redis专题六:redis数据类型之sorted_set
一、基本简介
这里叫sorted_set,可能有的地方叫zset,这里文章写sorted_set,是因为我们用help 看相关命令的时候,group为sorted_set。不过不重要。
我们存储了很多的数据,并不是单纯放在那里,还要应用于查询,现在提出来一种新的诉求:展示的时候有序。
比方说股票基金,要看涨幅跌幅排行;学生成绩高低;员工工资排序等。前面的几种数据类型都不具备排序的特征。于是,产生了sorted_set。
sorted_set:是在set基础上添加可排序的字段score,这个不要理解为数据,而是权重
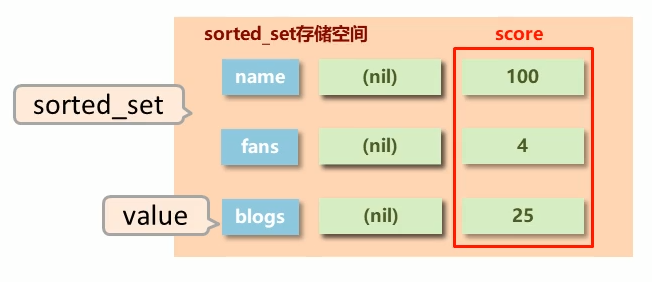
二、基本操作
| 功能 | 命令 | 其他说明 |
| 添加数据 | zadd key score1 member1 [score2 member2] | |
| 获取全部数据 |
zrange key start stop [WITHSCORES] zrevrange key start stop [WITHSCORES] |
命令携带withscores会一起打印score(奇数是数据,偶数是排序的权重) |
| 删除数据 | zrem key member [member...] | |
| 按条件获取数据 |
zrangebyscore key min max [withscores] [limit] zrevrangebyscore key min max [withscores] |
例子:zrangebyscore persons 20 70 limit 0 3 withscores 查询权重20-70之间的人;limit限定查询结果个数,类似MySQL的分页。 |
| 按条件删除数据 |
zremrangebyrank key start stop zremrangebyscore key min max |
例子:zremrangebyrank persons 0 1 按照索引删除,返回成功的个数 例子:zremrangebyscore persons 20 70 删除权重20-70之间的人,返回删除成功的个数 |
| 获取集合数据总量 |
zcard key zcount key min max |
zcard key 返回集合数据的总数 zcount看score指定范围的数据有几个 |
| 集合交并操作 |
zinterstore destination numkeys key [key] zunionstore destination numkeys key [key] |
举例:zinterstore ss 3 s1 s2 s3 有几个集合操作,numkeys就写几;结果返回合并后集合的元素; 注意:合并的时候,权重会求和; zinterstore sss 3 s1 s2 s3 aggregate max 这个时候的权重返回权重的最大值 |
注意:
- min max 用于限定搜索查询的条件
- start和stopy用于限定查询范围,作用于索引,表示开始和结束索引
- 和limit相关的offset和count用于限定查询范围,作用于查询结果,表示开始位置和数据总量
三、扩展操作
3.1 实现排行榜
场景:游戏中好友的亲密度;网易云歌曲榜单top10;中国好声音对选手的投票;等等
解决:
| 功能 | 命令 | 其他说明 |
| 获取数据对应的索引 |
zrank key member zrevrank key member |
返回下标索引 |
| score值的获取和修改 |
zscore key member zincrby key increment member |
3.2 任务/消息权重
场景:当任务或者消息待处理,形成任务队列或者消息队列时,对于高优先级的任务要保障其优先处理,如何实现带有权重的管理?
解决:
- 对于带权重的任务,采用score记录权重即可
- 如果是多权重的话,需要进行拼接,注意score的长度限制
- score长度进行统一,不足应该补0
四、注意事项
- score保存的数据存储空间是64为位
- score保存的数据也可以是一个双精度的double值,基于双精度浮点数的特征,可能会丢失精度,使用时候需要慎重
- sorted_set底层存储还是基于set结构的,因此数据不能重复,重复添加相同的数据,score值将会被反复覆盖,保留最后一次修改的结果
这一篇就到这里,下一篇简单说一下redis相关的通用指令。

