

Python定时框架 Apscheduler 详解
1 简介
APScheduler的全称是Advanced Python Scheduler。它是一个轻量级的 Python 定时任务调度框架。同时,它还支持异步执行、后台执行调度任务。本人小小的建议是一般项目用APScheduler,因为不用像Celery那样再单独启动worker、beat进程,而且API也很简洁。
Apscheduler基于Quartz的一个python定时任务框架,实现Quart的所有功能,相关的接口调用起来比较方便,目前其提供了基于日期、固定时间间隔以及corntab类型的任务,并且同时可进行持久化任务;同时它提供了多种不同的调用器,方便开发者根据自己的需求进行使用,也方便与数据库等第三方的外部持久化储存机制进行协同工作,非常强大。
基本原理
总的来说,主要是利用python threading Event和Lock锁来写的。scheduler在主循环(main_loop)中,反复检查是否有需要执行的任务,完成任务的检查函数为 _process_jobs,主要有那个几个步骤:
1、询问储存的每个 jobStore,是否有到期要执行的任务。
@abstractmethod def get_due_jobs(self, now): """ Returns the list of jobs that have ``next_run_time`` earlier or equal to ``now``. The returned jobs must be sorted by next run time (ascending). :param datetime.datetime now: the current (timezone aware) datetime :rtype: list[Job] """

2、due_jobs不为空,则计算这些jobs中每个job需要运行的时间点,时间一到就提交给submit作任务调度。
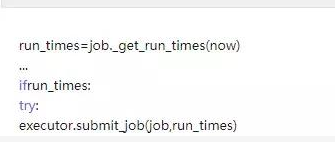
3、在主循环中,如果不间断地调用,而实际上没有要执行的job,这会造成资源浪费。因此在程序中,如果每次掉用 _process_jobs后,进行了预先判断,判断下一次要执行的job(离现在最近的)还要多长时间,作为返回值告诉main_loop, 这时主循环就可以去睡一觉,等大约这么长时间后再唤醒,执行下一次 _process_jobs。
2 使用步骤
APScheduler 使用起来还算是比较简单。运行一个调度任务只需要以下三部曲。
- 新建一个 schedulers (调度器) 。
- 添加一个调度任务(job stores)。
- 运行调度任务。
下面是执行每 2 秒报时的简单示例代码:
import datetime import time from apscheduler.schedulers.background import BackgroundScheduler def timedTask(): print(datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]) if __name__ == '__main__': # 创建后台执行的 schedulers scheduler = BackgroundScheduler() # 添加调度任务 # 调度方法为 timedTask,触发器选择 interval(间隔性),间隔时长为 2 秒 scheduler.add_job(timedTask, 'interval', seconds=2) # 启动调度任务 scheduler.start() while True: print(time.time()) time.sleep(5)
传递参数的方式有元组(tuple)、列表(list)、字典(dict)
注意:不过需要注意采用元组传递参数时后边需要多加一个逗号
#基于list
scheduler.add_job(job2, 'interval', seconds=5, args=['a','b','list'], id='test_job4')
#基于tuple
scheduler.add_job(job2, 'interval', seconds=5, args=('a','b','tuple',), id='test_job5')
#基于dict
scheduler.add_job(job3, 'interval', seconds=5, kwargs={'f':'dict', 'a':1,'b':2}, id='test_job6)
3 基础组件
APScheduler 有四种组件,分别是:调度器(scheduler),作业存储(job store),触发器(trigger),执行器(executor)。
-
schedulers(调度器)
它是任务调度器,属于控制器角色。它配置作业存储器和执行器可以在调度器中完成,例如添加、修改和移除作业。把下面三个组件作为参数,通过创建调度器实例来运行 -
triggers(触发器)
描述调度任务被触发的条件。不过触发器完全是无状态的。 -
job stores(作业存储器)
任务持久化仓库,默认保存任务在内存中,也可将任务保存都各种数据库中,任务中的数据序列化后保存到持久化数据库,从数据库加载后又反序列化。 -
executors(执行器)
负责处理作业的运行,它们通常通过在作业中提交指定的可调用对象到一个线程或者进城池来进行。当作业完成时,执行器将会通知调度器。
3.1 schedulers(调度器)
我个人觉得 APScheduler 非常好用的原因。它提供 7 种调度器,能够满足我们各种场景的需要。例如:后台执行某个操作,异步执行操作等。调度器分别是:
- BlockingScheduler : 调度器在当前进程的主线程中运行,也就是会阻塞当前线程。
- BackgroundScheduler : 调度器在后台线程中运行,不会阻塞当前线程。
- AsyncIOScheduler : 结合
asyncio模块(一个异步框架)一起使用。 - GeventScheduler : 程序中使用
gevent(高性能的Python并发框架)作为IO模型,和GeventExecutor配合使用。 - TornadoScheduler : 程序中使用
Tornado(一个web框架)的IO模型,用ioloop.add_timeout完成定时唤醒。 - TwistedScheduler : 配合
TwistedExecutor,用reactor.callLater完成定时唤醒。 - QtScheduler : 你的应用是一个 Qt 应用,需使用QTimer完成定时唤醒。
负责将上面几个组件联系在一起,一般在应用中只有一个调度器,程序开发者不会直接操作触发器、作业存储或执行器,而是利用调度器提供了处理这些合适的接口,作业存储和执行器的配置都是通过在调度器中完成的。
开发者也不必直接操作任务储存器、执行器以及触发器,因为调度器提供了统一的接口,通过调度器就可以操作组件,比如任务的增删改查。
调度器工作流程:

3.2 triggers(触发器)
某一个工作到来时引发的事件,包含调度的逻辑,每一个作业都有它自己的触发器,用于决定哪个作业任务会执行,除了它们初始化配置之外,其完全是无状态的。总的来说就是一个任务应该在什么时候执行
APScheduler 有三种内建的 trigger:
1)date 触发器
date 是最基本的一种调度,作业任务只会执行一次。它表示特定的时间点触发。它的参数如下:
| 参数 | 说明 |
|---|---|
| run_date (datetime 或 str) | 作业的运行日期或时间 |
| timezone (datetime.tzinfo 或 str) | 指定时区 |
date 触发器使用示例如下:
from datetime import datetime from datetime import date from apscheduler.schedulers.background import BackgroundScheduler def job_func(text): print(text) scheduler = BackgroundScheduler() # 在 2017-12-13 时刻运行一次 job_func 方法 scheduler .add_job(job_func, 'date', run_date=date(2017, 12, 13), args=['text']) # 在 2017-12-13 14:00:00 时刻运行一次 job_func 方法 scheduler .add_job(job_func, 'date', run_date=datetime(2017, 12, 13, 14, 0, 0), args=['text']) # 在 2017-12-13 14:00:01 时刻运行一次 job_func 方法 scheduler .add_job(job_func, 'date', run_date='2017-12-13 14:00:01', args=['text']) scheduler.start()
2)interval 触发器
固定时间间隔触发。即每隔多久执行一次,interval 间隔调度,参数如下:
| 参数 | 说明 |
|---|---|
| weeks (int) | 间隔几周 |
| days (int) | 间隔几天 |
| hours (int) | 间隔几小时 |
| minutes (int) | 间隔几分钟 |
| seconds (int) | 间隔多少秒 |
| start_date (datetime 或 str) | 开始日期 |
| end_date (datetime 或 str) | 结束日期 |
| timezone (datetime.tzinfo 或str) | 时区 |
interval 触发器使用示例如下:
import datetime from apscheduler.schedulers.background import BackgroundScheduler def job_func(): print(datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]) scheduler = BackgroundScheduler() # 每隔两分钟执行一次 job_func 方法 scheduler .add_job(job_func, 'interval', seconds=2) # 在 2017-12-13 14:00:01 ~ 2017-12-13 14:00:10 之间, 每隔两分钟执行一次 job_func 方法 scheduler .add_job(job_func, 'interval', seconds=2, start_date='2017-12-13 14:00:01' , end_date='2017-12-13 14:00:10') scheduler.start()
3)cron 触发器
在特定时间周期性地触发,定时任务(即规定在某一时刻执行)和Linux crontab格式兼容。它是功能最强大的触发器。
我们先了解 cron 参数:
| 参数 | 说明 |
|---|---|
| year (int 或 str) | 年,4位数字 |
| month (int 或 str) | 月 (范围1-12) |
| day (int 或 str) | 日 (范围1-31 |
| week (int 或 str) | 周 (范围1-53) |
| day_of_week (int 或 str) | 周内第几天或者星期几 (范围0-6 或者 mon,tue,wed,thu,fri,sat,sun) |
| hour (int 或 str) | 时 (范围0-23) |
| minute (int 或 str) | 分 (范围0-59) |
| second (int 或 str) | 秒 (范围0-59) |
| start_date (datetime 或 str) | 最早开始日期(包含) |
| end_date (datetime 或 str) | 最晚结束时间(包含) |
| timezone (datetime.tzinfo 或str) | 指定时区 |
这些参数是支持算数表达式,取值格式有如下:

cron 触发器使用示例如下:
# job_function将会在6,7,8,11,12月的第3个周五的1,2,3点运行 sched.add_job(job_function, 'cron', month='6-8,11-12', day='3rd fri', hour='0-3') # 截止到2016-12-30 00:00:00,每周一到周五早上五点半运行job_function sched.add_job(job_function, 'cron', day_of_week='mon-fri', hour=5, minute=30, end_date='2016-12-31')
import datetime from apscheduler.schedulers.background import BackgroundScheduler def job_func(): print("当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]) scheduler = BackgroundScheduler() # 在每年 1-3、7-9 月份中的每个星期一、二中的 00:00, 01:00, 02:00 和 03:00 执行 job_func 任务 scheduler .add_job(job_func, 'cron', month='1-3,7-9',day='1-31', hour='0-23',minute= '1-59',second = '1-59') scheduler.start() while True: pass
3.3 作业存储(job store)
该组件是对调度任务的管理。保存要调度的任务,其中除了默认的作业存储是把作业保存在内存中,其他的作业存储是将作业保存在数据库中。一个作业的数据将在保存在持久化的作业存储之前,会对作业执行序列化操作,当重新读取作业时,再执行反序列化操作。同时,调度器不能分享同一个作业存储。作业存储支持主流的存储机制:如redis,mongodb,关系型数据库,内存等等。
1)添加 job
有两种添加方法,其中一种上述代码用到的 add_job(), 另一种则是scheduled_job()修饰器来修饰函数。
这个两种办法的区别是:第一种方法返回一个 apscheduler.job.Job 的实例,可以用来改变或者移除 job。第二种方法只适用于应用运行期间不会改变的 job。
第二种添加任务方式的例子:
import datetime from apscheduler.schedulers.background import BlockingScheduler scheduler = BlockingScheduler() @scheduler.scheduled_job( 'interval', seconds=2) def job_func(): print(datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]) scheduler.start()
import datetime from apscheduler.schedulers.blocking import BlockingScheduler from app.untils.log_builder import sys_logging scheduler = BlockingScheduler() # 后台运行 # 设置为每日凌晨00:30:30时执行一次调度程序 @scheduler.scheduled_job("cron", day_of_week='*', hour='1', minute='30', second='30') def rebate(): print "schedule execute" sys_logging.debug("statistic scheduler execute success" + datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")) if __name__ == '__main__': try: scheduler.start() sys_logging.debug("statistic scheduler start success") except (KeyboardInterrupt, SystemExit): scheduler.shutdown() sys_logging.debug("statistic scheduler start-up fail")
移除 job 也有两种方法:
remove_job() 和 job.remove()。remove_job() 是根据 job 的 id 来移除,所以要在 job 创建的时候指定一个 id。
job.remove() 则是对 job 执行 remove 方法即可
import datetime from apscheduler.schedulers.background import BlockingScheduler scheduler = BlockingScheduler() def job_func(): print("当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]) # scheduler.add_job(job_func, 'interval', seconds=2, id='job_one') # scheduler.remove_job('job_one') job = scheduler.add_job(job_func, 'interval', seconds=2, id='job_one',name='test_job') job.remove() scheduler.start()
3).获得任务列表:
可以通过get_jobs方法来获取当前的任务列表,也可以通过get_job()来根据job_id来获得某个任务的信息。并且apscheduler还提供了一个print_jobs()方法来打印格式化的任务列表。
import datetime from apscheduler.schedulers.background import BlockingScheduler scheduler = BlockingScheduler() def job_func(): print("当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]) job = scheduler.add_job(job_func, 'interval', seconds=2, id='job_one') job = scheduler.add_job(job_func, 'interval', seconds=2, id='job_two') print scheduler.get_job('job_one') print scheduler.get_jobs() scheduler.start()
4).修改 job:
如果你因计划改变要对 job 进行修改,可以使用Job.modify() 或者 modify_job()方法来修改除id以外的任何作业属性。
job.modify(max_instances=6, name='Alternate name')
import datetime from apscheduler.schedulers.background import BlockingScheduler scheduler = BlockingScheduler() def job_func(): print("当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]) scheduler.add_job(job_func, 'interval', seconds=2, id='job_one',name= 'ljt') temp_dict = {"seconds":3} temp_trigger = scheduler._create_trigger(trigger='interval',trigger_args=temp_dict) result = scheduler.modify_job(job_id='job_one',trigger=temp_trigger) scheduler.start()
5).暂停与恢复任务:
暂停与恢复任务可以直接操作任务实例或者调度器来实现。当任务暂停时,它的运行时间会被重置,暂停期间不会计算时间。
import datetime import time from apscheduler.schedulers.background import BackgroundScheduler scheduler = BackgroundScheduler()#非阻塞,后台运行 def job_func(): print("当前时间:", datetime.datetime.utcnow().strftime("%Y-%m-%d %H:%M:%S.%f")[:-3]) job = scheduler.add_job(job_func, 'interval', seconds=1, id='job_one',name= 'ljt') scheduler.start() while True: time.sleep(3) scheduler.pause_job('job_one') time.sleep(1) job.resume()#或者下面,等价 scheduler.resume_job('job_one')
6).启动调度器
可以使用start()方法启动调度器,BlockingScheduler需要在初始化之后才能执行start(),对于其他的Scheduler,调用start()方法都会直接返回,然后可以继续执行后面的初始化操作。
例如:
from apscheduler.schedulers.blocking import BlockingScheduler def my_job(): print "Hello world!" scheduler = BlockingScheduler() scheduler.add_job(my_job, 'interval', seconds=1) scheduler.start()
7).关闭调度器:
使用下边方法关闭调度器:
scheduler.shutdown()
默认情况下调度器会关闭它的任务存储和执行器,并等待所有正在执行的任务完成,如果不想等待,可以进行如下操作:
scheduler.shutdown(wait=False)
3.4 执行器(executor)
执行器顾名思义是执行调度任务的模块。最常用的 executor 有两种:ProcessPoolExecutor 和 ThreadPoolExecutor
主要是处理作业的运行,它将要执行的作业放在新的线程或者线程池中运行。执行完毕之后,再通知调度器。基于线程池的操作,可以针对不同类型的作业任务,更为高效的使用CPU的计算资源。
大多数情况下,执行器选择ThreadPoolExecutor就够用了,但如果涉及到比较消耗CPU的作业,就可以选择ProcessPoolExecutor* ,以充分利用多核CPU。
当然也可以同时配置使用两个执行器,将进程池ProcessPoolExecutor调度器作为你的第二个执行器。
下面是显式设置 job store(使用mongo存储)和 executor 的代码的示例。
第一种方式:
from pymongo import MongoClient from apscheduler.schedulers.blocking import BlockingScheduler from apscheduler.jobstores.mongodb import MongoDBJobStore from apscheduler.jobstores.memory import MemoryJobStore from apscheduler.executors.pool import ThreadPoolExecutor, ProcessPoolExecutor import time def my_job(): print int(time.time()) host = '127.0.0.1' port = 27017 client = MongoClient(host, port) jobstores = { 'mongo': MongoDBJobStore(collection='job', database='test', client=client), 'default': MemoryJobStore() } executors = { 'default': ThreadPoolExecutor(10), 'processpool': ProcessPoolExecutor(3) } job_defaults = { 'coalesce': False, 'max_instances': 3 } scheduler = BlockingScheduler(jobstores=jobstores, executors=executors, job_defaults=job_defaults) scheduler.add_job(my_job, 'interval', seconds=1) try: scheduler.start() except SystemExit: client.close()
- coalesce:当由于某种原因导致某个job积攒了好几次没有实际运行(比如说系统挂了5分钟后恢复,有一个任务是每分钟跑一次的,按道理说这5分钟内本来是“计划”运行5次的,但实际没有执行),如果coalesce为True,下次这个job被submit给executor时,只会执行1次,也就是最后这次,如果为False,那么会执行5次(不一定,因为还有其他条件,看后面misfiregracetime的解释)。
- max_instance:每个job在同一时刻能够运行的最大实例数,默认情况下为1个,可以指定为更大值,这样即使上个job还没运行完同一个job又被调度的话也能够再开一个线程执行。(限制同一个job实例的并发执行数)
- misfire_grace_time:单位为秒,假设有这么一种情况,当某一job被调度时刚好线程池都被占满,调度器会选择将该job排队不运行,misfiregracetime参数则是在线程池有可用线程时会比对该job的应调度时间跟当前时间的差值,如果差值<misfiregracetime时,调度器会再次调度该job.反之该job的执行状态为EVENTJOBMISSED了,即错过运行.</misfire。
-
作业被添加到数据库中,程序中断后重新运行时会自动从数据库读取作业信息,而不需要重新再添加到调度器中,如果不注释 21-25 行添加作业的代码,则作业会重新添加到数据库中,这样就有了两个同样的作业,避免出现这种情况可以在 add_job 的参数中增加 replace_existing=True,如scheduler.add_job(my_job, args=['job_interval',],id='job_interval',trigger='interval',seconds=3,replace_existing=True)
-
还有一点要注意,如果你的执行器或任务储存器是会序列化任务的,那么这些任务就必须符合:
-
回调函数必须全局可用
-
回调函数参数必须也是可以被序列化的
重要提醒!
如果在程序初始化时,是从数据库读取任务的,那么必须为每个任务定义一个明确的ID,并且使用replace_existing=True,否则每次重启程序,你都会得到一份新的任务拷贝,也就意味着任务的状态不会保存。
内置任务储存器中,只有MemoryJobStore不会序列化任务;内置执行器中,只有ProcessPoolExecutor会序列化任务。
建议:如果想要立刻运行任务,可以在添加任务时省略trigger参数
-
#持久化默认在内存中,monogo数据库中只会生成一个test的数据库job(collection)的值为空,程序最终只用了default的值。
如果需要持久化在monogo中jobstores改为'default': MongoDBJobStore(collection = 'job', database = 'test', client = client)。
再次重启程序时,程序会从数据库中直接读取任务,可以不用重复添加任务。

第二种方式:
from apscheduler.schedulers.background import BackgroundScheduler scheduler = BackgroundScheduler({ 'apscheduler.jobstores.mongo': { 'type': 'mongodb' }, 'apscheduler.jobstores.default': { 'type': 'sqlalchemy', 'url': 'sqlite:///jobs.sqlite' }, 'apscheduler.executors.default': { 'class': 'apscheduler.executors.pool:ThreadPoolExecutor', 'max_workers': '20' }, 'apscheduler.executors.processpool': { 'type': 'processpool', 'max_workers': '5' }, 'apscheduler.job_defaults.coalesce': 'false', 'apscheduler.job_defaults.max_instances': '3', 'apscheduler.timezone': 'UTC', })
第三种方式:
from pytz import utc from apscheduler.schedulers.background import BackgroundScheduler from apscheduler.jobstores.sqlalchemy import SQLAlchemyJobStore from apscheduler.executors.pool import ProcessPoolExecutor jobstores = { 'mongo': {'type': 'mongodb'}, 'default': SQLAlchemyJobStore(url='sqlite:///jobs.sqlite') } executors = { 'default': {'type': 'threadpool', 'max_workers': 20}, 'processpool': ProcessPoolExecutor(max_workers=5) } job_defaults = { 'coalesce': False, 'max_instances': 3 } scheduler = BackgroundScheduler() scheduler.configure(jobstores=jobstores, executors=executors,job_defaults=job_defaults, timezone=utc)
调度器监听事件
可以给调度器添加事件监听器,调度器事件只有在某些情况下才会被触发,并且可以携带某些有用的信息。通过给 add_listener()传递合适的 mask参数,可以只监听几种特定的事件类型,具体类型可看源码中的 event.exception或者 event.code值来做识别判断。
from apscheduler.schedulers.background import BackgroundScheduler from apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERROR,EVENT_JOB_ADDED import time def task_listener(event): if event.code == EVENT_JOB_EXECUTED: print '任务执行成功' if event.code == EVENT_JOB_ADDED: print '任务添加成功' if event.code == EVENT_JOB_ERROR: print '任务执行错误' def my_job(): print "Hello world!" print 1/0 scheduler = BackgroundScheduler() scheduler.add_listener(task_listener, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR | EVENT_JOB_ADDED) job = scheduler.add_job(my_job, 'interval', seconds=1) scheduler.start() while True: time.sleep(3) job = scheduler.add_job(my_job, 'interval', seconds=1)
from apscheduler.schedulers.background import BackgroundScheduler from apscheduler.events import EVENT_JOB_EXECUTED, EVENT_JOB_ERROR import datetime import logging import time logging.basicConfig(level=logging.INFO, format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s', datefmt='%Y-%m-%d %H:%M:%S', filename='log1.txt', filemode='a') def aps_test(x): print (datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), x) def date_test(x): print(datetime.datetime.now().strftime('%Y-%m-%d %H:%M:%S'), x) print (1 / 0) def my_listener(event): #定义一个事件监听,出现意外情况打印相关信息报警。 if event.exception: print ('任务出错了!!!!!!') else: print ('任务照常运行...') scheduler = BackgroundScheduler() scheduler.add_job(func=date_test, args=('一次性任务,会出错',),next_run_time=datetime.datetime.now() + datetime.timedelta(seconds=15), id='date_task') scheduler.add_job(func=aps_test, args=('循环任务',), trigger='interval', seconds=3, id='interval_task') scheduler.add_listener(my_listener, EVENT_JOB_EXECUTED | EVENT_JOB_ERROR) scheduler._logger = logging #启用 scheduler 模块的日记记录 scheduler.start() while True: time.sleep(3)
在生产环境中,可以把出错信息换成发送一封邮件或者发送一个短信,这样定时任务出错就可以立马就知道。
第一次使用此定时器时总会执行两次,一直不知道为什么,后来发现,python 的flask框架在debug模式下会多开一个线程监测项目变化,所以每次会跑两遍,可以将debug选项改为False
注意:
当出现No handlers could be found for logger “apscheduler.scheduler”次错误信息时,说明没有 logging模块的logger存在,所以需要添加上,对应新增内容如下所示(仅供参):
import logging
logging.basicConfig(
level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s',
datafmt='%a, %d %b %Y %H:%M:%S',
filename='/var/log/aaa.txt',
filemode='a'
)
总结:
APScheduler在实际使用过程中拥有最大的灵活性,可以满足我们的大部分定时任务的相关需求;Celery比较重量级,通常如果项目中已有Celery在使用,而且不需要动态添加定时任务时可以考虑使用;schedule非常轻量级,使用简单,但是不支持任务的持久化,也无法动态添加删除任务,所以主要用于简单的小型应用。
https://www.jianshu.com/p/ad2c42245906

