pyspark(一) 常用的转换操作
一、map
- map:对RDD中每个元素都执行一个指定函数从而形成一个新的RDD
from pyspark import SparkConf, SparkContext
conf = SparkConf().setMaster("local").setAppName("MyApp")
sc = SparkContext(conf = conf)
def func(x):
return x*2
data = [1, 2, 3, 4, 5]
rdd = sc.parallelize(data)
mapRdd2 = rdd.map(func)
print(mapRdd2.collect())# [2, 4, 6, 8, 10]
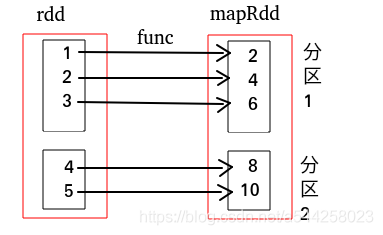
map依赖图关系如下,红框代表整个数据集,黑框代表一个RDD分区,里面是每个分区的数据集
- flatMap:与map类似,但是每一个输入元素会被映射成0个或多个元素,最后达到扁平化效果
data = [[1,2],[3],[4],[5]]
rdd = sc.parallelize(data)
print(rdd.collect()) # [[1, 2], [3], [4], [5]]
flatMapRdd = rdd.flatMap(lambda x: x)
print(flatMapRdd.collect())# [1, 2, 3, 4, 5]
flatMap依赖关系图如下

map和flatMap对比
rdd = sc.parallelize([("A",1),("B",2),("C",3)])
flatMaprdd = rdd.flatMap(lambda x:x)
print(flatMaprdd.collect()) # ['A', 1, 'B', 2, 'C', 3]
maprdd = rdd.map(lambda x:x)
print(maprdd.collect()) # [('A', 1), ('B', 2), ('C', 3)]
- mapPartitions:是map的一个变种,map对每个元素执行指定函数,mapPartitions对每个分区数据执行指定函数
rdd = sc.parallelize([1, 2, 3, 4],2)
def f(iterator):
yield sum(iterator)
print(rdd.mapPartitions(f).collect()) # [3, 7] 两个分区,第一个分区为 [1,2],第二个分区为[3,4]
其实mapPartitions可以当成map来用:如果涉及到连接数据库的操作,可以在mapParition所用的函数里建立连接。然后得到的结果保存到列表中返回。
from pyspark import SparkContext
sc = SparkContext("local", "First App")
rdd1 = sc.parallelize([("a",1), ("b",1), ("c",2), ("d",3),("e",6),("f",7),("g",8)])
rdd2 = sc.parallelize([("a",2), ("b",3), ("c",4), ("d",5)])
rdd4 = sc.parallelize([("a",2), ("b",3), ("c",4), ("d",5)])
rdd3 = rdd2.union(rdd1).union(rdd4)
print(rdd3.collect())
rdd5 = rdd2.union(rdd1).union(rdd4).repartition(3)
print(rdd5.getNumPartitions())
def myfunc(x):
res = []
for item in x:
res.append(item[0])
return res
rdd6 = rdd5.mapPartitions(myfunc) # 传入列表,然后返回列表。最终rdd6里面就是一个列表
print(rdd6.collect())
二、filter
1.filter:按照条件进行过滤
rdd = sc.parallelize([("a",2), ("b",3), ("c",4), ("d",5)])
# 条件为True的元素留下,舍弃为False的元素
rdd = rdd.filter(lambda x: x[1]>=5)
对于已经排序好的rdd,配合zipWithIndex(),可以使用 filter()来获取前N个数据组成的RDD,而不是take()或者top()这些行动算子。
三、sort
1.sortBy:排序
def sortBy(self, keyfunc, ascending=True, numPartitions=None):
"""
Sorts this RDD by the given keyfunc
>>> tmp = [('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
>>> sc.parallelize(tmp).sortBy(lambda x: x[0]).collect()
[('1', 3), ('2', 5), ('a', 1), ('b', 2), ('d', 4)]
>>> sc.parallelize(tmp).sortBy(lambda x: x[1]).collect()
[('a', 1), ('b', 2), ('1', 3), ('d', 4), ('2', 5)]
"""
return self.keyBy(keyfunc).sortByKey(ascending, numPartitions).values()
源码中,默认是正序排列,一般业务需要倒叙排列,参数为False,即大的数在前面。
排序条件可以设置多个,当第一个相同时,以此按照后续条件进行排序
from pyspark import SparkContext
sc = SparkContext("local", "First App")
rdd = sc.parallelize([(1,"a",1),(1,"b",2),(3,"d",4),(3,"c",3)])
rdd = rdd.sortBy(lambda x:(x[0],x[1],x[2]),False)
print(rdd.collect())
2.sortByKey
针对 key-value数据,根据key进行排序
list = ["14", "134", "1244"]
rdd = sc.parallelize(list)
pairRDD = rdd.map(lambda word: (word, len(word)))
# x是key,x[1] 是key对应字符串中索引为1的字母
aa = pairRDD.sortByKey(keyfunc=lambda x: x[1])
aa.foreach(print)
# ('1244', 4)
# ('134', 3)
# ('14', 2)
#注意上下的结果区别
list = ["14", "134", "1244"]
rdd = sc.parallelize(list)
pairRDD = rdd.map(lambda word: (word, len(word)))
aa = pairRDD.sortBy(keyfunc=lambda x: x[1])
aa.foreach(print)
# ('14', 2)
# ('134', 3)
# ('1244', 4)
四、zip
1、zip
两个RDD具有相同个数的分区,并且每个分区内的个数相等
例子:
x=sc.parallelize(range(5),2)
y=sc.parallelize(range(1000,1005),2)
a=x.zip(y).glom().collect()
print(a)
a=x.zip(y).collect()
print(a)
2、zipWithIndex()
给RDD的每个元素加上索引。排序后的RDD加上元素对应的顺序序号
# zipWithIndex()的结果为[((1,2),0),((1,3),1)]
sortBy(lambda x: (x[0], x[1]), False).zipWithIndex().map(lambda x: (x[0][0],x[1]+1))
3、zipWithUniqueId
返回k-v,与分区有关系
k, n+k, 2n+k,
n为分区总数,下例 n=2
k其属于第几个分区,从0开始计数。下例 k=0,1
对于k=0的分区:\(0+0*2,0+1*2,0+2*2\)
rdd=sc.parallelize(list('123456'),2)
print(rdd.glom().collect()) # [['1', '2', '3'], ['4', '5', '6']]
a=rdd.zipWithUniqueId().glom().collect()
print(a) # [[('1', 0), ('2', 2), ('3', 4)], [('4', 1), ('5', 3), ('6', 5)]]

 浙公网安备 33010602011771号
浙公网安备 33010602011771号