

K8S简介
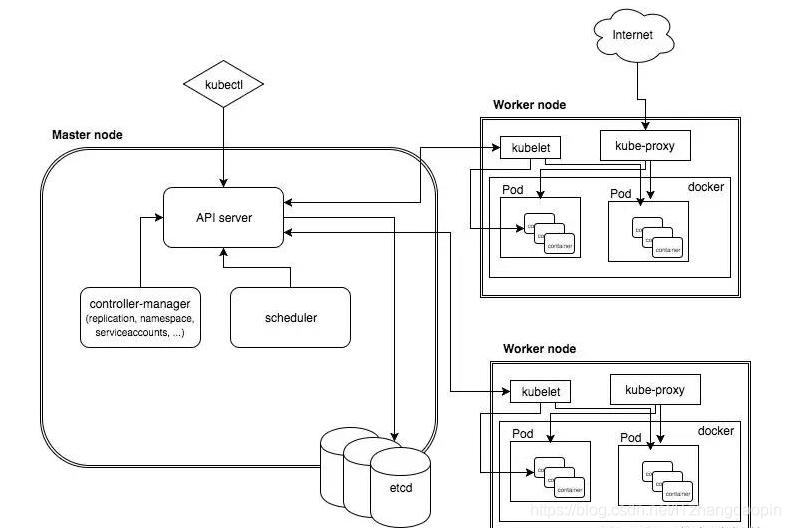
k8s架构图
K8S的优势
1、自动装箱:基于容器对应用运行环境的资源配置要求自动部署应用容器
2、故障迁移(自愈):当某一个node节点关机或挂掉后,node节点上的服务会自动转移到另一个node节点上,这个过程所有服务不中断。这是docker或普通云主机是不能做到的
3、资源调度(弹性伸缩):当node节点上的cpu、内存不够用的时候,可以扩充node节点,新建的pod就会被kube-schedule调度到新扩充的node节点上,如果CPU负载低于阈值则减少容器的数量
4、服务的自动发现和负载均衡: 用户不需使用额外的服务发现机制,就能够基于 Kubernetes 自身能力实现服务发现和 负载均衡。
5、资源隔离:创建开发、运维、测试三个命名空间,切换上下文后,开发人员就只能看到开发命名空间的所有pod,看不到运维命名空间的pod,这样就不会造成影响,互不干扰
6、安全:不同角色有不同的权限,查看pod、删除pod等操作;RBAC认证增加了k8s的安全
7、滚动升级和一键回滚: Kubernetes 逐渐部署对应用程序或其配置的更改,同时监视应用程序运行状况,以确保它不会同时终止所有实例。如果出现问题,Kubernetes会为您恢复更改
8. 密钥和配置管理:在不需要重新构建镜像的情况下,可以部署和更新密钥和应用配置,类似热部署。
9. 存储编排:自动实现存储系统挂载及应用,特别对有状态应用实现数据持久化非常重要 存储系统可以来自于本地目录、网络存储(NFS、Gluster、Ceph 等)、公共云存储服务
K8s好用在什么地方?


k8s重要概念介绍#
| 组件名称 | 作用 |
|---|---|
| Cluster | 资源的集合。我们的k8s利⽤这些资源运⾏各种基于容器的应用。是计算、存储和网络资源的集合 |
| Master | Cluster的⼤脑。司令部。主要的任务就是用来调度的。决定我们的应用应该放到哪⾥去执行。 为了高可⽤,也可以运⾏多个master。职责是运行容器应用。 |
| Node | 来负责运⾏容器应⽤。Node是由Master去管理的,负责监控和容器状态的汇报。 |
| Pod | k8s的最小工作单元,包含1orN个容器。 Pod的使用方式: ⼀个pod运⾏⼀个容器 最常⽤的就是这种情况。 ⼀个pod运⾏多个容器 ⼀定是非常紧密相关的⼀组容器,并且需要资源的共享。⼀起启动、⼀起停止。 |
| Controller | k8s通过它来管理Pod 包含:Deployment、ReplicaSet、DaemonSet、StatefulSet、Job。 Deployment就是我们最常⽤的Controller。它可以管理Pod的多个副本。(即:--replicas=3),并且可以确保Pod按照期望的状态去运⾏。 ReplicaSet它也是管理Pod的多个副本。 我们使⽤deployment的时候,会⾃动的创建ReplicaSet,最终是有ReplicaSet去创建的pod,而我们并不是去直接的使⽤它。 DaemonSet⽤于每个Node最多只运⾏⼀个Pod副本的创建。 StatefulSet保证副本按照固定的顺序启动、更新、删除。 |
| Service |
为Pod提供了负载均衡、固定的IP和Port 区别: |
| Namespace | 解决同一个Cluster中,如何区别分开Controller、Pod等资源的问题,资源隔离! |
- Volume: 存储卷,pod对外暴露的共享目录,它可以挂载在宿主机上,这样就能让同node上多个pod共享一个目录。
- Replication Controller: 用于控制pod集群的控制器,可以制定各种规则来让它控制一个service中的多个pod的创建和消亡, 很多地方简称为rc。
- Namespace: 命名空间,用于将一个k8s集群隔离成不同的空间,pod, service, rc, volume 都可以在创建的时候指定其namespace。
- StatefulSet: 有状态集群,比如一个主从的mysql集群就是有状态集群,需要先启动主再启动从,这就是一种有状态的集群。
- Persistent Volume: 持久存储卷。之前说的volume是挂载在一个pod上的,多个pod(非同node)要共享一个网络存储,就需要使用持久存储卷,简称为pv。
- Persistent Volume Claim: 持久存储卷声明。他是为了声明pv而存在的,一个持久存储,先申请空间,再申明,才能给pod挂载volume,简称为pvc。
- Label: 标签。我们可以给大部分对象概念打上标签,然后可以通过selector进行集群内标签选择对象概念,并进行后续操作。
- Secret: 私密凭证。密码保存在pod中其实是不利于分发的。k8s支持我们创建secret对象,并将这个对象打到pod的volume中,pod中的服务就以文件访问的形式获取密钥。
- EndPoint: 用于记录 service 和 pod 访问地址的对应关系。只有 service 配置了 selector, endpoint controller 才会自动创建endpoint对象。
如果不理解没啥关系,看一遍有印象下,下面我们一个个琢磨琢磨。
master
k8s的master节点上有三个进程,它们都是以docker的形式存在的。我们在k8s的master节点看docker ps 就可以看到这几个进程:
8824aad1ee95 e851a7aeb6e8 "kube-apiserver --ad…" 3 days ago Up 3 days k8s_kube-apiserver_kube-apiserver-docker-for-desktop_kube-system_f23c0965aad6df9f61b1c9c4bb953cf5_0
a9ce81ec9454 978cfa2028bf "kube-controller-man…" 3 days ago Up 3 days k8s_kube-controller-manager_kube-controller-manager-docker-for-desktop_kube-system_1dc44822f21a9cbd68cc62b1a4684801_0
85da3f6e700f d2c751d562c6 "kube-scheduler --ad…" 3 days ago Up 3 days k8s_kube-scheduler_kube-scheduler-docker-for-desktop_kube-system_b6155a27330304c86badfef38a6b483b_0
其中的 apiserver 是提供 k8s 的 rest api 服务的进程。当然它也包括了 restapi 的权限认证机制。 k8s 的 apiserver 提供了三种权限认证机制:
- https
- http + token
- http + base(username + password)
我们也可以通过使用kubectl proxy 在 master 上来创建一个代理,从而外部可以访问这个 k8s 集群。
kube-controller-manager 是用来管理所有的 controller 的。之前我们说的 Replication Controller 就是一种管控 Pod 副本的Controller, 其他相关的 Controller 还有:
- Replication Controller
- Node Controller: 实时获取Node的相关信息,实现管理和监控集群中的各个Node节点的相关控制功能
- ResourceQuota Controller: 确保指定的资源对象在任何时候都不会超量占用系统物理资源
- NameSpace Controller: 定时通过API Server读取这些Namespace信息
- ServiceAccount Controller: 监听Service变化,如果是一个LoadBalancer类型的Service,则确保外部的云平台上对该Service对应的LoadBalancer实例被相应地创建、删除及更新路由转发表
- Token Controller
- Service Controller
- EndPoint Controller : Service 和选择 Pod 的对应关系。
kube-scheduler 负责 Pod 调度,接收 Controller Manager 创建的新的Pod,为其选择一个合适的Node,并且在Node上创建Pod。
一个k8s集群只有一个master节点,所以 master 节点的高可用性是一个问题,一旦 master 节点挂了,整个集群也就挂了。这点真有点神奇。所以网上关于搭建高可用的k8s Master 节点的方案有很多:
https://jishu.io/kubernetes/kubernetes-master-ha/
https://blog.51cto.com/ylw6006/2164981
https://jimmysong.io/kubernetes-handbook/practice/master-ha.html
Node
Node 是 k8s 的工作节点,Node 一般是一个虚拟机或者物理机,每个 node 上都运行三个服务:
- docker
- kubelet
- kube-proxy
docker 就是 docker server,它提供
kubelet 是一个管理系统,它管理本个node上的容器的生命周期,定期从kube-apiserver组件接收新的或修改的Pod规范,并确保Pod及其容器在期望规范下运行。同时该组件作为工作节点的监控组件,向kube-apiserver汇报主机的运行状况。
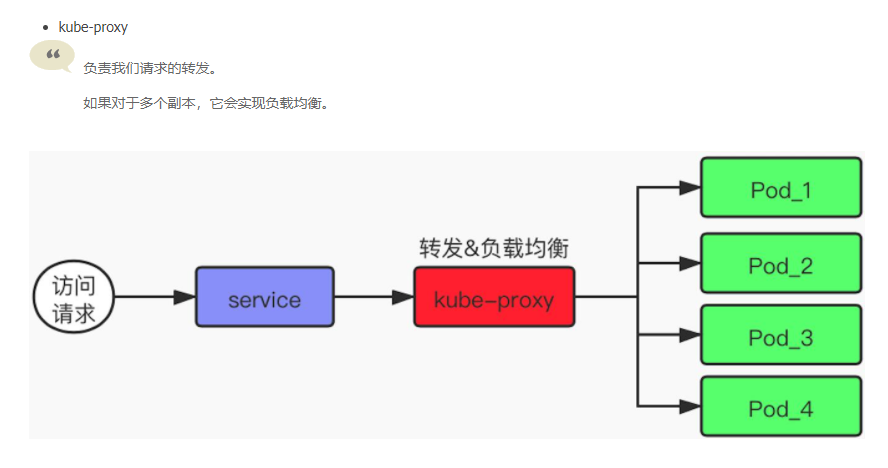
kube-proxy 是管理 service 的访问入口,包括集群内 pod 到 service 的访问,以及集群外访问service。
可用性
其实k8s自身的可用性是比较弱的,如果master挂了,那么master上的三个服务也就挂了。node挂了,如果node上的pod是被 controller控制住的话,controller会在其他node上启动对应的pod。
K8S部署实战
//pod是最小调度单元,包含了一个业务功能
[root@localhost ~]# kubectl get pods -A
NAMESPACE NAME READY STATUS RESTARTS AGE
//收集主机信息并发送给指定check服务器
default netchecker-agent-n4zvc 1/1 Running 0 5m22s
default netchecker-server-589d76f698-wh8jr 2/2 Running 1 (5m14s ago) 5m20s
//一套开源的网络和网络安全方案
kube-system calico-kube-controllers-75fcdd655b-8khd4 1/1 Running 0 5m36s
kube-system calico-node-mpppj 1/1 Running 0 5m52s
//作为内网的DNS服务器,用于服务发现
kube-system coredns-76b4fb4578-dsj8r 1/1 Running 0 5m29s
kube-system dns-autoscaler-7874cf6bcf-44clw 1/1 Running 0 5m27s
//api
kube-system kube-apiserver-master 1/1 Running 0 6m51s
//通过 apiserver 监控整个集群的状态,并确保集群处于预期的工作状态
kube-system kube-controller-manager-master 1/1 Running 1 6m51s
//实现Kubernetes Service的通信与负载均衡机制
kube-system kube-proxy-488bp 1/1 Running 0 6m4s
//控制面进程,负责将 Pods 指派到节点上
kube-system kube-scheduler-master 1/1 Running 1 6m56s
//监控kubernetes集群资源
kube-system metrics-server-749474f899-8bbrf 1/1 Running 0 5m15s
kube-system nginx-proxy-worker 1/1 Running 0 6m4s
//大幅提升集群内DNS解析性能