
索引
写在前面:索引对查询的速度有着至关重要的影响,理解索引也是进行数据库调优的起点。考虑如下情况,假设数据库中一个表有10^6条记录,DBMS的页面大小为4K,并存储100条记录。如果没有索引,查询将对整个表进行扫描,最坏的情况下,如果所有数据页都不在内存,需要读取10^4个页面,如果这10^4个页面在磁盘上随机分布,需要进行10^4次I/O,假设磁盘每次I/O时间为10ms(忽略数据传输时间),则总共需要100s(但实际上要好很多很多)。如果对之建立B-Tree索引,则只需要进行log100(10^6)=3次页面读取,最坏情况下耗时30ms。这就是索引带来的效果,很多时候,当你的应用程序进行SQL查询速度很慢时,应该想想是否可以建索引。
索引是快速搜索的关键。MySQL索引的建立对于MySQL的高效运行是很重要的。
在数据库表中,对字段建立索引可以大大提高查询速度。假如我们创建了一个 mytable表:
CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL ); 我们随机向里面插入了10000条记录,其中有一条:5555, admin。
在查找username="admin"的记录 SELECT * FROM mytable WHERE username='admin';时,如果在username上已经建立了索引,MySQL无须任何扫描,即准确可找到该记录。相反,MySQL会扫描所有记录,即要查询10000条记录。
索引分单列索引和组合索引。单列索引,即一个索引只包含单个列,一个表可以有多个单列索引,但这不是组合索引。组合索引,即一个索包含多个列。
MySQL索引类型包括:
(1)普通索引
这是最基本的索引,它没有任何限制。
创建索引:
CREATE INDEX indexName ON mytable(username(length));如果是CHAR VARCHAR类型,length可以小于字段实际长度;如果是BLOB和TEXT类型,必须指定 length,下同。
删除索引:
DROP INDEX [indexName] ON mytable;
(2)唯一索引
它与前面的普通索引类似,不同的就是:索引列的值必须唯一,但允许有空值。如果是组合索引,则列值的组合必须唯一。
创建索引:
CREATE UNIQUE INDEX indexName ON mytable(username(length));
(3)主键索引
它是一种特殊的唯一索引,不允许有空值。一般是在建表的时候同时创建主键索引:
CREATE TABLE mytable( ID INT NOT NULL, username VARCHAR(16) NOT NULL, PRIMARY KEY(ID) );
(4)组合索引
https://www.cnblogs.com/vanl/p/5474983.html
https://blog.csdn.net/h2604396739/article/details/84991771
索引在什么情况下会失效
1. 对于创建的多列索引(复合索引),不是使用的第一部分就不会使用索引
alter table student add index my_index(name, age) // name左边的列, age 右边的列
select * from student where name = 'aaa' // 会用到索引
select * from student where age = 18 // 不会使用索引
2. 对于使用 like 查询, 查询如果是 ‘%aaa’ 不会使用索引,而 ‘aaa%’ 会使用到索引。
select * from student where name like 'aaa%' // 会用到索引
select * from student where name like '%aaa' 或者 '_aaa' // 不会使用索引
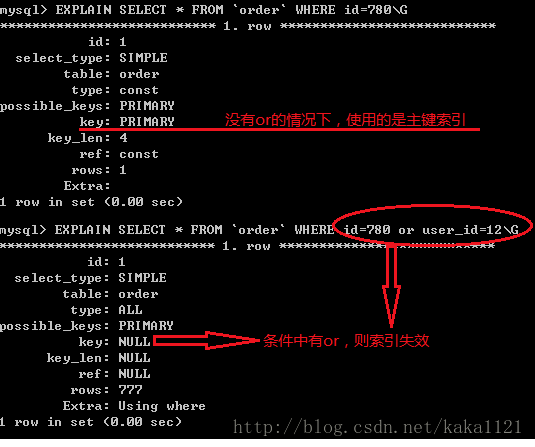
3. 如果条件中有 or, 有条件没有使用索引,即使其中有条件带索引也不会使用,换言之, 就是要求使用的所有字段,都必须单独使用时能使用索引。
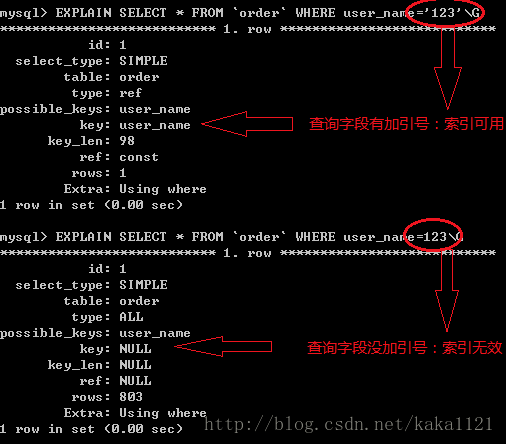
4. 如果列类型是字符串,那么一定要在条件中使用引号引用起来,否则不使用索引。
5. 如果mysql认为全表扫面要比使用索引快,则不使用索引。
如:表里只有一条数据。
6 .where语句中使用了IS NULL或者IS NOT NULL,会造成索引失效
7. 使用了反向操作,该索引将不起作用
8.对列进行计算或者是使用函数,则该列的索引会失效
9.不匹配数据类型,会造成索引失效
什么时没必要用
1.唯一性差;
2.频繁更新的字段不用(更新索引消耗);
3.where中不用的字段;
4.索引使用<>时,效果一般;
详述(转)
索引并不是时时都会生效的,比如以下几种情况,将导致索引失效:
- 如果条件中有or,即使其中有部分条件带索引也不会使用(这也是为什么尽量少用or的原因),例子中user_id无索引
注意:要想使用or,又想让索引生效,只能将or条件中的每个列都加上索引
- 对于复合索引,如果不使用前列,后续列也将无法使用,类电话簿。
- like查询是以%开头

- 存在索引列的数据类型隐形转换,则用不上索引,比如列类型是字符串,那一定要在条件中将数据使用引号引用起来,否则不使用索引
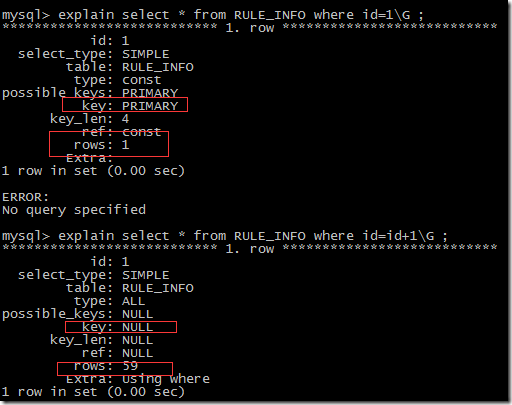
- where 子句里对索引列上有数学运算,用不上索引
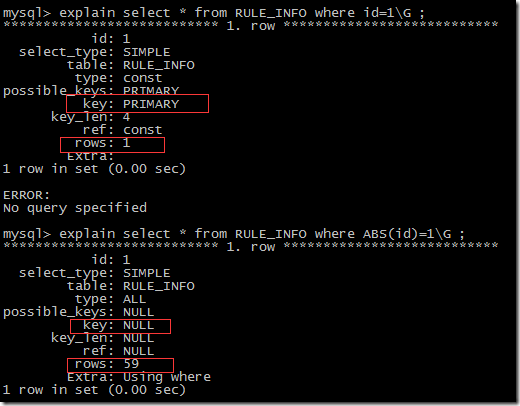
- where 子句里对有索引列使用函数,用不上索引
- 如果mysql估计使用全表扫描要比使用索引快,则不使用索引
比如数据量极少的表
什么情况下不推荐使用索引?
1) 数据唯一性差(一个字段的取值只有几种时)的字段不要使用索引
比如性别,只有两种可能数据。意味着索引的二叉树级别少,多是平级。这样的二叉树查找无异于全表扫描。
2) 频繁更新的字段不要使用索引
比如logincount登录次数,频繁变化导致索引也频繁变化,增大数据库工作量,降低效率。
3) 字段不在where语句出现时不要添加索引,如果where后含IS NULL /IS NOT NULL/ like ‘%输入符%’等条件,不建议使用索引
只有在where语句出现,mysql才会去使用索引
4) where 子句里对索引列使用不等于(<>),使用索引效果一般
什么时候应该建立索引
1.较频繁地作为查询条件的字段
2.连接(join)的字段,经常与其他表进行连接的表,在连接字段上应该建立索引;
3.经常出现在Where子句中的字段,特别是大表的字段,应该建立索引;
4.需要排序的字段
5、索引应该建在选择性高的字段上;
6、索引应该建在小字段上,对于大的文本字段甚至超长字段,不要建索引;
7、复合索引的建立需要进行仔细分析;尽量考虑用单字段索引代替:
A、正确选择复合索引中的主列字段,一般是选择性较好的字段;
B、复合索引的几个字段是否经常同时以AND方式出现在Where子句中?单字段查询是否极少甚至没有?如果是,则可以建立复合索引;否则考虑单字段索引;
C、如果复合索引中包含的字段经常单独出现在Where子句中,则分解为多个单字段索引;
D、如果复合索引所包含的字段超过3个,那么仔细考虑其必要性,考虑减少复合的字段;
E、如果既有单字段索引,又有这几个字段上的复合索引,一般可以删除复合索引;
8、频繁进行数据操作的表,不要建立太多的索引;
9、删除无用的索引,避免对执行计划造成负面影响;
以上是一些普遍的建立索引时的判断依据。一言以蔽之,索引的建立必须慎重,对每个索引的必要性都应该经过仔细分析,要有建立的依据。因为太多的索引与不充分、不正确的索引对性能都毫无益处:在表上建立的每个索引都会增加存储开销,索引对于插入、删除、更新操作也会增加处理上的开销。另外,过多的复合索引,在有单字段索引的情况下,一般都是没有存在价值的;相反,还会降低数据增加删除时的性能,特别是对频繁更新的表来说,负面影响更大。
Mysql中联合索引的最左匹配原则
在Mysql建立多列索引(联合索引)有最左前缀的原则,即最左优先。
如果我们建立了一个2列的联合索引(col1,col2),实际上已经建立了两个联合索引(col1)、(col1,col2);
如果有一个3列索引(col1,col2,col3),实际上已经建立了三个联合索引(col1)、(col1,col2)、(col1,col2,col3)。
解释
1、b+树的数据项是复合的数据结构,比如(name,age,sex)的时候,b+树是按照从左到右的顺序来建立搜索树的,比如当(张三,20,F)这样的数据来检索的时候,b+树会优先比较name来确定下一步的所搜方向,如果name相同再依次比较age和sex,最后得到检索的数据;但当(20,F)这样的没有name的数据来的时候,b+树就不知道第一步该查哪个节点,因为建立搜索树的时候name就是第一个比较因子,必须要先根据name来搜索才能知道下一步去哪里查询。
2、比如当(张三,F)这样的数据来检索时,b+树可以用name来指定搜索方向,但下一个字段age的缺失,所以只能把名字等于张三的数据都找到,然后再匹配性别是F的数据了, 这个是非常重要的性质,即索引的最左匹配特性。(这种情况无法用到联合索引)
mysql里创建联合索引的意义
一个顶三个
建了一个(a,b,c)的复合索引,那么实际等于建了(a),(a,b),(a,b,c)三个索引,因为每多一个索引,都会增加写操作的开销和磁盘空间的开销。对于大量数据的表,这可是不小的开销!
覆盖索引
同样的有复合索引(a,b,c),如果有如下的sql: select a,b,c from table where a=1 and b = 1。那么MySQL可以直接通过遍历索引取得数据,而无需回表,这减少了很多的随机io操作。减少io操作,特别的随机io其实是dba主要的优化策略。所以,在真正的实际应用中,覆盖索引是主要的提升性能的优化手段之一
索引列越多,通过索引筛选出的数据越少
有1000W条数据的表,有如下sql:select * from table where a = 1 and b =2 and c = 3,假设假设每个条件可以筛选出10%的数据,如果只有单值索引,那么通过该索引能筛选出1000W10%=100w 条数据,然后再回表从100w条数据中找到符合b=2 and c= 3的数据,然后再排序,再分页;如果是复合索引,通过索引筛选出1000w 10% 10% 10%=1w,然后再排序、分页,哪个更高效,一眼便知
创建联合索引时列的选择原则
- 经常用的列优先(最左匹配原则)
- 离散度高的列优先(离散度高原则)
- 宽度小的列优先(最少空间原则)
列的离散性计算:count(distinct col)/ count(col)
例如:
id列一共9列都不重复 9/9 = 1
性别列一共9列只有(男或者女)两列 2/9 约等于0.2
离散性越高选择性越大
https://blog.csdn.net/l12345678999/article/details/25500567
https://baijiahao.baidu.com/s?id=1644457975409803649&wfr=spider&for=pc

