企业级大数据框架概述
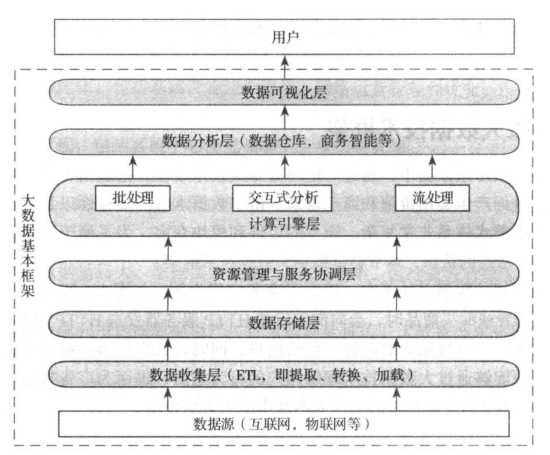
1、数据收集层
1)扩展性:灵活适配不同的数据源。
2)可靠性:数据在传输过程中不能丢失。
3)安全性:敏感数据在收集过程中不会有安全隐患。
4)低延迟:能够以较低延迟传输到后端存储系统中
2、数据存储层
1)扩展性:需要灵活增加新机器扩展存储能力。
2)容错性:在机器出现故障不会导致数据丢失。
3)存储模型:支持多种数据模型,确保结构化和非结构化数据容易保存。
3、资源管理与服务协调层
1)资源利用率高:共享集群模式通过多种应用共享资源,使集群资源得到充分利用。
2)运维成本低:共享模式需少数管理员可以完成对多个框架的统一管理。
3)数据共享:多种应用公用集群中的硬件资源,大大减少数据移动带来的成本。
4、计算引擎层
1)批处理:最求高吞吐率,即单位时间内处理的数据量尽可能大。
2)交互式处理:对时间要求比较高,需要系统与人进行交互。
3)实时处理:对时间要求最高。
5、数据分析层
与用户应用程序对接,为其提供易用的数据处理工具。
6、数据可视化层
运用计算机图形学和图像处理技术,将数据转换为图形或图像在图形中显示出来,并进行交互处理的理论、方法和技术。
大数据架构:Lambda Architecture
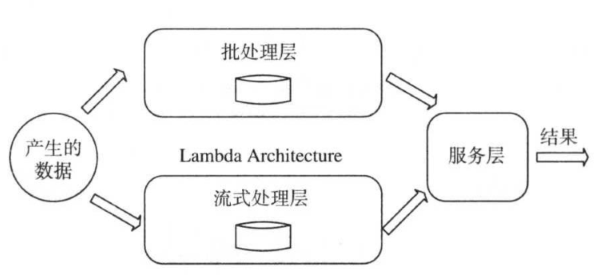
1、批处理层
主要思想是利用分布式批处理计算,以批处理为单位处理数据,并产生一个经预计算产生的只读数据视图。该层将数据流看成只读的、仅支持追加操作的超大数据集。
优点是吞吐率高;缺点是高延迟性。
2、流式处理层
为降低处理层的高延迟问题,使用流式计算技术。
优点是处理延迟低;缺点是无法进行复杂的逻辑计算,得到的解往往是近似解。
3、服务层
将批处理层和流式处理层结合在一起,整合计算结果,对外提供了统一的访问接口方便用户使用。
内容来源书籍:《大数据技术体系详解 原理、架构与实践》 --董西成

 浙公网安备 33010602011771号
浙公网安备 33010602011771号