
为什么要分库分表
-
前言
其实分库分表是牵扯到高并发的,因为分库分表无非来说就是为了支撑高并发、数据量大的问题。尤其进入稍微大一点的公司或者互联网公司,这些都是必须掌握!
-
场景
假如一个新兴公司,刚开始时,注册用户就40W,每天活跃1W,每天单表数据量1000,高峰期每秒的并发就10,这种一般的单表单库操作就可以搞定。
但是,当用户不断增加、日活跃用户增加、单表数据量增加、高峰期每秒增加到一定数量时,单表单库性能就存在很大的问题了。
-
解决办法-->分表
前提:当单表数据量太大,会极大的影响sql的执行性能,这时sql会跑的很慢。根据实战经验来说,当单表到几百万的时候,性能就会有所下降
个人理解:白话来说就是把一个表的数据放到多个表中,查就查一个表,可以按照id来分表控制每个表的数据量,比如单表固定在200W以内。
-
解决办法-->分库
个人理解:单库而言,最大的并发可能就2000左右,但是一个健壮的单库来说最好的并发保持在1000左右。单数据库增大或者并发增加的时候,可以将一个库的数据拆分到多个库中。
-
分库分表图表理解
| 分库分表前 | 分库分表后 | |
| 并发情况 | Mysql单机,支撑不了高并发 | Mysql集群,并发加倍 |
| 磁盘情况 | 磁盘容量几乎撑满 | 拆分多个表,磁盘使用率降低 |
| SQL性能 | 数据量加大,SQL越来越慢 | 单表数据量少,SQL效率提升明显 |
- 目前常用的分库分表中间件
sharding-jdbc:当当开源,属于client层,SQL语法支持比较多,支持分库分表、读写分离、分布式id生成、柔性事务(最大努力送达型事务、TCC事务),一直在维护,社区也比较活跃
mycat:基于proxy层方案,属于目前非常火且不断更新的数据库中间件,支持功能也非常完善
区别和选择:
sharding-jdbc这种client层优点是不用部署,运维成本低,不需要代理层的二次转发请求,性能很高,但是一旦升级,需要各个系统都重新升级版本在发布,各个系统都需要耦合sharding-jdbc的依赖。
mycat这种proxy层的方案缺点就是自己运维一套中间件,运维成本高,但是好处在于对于各个项目透明,如果升级都是在中间件那里搞定就可以了。
通常来说,小公司小项目建议使用sharding-jdbc,维护成本低,而大公司使用mycat这种proxy方案,大公司系统和项目多,有专人维护。
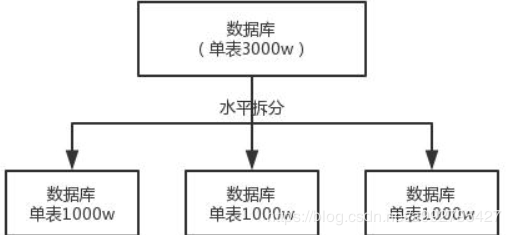
就是把一个表的数据分到多个库的多个表中,每个库的表结构一样,不过每个库存放的数据不同。水平拆分的意思就是将数据均匀放到更多表里,然后多个库来抗高并发,还有就是用多个库的存储容量来扩容
- 数据库水平拆分
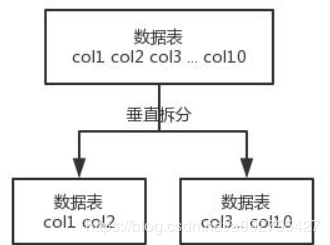
- 数据库垂直拆分
就是把一个很多字段的表拆分给多个表,或者多个库上去。每个库表结构都不一样,每个库表都包含部分字段。一般来说,会将很少访问的字段放到一个表,数据库有缓存,访问频率高的字段越少,可以缓存更多的行,性能更好,这个一般在表层面操作。
- 如何来拆分
其实大家可能都遇到到,比如说把一个订单大表拆开,订单表、订单支付表、订单商品表。
一种是按照range来分,每个库一段连续的数据,比如按时间来,但比较少用,比如大量流量产生大量数据。
一种是按照某个字段hash均匀分散,这个较常用
分表解决的问题
分表后,单表的并发能力提高了,磁盘I/O性能也提高了,写操作效率提高了
- 查询一次的时间短了
- 数据分布在不同的文件,磁盘I/O性能提高
- 读写锁影响的数据量变小
- 插入数据库需要重新建立索引的数据减少
分表的实现方式(复杂)
需要业务系统配合迁移升级,工作量较大
数据库中间件
数据库中间件分为两种,proxy和客户端式架构。proxy模式有MyCat、DBProxy等,客户端式架构有TDDL、Sharding-JDBC等。那么proxy和客户端式架构有何区别呢?各自有什么优缺点呢?其实看一张图便可知晓。
proxy模式的话我们的select和update语句都是发送给代理,由这个代理来操作具体的底层数据库。所以必须要求代理本身需要保证高可用,否则数据库没有宕机,proxy挂了,那就走远了。
客户端模式通常在连接池上做了一层封装,内部与不同的库连接,sql交给smart-client进行处理。通常仅支持一种语言,如果其他语言要使用,需要开发多语言客户端。
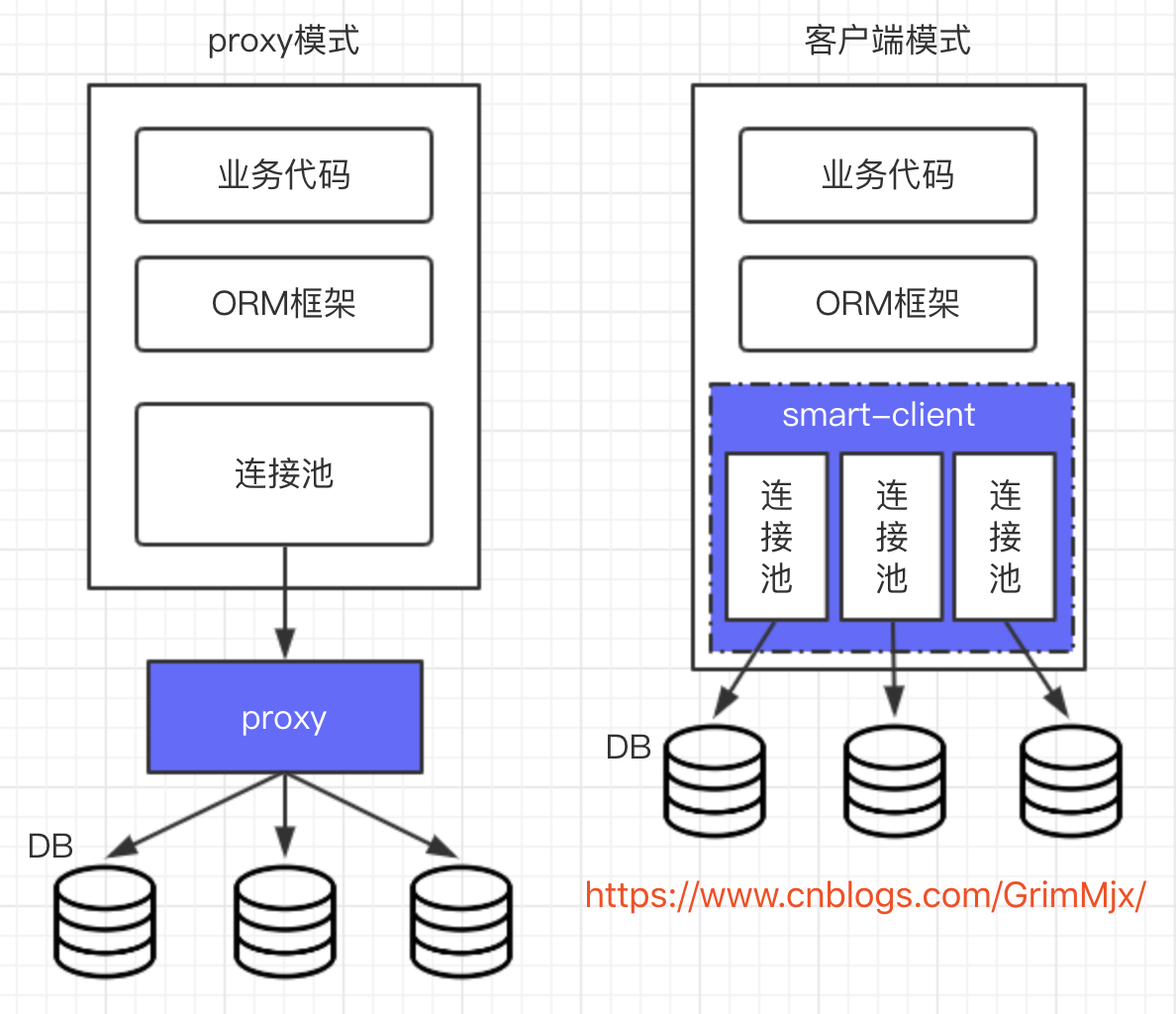
各自的优缺点如下:

3.4 问题
3.4.1 事务问题
既然分库分表了,那么肯定涉及到分布式事务,如何保证插入到不同库的多条记录能够要么同时成功,要么同时失败。有些同学可能想到XA,XA性能差而且不需要使用mysql5.7。柔性事务是目前主流的方案,TCC模式就属于柔性事务。
对于分布式事务问题每家公司有自己的实现,华为用saga,阿里用TXC,蚂蚁用DTX,支持FMT模式和TCC模式。

3.4.2 join问题
tddl、MyCAT等都支持跨分片join。但是尽力避免跨库join,比如通过字段冗余的方式等。
如果出现了这种情况且中间件支持分片join,那么可以这样使用。如果不支持可以手工查询。
六.总结
分表和在用途上不一样,分表是为了承接超大规模的表,单机放不下那种(如果并发量不大,只是查找耗时,当然分表也可以放在单机里)。分区的话则一般都是放在单机里的,用的比较多的是时间范围分区,方便归档。性能稳定上的话都是一个个子表,差不多,区别应该是分区表是mysql内部实现的,会比分表方案少一点数据交互
mysql的水平分表和垂直分表的区别
1,水平分割:
例:QQ的登录表。假设QQ的用户有100亿,如果只有一张表,每个用户登录的时候数据库都要从这100亿中查找,会很慢很慢。如果将这一张表分成100份,每张表有1亿条,就小了很多,比如qq0,qq1,qq1...qq99表。
用户登录的时候,可以将用户的id%100,那么会得到0-99的数,查询表的时候,将表名qq跟取模的数连接起来,就构建了表名。比如123456789用户,取模的89,那么就到qq89表查询,查询的时间将会大大缩短。
这就是水平分割。
2,垂直分割:
垂直分割指的是:表的记录并不多,但是字段却很长,表占用空间很大,检索表的时候需要执行大量的IO,严重降低了性能。这时需要把大的字段拆分到另一个表,并且该表与原表是一对一的关系。
例如学生答题表tt:有如下字段:
Id name 分数 题目 回答
其中题目和回答是比较大的字段,id name 分数比较小。
如果我们只想查询id为8的学生的分数:select 分数 from tt where id = 8;虽然知识查询分数,但是题目和回答这两个大字段也是要被扫描的,很消耗性能。但是我们只关心分数,并不想查询题目和回答。这就可以使用垂直分割。我们可以把题目单独放到一张表中,通过id与tt表建立一对一的关系,同样将回答单独放到一张表中。这样我们插叙tt中的分数的时候就不会扫描题目和回答了。
3,其他要点:
1)存放图片、文件等大文件用文件系统存储。数据库只存储路径,图片和文件存放在文件系统,甚至单独存放在一台服务器(图床)。
2)数据参数配置。
最重要的参数就是内存,我们主要用的innodb引擎,所以下面两个参数调的很大:
innodb_additional_mem_pool_size=64M
innodb_buffer_pool_size=1G
对于MyISAM,需要调整key_buffer_size,当然调整参数还是要看状态,用show status语句可以看到当前状态,以决定该调整哪些参数。
4,合理的硬件资源和操作系统
如果机器的内存超过4G,那么应当采用64位操作系统和64位MySQL。
案例:
简单购物系统暂设涉及如下表:
1.产品表(数据量10w,稳定)
2.订单表(数据量200w,且有增长趋势)
3.用户表 (数据量100w,且有增长趋势)
以mysql为例讲述下水平拆分和垂直拆分,mysql能容忍的数量级在百万静态数据可以到千万
垂直拆分:
解决问题:
- 表与表之间的io竞争
不解决问题:
- 单表中数据量增长出现的压力
方案:
把产品表和用户表放到一个server上
订单表单独放到一个server上
水平拆分:
解决问题:
- 单表中数据量增长出现的压力
不解决问题:
- 表与表之间的io争夺
方案:
用户表通过性别拆分为男用户表和女用户表
订单表通过已完成和完成中拆分为已完成订单和未完成订单
产品表 未完成订单放一个server上
已完成订单表盒男用户表放一个server上
女用户表放一个server上

