[0,0,0,0,1,1,1,0]])
U, s, Vh = la.svd(x,full_matrices=False)
print(U.shape)
for i in range(len(words)):
plt.scatter(U[i, 0], U[i, 1])
plt.text(U[i, 0], U[i, 1], words[i])
plt.show()
2.2 语言模型
NNLM 《A Neural Probabilistic Language Model》
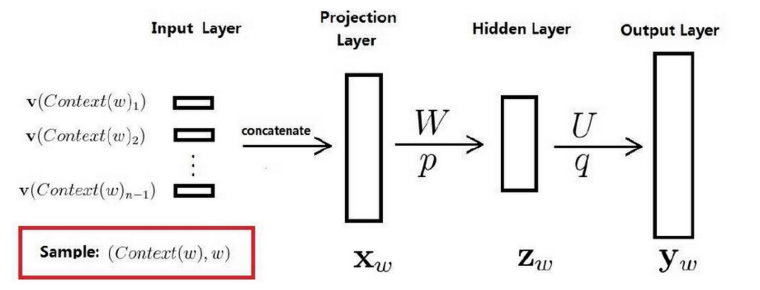
W和U为两个权重矩阵

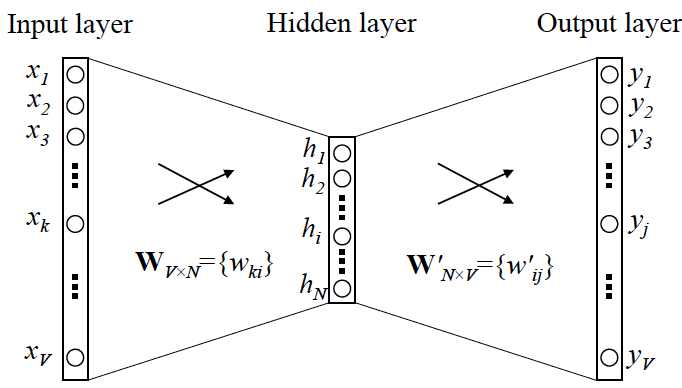
二、word2vec
1、原理
https://zhuanlan.zhihu.com/p/26306795
2、gensim实现
https://www.cnblogs.com/pinard/p/7278324.html
gensim word2vec API概述
在gensim中,word2vec 相关的API都在包gensim.models.word2vec中。和算法有关的参数都在类gensim.models.word2vec.Word2Vec中。算法需要注意的参数有:
-
sentences: 我们要分析的语料,可以是一个列表,或者从文件中遍历读出。后面我们会有从文件读出的例子。
-
size: 词向量的维度,默认值是100。这个维度的取值一般与我们的语料的大小相关,如果是不大的语料,比如小于100M的文本语料,则使用默认值一般就可以了。如果是超大的语料,建议增大维度。
-
window:即词向量上下文最大距离,这个参数在我们的算法原理篇中标记为c,window越大,则和某一词较远的词也会产生上下文关系。默认值为5。在实际使用中,可以根据实际的需求来动态调整这个window的大小。如果是小语料则这个值可以设的更小。对于一般的语料这个值推荐在[5,10]之间。
-
sg: 即我们的word2vec两个模型的选择了。如果是0, 则是CBOW模型,是1则是Skip-Gram模型,默认是0即CBOW模型。
-
hs: 即我们的word2vec两个解法的选择了,如果是0, 则是Negative Sampling,是1的话并且负采样个数negative大于0, 则是Hierarchical Softmax。默认是0即Negative Sampling。
-
negative:即使用Negative Sampling时负采样的个数,默认是5。推荐在[3,10]之间。这个参数在我们的算法原理篇中标记为neg。
-
cbow_mean: 仅用于CBOW在做投影的时候,为0,则算法中的xw为上下文的词向量之和,为1则为上下文的词向量的平均值。在我们的原理篇中,是按照词向量的平均值来描述的。个人比较喜欢用平均值来表示xw,默认值也是1,不推荐修改默认值。
-
min_count:需要计算词向量的最小词频。这个值可以去掉一些很生僻的低频词,默认是5。如果是小语料,可以调低这个值。
-
iter: 随机梯度下降法中迭代的最大次数,默认是5。对于大语料,可以增大这个值。
-
alpha: 在随机梯度下降法中迭代的初始步长。算法原理篇中标记为η,默认是0.025。
-
min_alpha: 由于算法支持在迭代的过程中逐渐减小步长,min_alpha给出了最小的迭代步长值。随机梯度下降中每轮的迭代步长可以由iter,alpha, min_alpha一起得出。这部分由于不是word2vec算法的核心内容,因此在原理篇我们没有提到。对于大语料,需要对alpha, min_alpha,iter一起调参,来选择合适的三个值。
import os
from gensim.models import word2vec
# .txt每一行为用空格隔开的单词。
sentences = word2vec.LineSentence('./in_the_name_of_people_segment.txt') # word2vec提供的LineSentence类来读文件
model = word2vec.Word2Vec(sentences, hs=1,min_count=1,window=3,size=100)

 浙公网安备 33010602011771号
浙公网安备 33010602011771号